
빅데이터 파이프라인 마스터; 성공을 위한 도구와 기술
J.PHIL
여러분들은 빅데이터 프로세싱의 4단계에 해당하는 [데이터 수집 ▶ 데이터 저장 ▶ 데이터 분석 ▶ 표현] 에 대한 내용을 이론 30% + 실습 70%으로 이루어진 코드랩 방식으로 보다 재밌고 체계적으로 학습합니다 🧑🏻🏫
초급
빅데이터, Elasticsearch, Apache Spark
High Availability가 보장되는 빅데이터 시스템 또는 분산처리 시스템 클러스터 (HDFS, Zookeeper, Spark, Zeppelin) 를 직접 구축해보는 코드랩 위주의 수업입니다.

Big Data Cluster Setup
Distributed File OR Processing System
High Availability
Hadoop
HDFS
Apache Spark
Apache Zeppelin
Apache Zookeeper
AWS (EC2, AMI, Security Group)
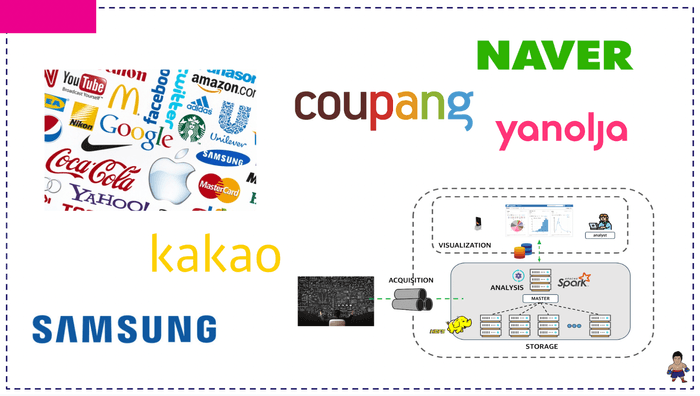
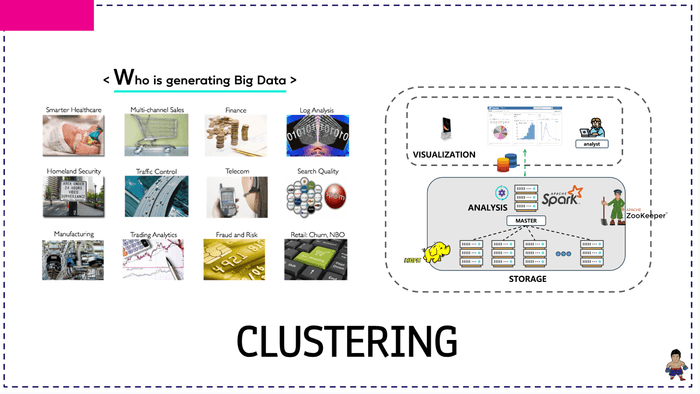
클러스터 패키지를 이론 및 탄탄한 코드랩을 통해 직접 구축해볼 예정입니다.

위에 고가용성 파일시스템 데몬 구성들이 다소 어렵게 보이시나요? 원래 항상 처음 보는 아키텍처 및 시스템 구성도들은 부담스럽기 마련입니다.
약 6년동안 훌륭한 제자들의 소중한 피드백을 회고하여, 지난 인프런 2개 강의를 런칭한 경험으로 바탕으로, 수강생분들의 눈높이에 맞춰 차근차근 하나씩 용이하게 최대한 쉽고 질 좋은 컨텐츠로 구성하였으니 부담없이 follow up 해주셔도 괜찮습니다.
 special thanks to my lovely students 👨🏻🎓
special thanks to my lovely students 👨🏻🎓

바로 CODELAB 부터 시작하지 않고, 고가용성 클러스터를 구축할 때 필요한 이론 부터 학습합니다. 그리고 AWS 환경이나 리눅스 환경에 익숙하지 않는 수강생분들을 위해서 가이드 영상 및 백그라운드 지식을 공부하고 본격적으로 심층적인 코드랩을 진행할 예정입니다 😎




학습 대상은
누구일까요?
빅데이터 처리 시스템 클러스터 구축을 직접 경험하고 싶은 수강생
데이터 분석 및 시스템에 관심있고 직무를 희망하는 학생
고가용성 클러스터 실습을 직접 경험하고 싶은 개발자
빅데이터 분석 및 구축 분야에서 강점을 만들고 싶은 취준생
선수 지식,
필요할까요?
파이썬 기초 코딩
리눅스 명령어 기초 지식
데이터베이스 기초 지식
435
명
수강생
37
개
수강평
50
개
답변
4.9
점
강의 평점
2
개
강의
첫번째 강의로 [ 빅데이터 시스템 구축 및 분석에 관심있는 입문자 ] 를 위해
"Mastering Big Data Processing: Tools and Techniques for Success" 강의를 오픈 하였습니다.
'수업 및 프로필' 자세한 사항들은 수업 상세 페이지에 잘 작성했으니 참고 부탁드립니다 🙏🏻
전체
36개 ∙ (4시간 51분)
해당 강의에서 제공:
전체
18개
4.7
18개의 수강평
수강평 2
∙
평균 평점 5.0
5
이전에 파이프라인 강의를 듣고 본 강의를 듣고 있는데 머리속에 잘 들어와서 너무 좋아요~ 컴팩트하고 실무에 쓰일 강의 감사해요~ 이 강의도 금방 들어버릴 것 같은데 다른 강의도 있을지 기대됩니다.
2일 걸렸네요. lab 형식이라 좀 빠르게 진행되고 , namenode 기동이 안되어서 삽질하느라 어려웠는데 (아마 어딘가 실수하여 그런듯) 나중에 보니 trouble shoot guide 부분에 기동절차 스크립트 및 로그 보는 부분 정리해 두셨네요. 이것도 봤다면 좀더 빨리 실수를 복구했을텐데 ㅜㅜ 혹시 진행하시는 분들은 모두 따라 치는 것보다는 한번 정독하고 따라하는 것도 좋을 것 같아요~ 강사님. 좋은 강의 매번 감사해요~
안녕하세요 Jason.King 님, 제 이번 강의를 열심히 수강해주셔서 감사합니다 :) 때때로 버그나 trouble shooting을 직접 겪어보면서 고민해보고 복기해보는 것이 많이 도움이 될 때가 있을테니 오히려 이번 경험이 추후 큰 도움될거라 사료됩니다. 굵직한 오프소스를 직접 구축해보면 클러스터를 구축해보셨으니 다른 오프소스가 나와도 이제 빠른 시간에 잘 구축하실 수 있을겁니다. 앞으로도 화이팅입니다
수강평 3
∙
평균 평점 4.3
수강평 1
∙
평균 평점 5.0
5
곧 졸업을 앞둔, 데이터 엔지니어를 지망하는 컴공과 학생입니다. 취업 관련 포트폴리오를 만들면서, 빅데이터를 처리하기 위한 파이프라인 및 아키텍쳐를 어떻게 구성하고, 어떤 식으로 aws 환경을 설정하여 최대한 낮은 비용으로 효율적으로 이용할 수 있을지 고민이 많았었는데, 본 강의를 통해 엄청난 인사이트와 노하우들을 얻어갑니다. 특히, 빅데이터를 다루는 다양한 프레임워크들에 대한 많은 지식도 얻게 되어 앞으로 어느쪽으로 파고들수 있을지 영감을 얻은 것 같아 기쁩니다. 가뭄 끝에 단비를 만났습니다. 저와 같이 이쪽 분야를 지망하시는 학생분들께 수강 추천드립니다.
안녕하세요 one831님, 소중한 수강평 감사드리며, 앞으로도 좋은 결과 있기를 바랍니다 화이팅입니다
수강평 4
∙
평균 평점 5.0
5
이론 부터 코드랩까지 초기 입무자에게 정말 추천하는 강의 입니다!! 빅데이터 클러스터 구축 강의로 필수로 수강하길 추천합니다!!
안녕하세요 Yeonwoo Jung님, 소중한 수강평 감사합니다. 기회될 때 하루이틀 투자하셔서 AWS 로 실습을 따라해보셔서 좋은 성과 있기를 바랍니다. 새해 복 많이 받으세요 :)
지식공유자님의 다른 강의를 만나보세요!
같은 분야의 다른 강의를 만나보세요!
월 ₩19,800
5개월 할부 시
₩99,000
![[2025] SQLD 문제가 어려운 당신을 위한 노랭이 176 문제 풀이강의 썸네일](https://cdn.inflearn.com/public/files/courses/336270/cover/01jr03fxecqc2z7spwsjxhpc80?w=420)
![[리뉴얼] 처음하는 MongoDB(몽고DB) 와 NoSQL(빅데이터) 데이터베이스 부트캠프 [입문부터 활용까지] (업데이트)강의 썸네일](https://cdn.inflearn.com/public/courses/324183/cover/fbe9f0cc-4c42-4435-b855-f283f6932415/324183.png?w=420)

![[멘토링] 데이터로 미래를 그리다: 모두를 위한 데이터 리터러시강의 썸네일](https://cdn.inflearn.com/public/courses/333359/cover/4988013e-cded-41bf-b759-2b11d16bd08d/333359.png?w=420)

![[리뉴얼] 처음하는 SQL과 데이터베이스(MySQL) 부트캠프 [입문부터 활용까지]강의 썸네일](https://cdn.inflearn.com/public/courses/324208/cover/85872a8e-d2bb-4c43-82fc-d55fa067746e/324208.png?w=420)




![따라하며 배우는 도커와 CI환경 [2023.11 업데이트]강의 썸네일](https://cdn.inflearn.com/public/course-325821-cover/e5a56b04-463b-410c-9b3a-d769cd192add?w=420)