Kafka & Spark 활용한 Realtime Datalake
초보자를 위한 Kafka & Spark 실시간 파이프라인 입문 강의. 핵심 개념부터 아키텍처까지 마스터하기 위한 올인원 강의입니다.

초급자를 위해 준비한
[Kafka, Apache Spark] 강의입니다.
이런 걸 배울 수 있어요
Github과 Actions, AWS Code Deploy로 CI/CD 구현
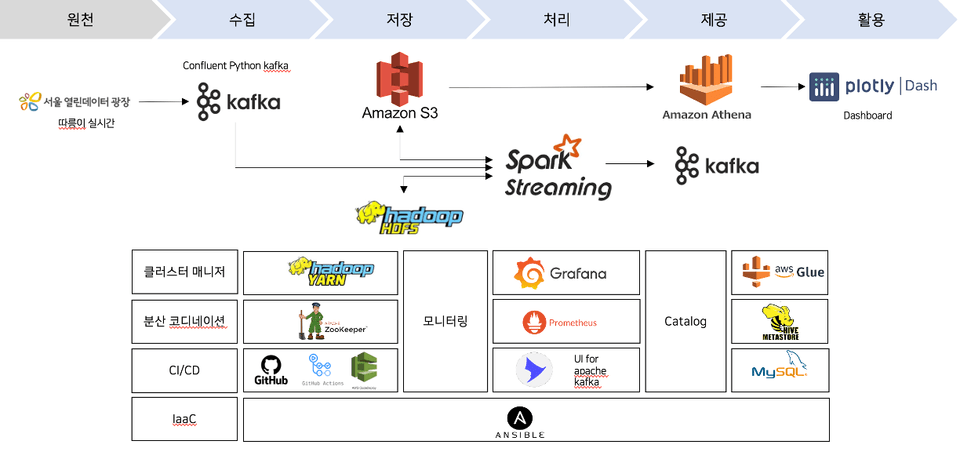
Kafka Broker, Confluent Producer & Consumer
Prometheus & Grafana를 이용한 Kafka Dashboard 모니터링
Catalog 관리를 위한 Spark & Hive Metastore
Spark Streaming을 이용한 실전 프로젝트 구현
Kafka & Spark, Zookeeper & Yarn의 가용성 테스트


실시간 데이터 파이프라인을 배우고 싶어요.
데이터 파이프라인에 관심은 있지만 실시간 처리는 경험해보지 못한 분

DataLake 를 알고싶어요.
Cloud 위에 구축되는 DataLake가 어떻게 구현되는지 배우고 싶으신 분

아키텍트로 성장하고 싶어요.
인프라 설계부터 코드레벨까지 대용량 처리가 가능하면서 견고한 아키텍처 구현이 궁금하신 분


이런 분들께
추천드려요!
학습 대상은
누구일까요?
Kafka & Spark을 배우고 싶은 분
실시간 파이프라인 구현을 배우고 싶은 분
데이터 엔지니어로써 여러 지식과 Skill 개발이 필요하신 분
선수 지식,
필요할까요?
파이썬에 대한 기본 개념
SQL에 대한 기본 지식 (Filter, GroupBy, OrderBy 수준)
Linux 기초적인 커맨드를 다룰 수 있는 수준
안녕하세요
김현진입니다.
880
명
수강생
34
개
수강평
137
개
답변
4.9
점
강의 평점
2
개
강의
안녕하세요.
정보관리기술사를 취득한 이후 지금까지 얻은 지식을 많은 사람들에게 공유하고,
특히 데이터 엔지니어를 희망하고 공부하고 싶은 분 들에게 도움이 되고자 컨텐츠를 제작하고 있습니다.
반갑습니다 ^^
Contact: hjkim_sun@naver.com
커리큘럼
전체
113개 ∙ (28시간 23분)
해당 강의에서 제공: