데이터베이스 - SQL
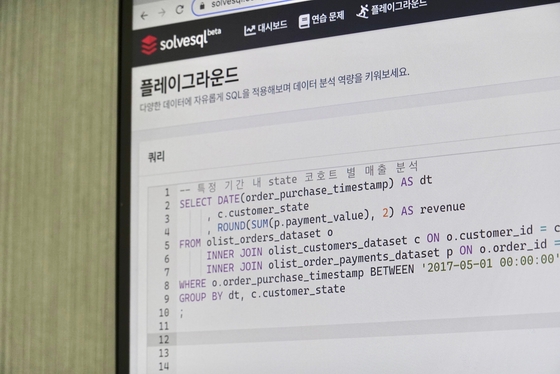
데이터 조작어 DML(Data Manipulate Language) SELECT 쿼리 SELECT * FROM 테이블; SELECT id, name, FROM student; WHERE 조건절 >, >=, =, <=, <, <> SELECT * FROM 테이블 t WHERE t.id = 1; <> 은 같지 않은 것. != 와 같음 IN, NOT IN WHERE t.id in (1, 2, 3, 4) | WHERE t.id not in (1, 2, 3, 4) LIKE WHERE t.name LIKE '%김'; LIKE와 함께 사용하는 와일드 문자 + 문자열 연결 % 포함 관계 %을 문자열 앞에 붙이면 필드값이 제공된 문자열로 시작하는 데이터 탐색. % 끝에 붙이면 끝나는 문자열 탐색. % 앞 뒤에 붙이면 포함하는 문자열 탐색. [] 일치, [^] 불일치 -> '[0-5]%' _ 특정 위치 '_e%' : 두 번째가 문자가 'e'인 문자 ex) test, seller, ... WHERE t.address IS NULL | WHERE t.address IS NOT NULL WHERE t.date BETWEEN '2022-01-01' AND '2022-12-31' 복합조건 사용 가능 - AND, OR, NOT 중복제거 SELECT DISTINCT ORDER BY 필드명 방향[DESC, ASC] ORDER BY price DESC, publisher ASC; GROUP BY 집계함수 - SUM, AVG, MIN, MAX, COUNT GROUP BY 기준필드명 Orders 테이블 GROUP BY customer -> 주문내역을 고객별로 묶음 Likes 테이블 GROUP BY board_id -> 좋아요를 게시글별로 묶음 group by 사용할 경우, select 절에서 기준필드와 집계함수만 출력 가능! 일대다 테이블 조인 관계에서 group by 사용한 예시 기준이 board임으로 board 테이블 필드들 출력 가능 select b.id, b.title, b.content, count(*) as '등록 인원'from board b join registration r on b.id = r.board_idgroup by b.id; HAVING 절 GROUP BY절의 조건절. 집계함수와 함께 사용함. GROUP BY로 묶은 데이터 개수가 10개 이상인 데이터만 출력. HAVING count(*) >= 10 조인(Join) FROM 절에 조인하고자 하는 테이블들을 명시한 후 WHERE 조건절에서 필드를 매치. JOIN(== INNER JOIN) 테이블 1 JOIN 테이블 2 ON 조인조건 데이터가 있는 경우만 데이터를 가져온다. (교집합) 외부조인 - NULL 데이터가 출력될 수 있다. 테이블 1 LEFT OUTER JOIN 테이블 2 ON 조인조건 테이블 1을 기준으로 조인. 테이블 1의 모든 데이터를 기준으로 출력하기에 조인조건에 맞는 테이블 2의 데이터가 없는 경우 테이블 2의 데이터는 Null로 출력. 테이블 1 RIGHT OUTER JOIN 테이블 2 ON 조인조건 테이블 2를 기준으로 조인. UNION (합집합) select 문 UNION select 문 UNION ALL 을 사용할 경우, 중복 데이터까지 모두 출력 WHERE OR 조건과 같은 결과를 출력하지만 OR 조건은 모든 필드를 합쳐서 출력하고 UNION은 별도의 두 테이블을 상하로 합쳐 결과를 반환한다. 부속질의(SubQuery) - 조인과 달리 모든 데이터를 합치지 않고 필요한 데이터만 찾음 select 절 중심 테이블의 데이터가 출력될 때마다 select 절이 매번 호출된다는 단점이 있다. update orders set bookname = (select name from book where book.id = orders.book_id) from 절 조건에 맞는 데이터만을 모아서 하나의 테이블처럼 활용할 수 있음 where 절 출력이 필요없고 조건절에만 필요할 때 유용. 같은 테이블 집계함수와 비교할 때 유용. select price from orders where price > select avg(price) from orders 테이블 2의 가장 최신 날짜보다 빠른 날짜를 가진 테이블 1의 데이터들 select * from 테이블 t1 where t1.date > (select max(t2.date) from 테이블 t2) EXISTS WHERE EXISTS + (SELECT 문) 데이터의 존재를 확인하기에 존재 확인 용도라면 EXISTS의 성능이 IN 쿼리보다 좋다. LIMIT 출력할 데이터의 개수를 지정. select절 + limit 시작위치, 개수 INSERT문 INSERT INTO 테이블(필드, ...) VALUES(값, ...); INSERT INTO 테이블 SELECT문 가능 UPDATE문 UPDATE 테이블 SET 필드 = 수정할 값 [WHERE 조건절]; SET절에서 SELECT문 사용 가능. 같은 테이블에서는 SELECT문 불가 조건에 해당하는 데이터 수정. 조건 없을 경우 모든 데이터 업데이트. DELETE문 DELETE FROM 테이블 [WHERE 조건절]; 조건에 해당하는 데이터 삭제. 조건 없을 경우 모든 데이터 삭제 == 빈 테이블. 데이터 정의어 DDL(Data Definition Language) CREATE DATABASE [데이터베이스명]; USE [데이터베이스명]; SHOW DATABASES; SHOW TABLES; CREATE TABLE 테이블명( 필드명 필드타입, 필드명 필드타입 제약조건... ); 필드타입 BIGINT, INTEGER, VARCHAR(255), BOOLEAN, DATE ... 제약조건 NOT NULL, UNIQUE, DEFAULT, CHECK (조건절), PRIMARY KEY ... 기본키 필드명 필드타입 PRIMARY KEY 또는 필드 정의한 후 PRIMARY KEY (필드명) 라인을 추가하여 설정 외래키 필드 정의 후에 FOREIGN KEY (필드명) REFERENCES 테이블명(테이블 pk 필드명); 뒤에 ON DELETE [ CASCADE | SET NULL ] 를 통해참조 테이블 데이터 삭제 시 함께 삭제할 것인지 외래키 값을 NULL로 변경할 것인지 설정 ALTER TABLE 필드 추가 ALTER TABLE 테이블 ADD 필드명 필드타입 ... 필드 수정 ALTER TABLE 테이블 MODIFY 필드명 필드타입... 필드 삭제 ALTER TABLE 테이블 DROP COLUMN 필드명; 필드 기본키 설정 ALTER TABLE 테이블 ADD PRIMARY KEY(필드명); 필드 외래키 설정 ALTER TABLE 테이블 ADD [제약조건명] FOREIGN KEY(필드명) REFERENCES 참조테이블(참조필드); DROP TABEL 테이블명 -> 테이블 삭제(테이블의 모든 데이터와 테이블 구조 삭제) 데이터 제어어 DCL(Data Control Language) GRANT ALL PRIVILEGES ON DB명.Table명 TO 사용자@호스트 IDENTIFIED BY '비밀번호'; FLUSH PRIVILEGES; REVOKE ALL ON DB명.Table명 TO 사용자@호스트; ALL | INSERT, UPDATE, CREATE ... GRANT ... ON *.* TO id@'%'; COMMIT, ROLLBACK 내장함수 숫자 ABS 절대값, ROUND 반올림 문자열 CONCAT 문자열 합치기, LOWER, UPPER, LPAD, RPAD 대체, LTRIM, RTRIM 삭제 REPLACE, REVERSE, SUBSTR LENGTH 날짜, 시간 ADDDATE, DATE, DATEDIFF, DATE_FORMAT, STR_TO_DATE, SYSDATE NULL IFNULL, NULLIF, ISNULL