[인프런 워밍업 클럽 스터디] 7일차 - Spring Data JPA를 사용한 데이터베이스

Section 4. 생애 최초 JPA 사용하기
[목표]
문자열 SQL을 직접 사용하는 것의 한계를 이해하고, 해결책인 JPA, Hibernate, Spring Data JPA가 무엇인지 이해한다.
Spring Data JPA를 이용해 데이터를 생성, 조회, 수정, 삭제할 수 있다.
트랜잭션이 왜 필요한지 이해하고, 스프링에서 트랜잭션을 제어하는 방법을 익힌다.
영속성 컨텍스트와 트랜잭션의 관계를 이해하고, 영속성 컨텍스트의 특징을 알아본다.
[SQL을 직접 작성하면 아쉬운 점]
문자열을 작성하기 때문에 실수할 수 있고, 실수를 인지하는 시점이 느리다.
특정 데이터베이스에 종속적이게 된다.
반복 작업이 많아진다. 테이블을 하나 만들 때 마다 CRUD 쿼리가 항상 필요하다.
데이터베이스의 테이블과 객체는 패러다임이 다르다.
===> 그렇기 때문에 등장한 것이 JPA(Java Persistence API)
[JPA란?]
객체와 관계형 DB의 테이블을 짝지어 데이터를 영구적으로 저장할 수 있도록 정해진 Java 진영의 규칙
이것을 코드로 구현한 것이 Hibernate. Hibernate는 JDBC를 내부적으로 사용한다.
[JPA 어노테이션]
@Entity : 스프링이 User 객체와 user 테이블을 같은 것으로 바라본다. 기본생성자 꼭 필요함.
@Id : 이 필드를 primary key로 간주한다.
@GeneratedValue : primary key는 자동 생성되는 값이다.
@Column : 객체의 필드와 Table의 필드를 매핑한다. 이름이 같을 시 생략 가능.
[spring.jpa.hibernate.ddl-auto]
create: 기존 테이블이 있다면 삭제 후 다시 생성
create-drop: 스프링이 종료될 때 테이블을 모두 제거
update: 객체와 테이블이 다른 부분만 변경
validate: 객체와 테이블이 동일한지 확인
none: 별다른 조치를 하지 않는다
[지금까지 사용한 JPA Repository 기능]
save: 주어지는 객체를 저장하거나 업데이트 시켜준다.
findAll: 주어지는 객체가 매핑된 테이블의 모든 데이터를 가져온다.
findById: id를 기준으로 특정한 1개의 데이터를 가져온다.
[Spring Data JPA]
복잡한 JPA 코드를 스프링과 함께 쉽게 사용할 수 있도록 도와주는 라이브러리
[JPA Repository에서 By 앞에 들어갈 수 있는 구절 정리]
find: 1건을 가져온다. 반환 타입은 객체가 될 수도 있고, Optional<타입>이 될 수도 있다.
findAll: 쿼리의 결과물이 N개인 경우 사용. List<타입> 반환.
exists: 쿼리 결과가 존재하는지 확인. 반환 타입은 boolean.
count: SQL의 결과 개수를 센다. 반환 타입은 long.
[JPA Repository에서 By 뒤에 들어갈 수 있는 구절 정리]
GraterThan: 초과
GraterThanEqual: 이상
LessThan: 미만
LessThanEqual: 이하
Between: 사이에
StartsWith: ~로 시작하는
EndsWith: ~로 끝나는
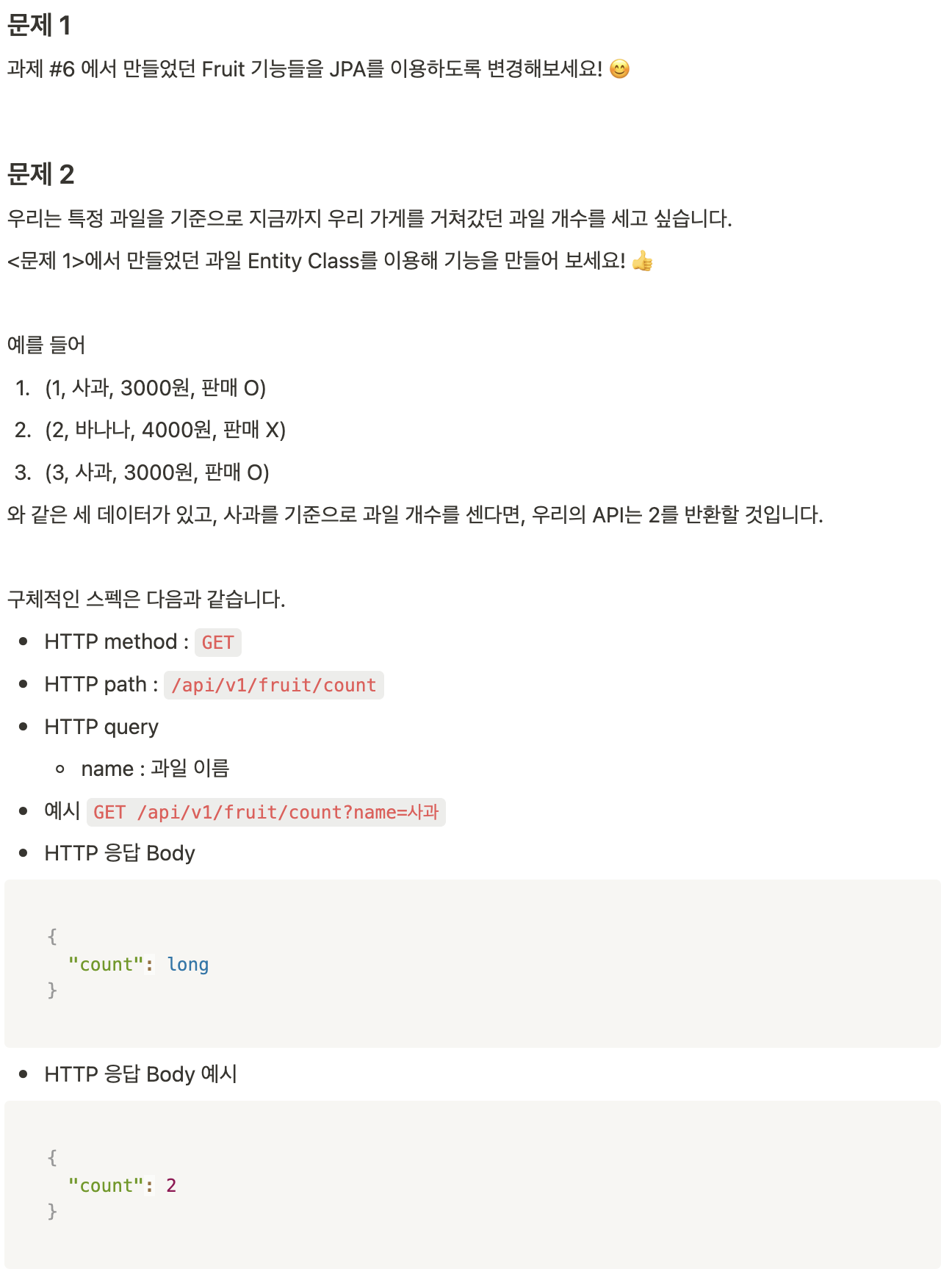
[과제]
진도표 7일차와 연결됩니다
우리는 JPA라는 개념을 배우고 유저 테이블에 JPA를 적용해 보았습니다. 몇 가지 문제를 통해 JPA를 연습해 봅시다! 🔥

댓글을 작성해보세요.
