
빅데이터 클러스터 구축 패키지; 성공을 향한 로드맵
High Availability가 보장되는 빅데이터 시스템 또는 분산처리 시스템 클러스터 (HDFS, Zookeeper, Spark, Zeppelin) 를 직접 구축해보는 코드랩 위주의 수업입니다.

초급자를 위해 준비한
[데이터 엔지니어링] 강의입니다.
이런 걸 배울 수 있어요
Big Data Cluster Setup
Distributed File OR Processing System
High Availability
Hadoop
HDFS
Apache Spark
Apache Zeppelin
Apache Zookeeper
AWS (EC2, AMI, Security Group)
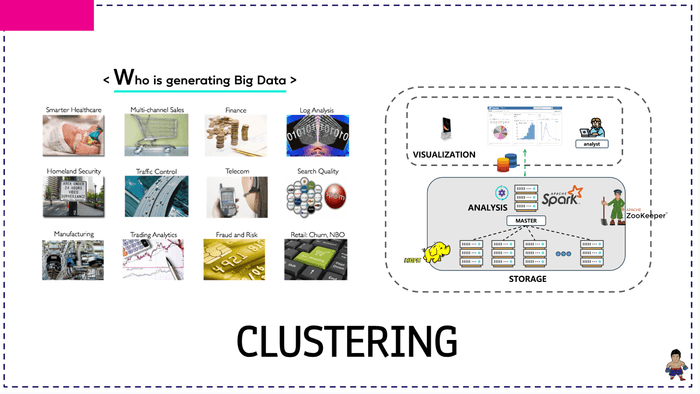
클러스터 패키지를 이론 및 탄탄한 코드랩을 통해 직접 구축해볼 예정입니다.

위에 고가용성 파일시스템 데몬 구성들이 다소 어렵게 보이시나요? 원래 항상 처음 보는 아키텍처 및 시스템 구성도들은 부담스럽기 마련입니다.
하지만
약 6년동안 훌륭한 제자들의 소중한 피드백을 회고하여, 지난 인프런 2개 강의를 런칭한 경험으로 바탕으로, 수강생분들의 눈높이에 맞춰 차근차근 하나씩 용이하게 최대한 쉽고 질 좋은 컨텐츠로 구성하였으니 부담없이 follow up 해주셔도 괜찮습니다.
 special thanks to my lovely students 👨🏻🎓
special thanks to my lovely students 👨🏻🎓

커리큘럼에 대해서 알려주세요 🧑🏻🏫
바로 CODELAB 부터 시작하지 않고, 고가용성 클러스터를 구축할 때 필요한 이론 부터 학습합니다. 그리고 AWS 환경이나 리눅스 환경에 익숙하지 않는 수강생분들을 위해서 가이드 영상 및 백그라운드 지식을 공부하고 본격적으로 심층적인 코드랩을 진행할 예정입니다 😎

빅데이터 OR 분산처리에 관심있는 누구나 수강 가능합니다 🧑🏻🎓

J.PHIL 소개 👨👨👧👦


이런 분들께
추천드려요!
학습 대상은
누구일까요?
빅데이터 처리 시스템 클러스터 구축을 직접 경험하고 싶은 수강생
데이터 분석 및 시스템에 관심있고 직무를 희망하는 학생
고가용성 클러스터 실습을 직접 경험하고 싶은 개발자
빅데이터 분석 및 구축 분야에서 강점을 만들고 싶은 취준생
선수 지식,
필요할까요?
파이썬 기초 코딩
리눅스 명령어 기초 지식
데이터베이스 기초 지식
안녕하세요
J.PHIL입니다.
428
명
수강생
36
개
수강평
50
개
답변
4.9
점
강의 평점
2
개
강의
안녕하세요 J.PHIL 입니다 🧑🏻🎓
첫번째 강의로 [ 빅데이터 시스템 구축 및 분석에 관심있는 입문자 ] 를 위해
"Mastering Big Data Processing: Tools and Techniques for Success" 강의를 오픈 하였습니다.
'수업 및 프로필' 자세한 사항들은 수업 상세 페이지에 잘 작성했으니 참고 부탁드립니다 🙏🏻
커리큘럼
전체
36개 ∙ (4시간 51분)
해당 강의에서 제공: