

마이크로넛 자바 클라우드 어플리케이션 제작
Billy Lee
자바 오라클 클라우드 네이티브 어플리케이션을 제작하면서 비동기 처리, I/O 처리, 고성능 웹 어플리케이션, 게다가 JIT 컴파일러 기술로 2배 이상의 빠른 어플리케이션 실행 처리로 네트워크 입력에 부하 없는 초고속 어플리케이션을 제작할 예정입니다.
초급
Micronaut, Oracle, MSA
일상에서 빅데이터 기술 접하기
하둡으로 빅데이터 다루기
하둡으로 빅데이터를 다루는 분산처리 기술 배우기
자바 언어를 이용하여 하둡 빅데이터 다루기
관계형 데이터 처리 한계를 하둡으로 뛰어넘는 기술 배우기
하둡의 다양한 프로젝트이자 인터페이스들을 배우기
바야흐로 빅데이터 시대! 👨💻
하둡(Hadoop)으로 전문가가 되어보세요.

여러 IT 대기업, 소셜 미디어 서비스 등에서 빅데이터 분석 및 처리에 하둡(Apache Hadoop)을 앞다투어 사용하고 있습니다. 하둡은 대량의 자료를 적은 비용으로 처리할 수 있도록 만들어진 자바(Java) 언어 기반의 프레임워크로, 대규모 데이터 세트를 분산 저장하고 처리해 줍니다. 그런데, 그런 하둡을 통해 빅데이터 전문가 수준의 반열에 올라갈 수 있다면 어떨까요?
기업들은 데이터 분석을 통해 새로운 시장을 개척하고 희소성있는 가치를 부여하며, 새로운 소비자들에게 필요한 정보를 실시간으로 제공할 수 있는 쾌감을 부여할 수 있게 될 겁니다. 중소기업 또한 빅데이터는 꼭 다뤄야 할 필수 사항인 만큼, 빅데이터 관련 직무로 취업/이직을 꿈꾸는 분들께는 희소식이 아닐 수 없습니다.
BigData with Hadoop

구글, 야후, 페이스북, IBM, 인스타그램, 트위터 등
여러 기업에서 데이터 분석에 사용하고 있는
대표적인 빅데이터 솔루션, 하둡(Hadoop)을 통해
빅데이터 분산형 시스템 인프라를 구축해 봅니다.
이 강의는 빅데이터 용어에 대한 이해를 시작으로 공개 소프트웨어 하둡(Hadoop)을 통해 빅 데이터를 다루는 과정을 간접 체험할 것입니다. 이 강의를 통해 수강생 여러분은 빅데이터 테크놀로지 (Big Data Technology) 세계, 그리고 4차 혁명의 세계를 동시에 경험할 수 있게 됩니다.
하둡(Hadoop)이란?



물론, 여기에 해당되지 않는 분들도 환영해요. (초보자는 2배로 환영합니다 ✌)




수강 전, 선수 지식을 확인해주세요!
서버 통합에 유리한 가상화 기술을 배우며 OS 레벨 가상화를 통해 하나의 OS로 여러 대의 서버를 분리시키는 방식을 기초로 배울 예정입니다. 리눅스에 적용할 수 있는 가상화 방식인 오픈 소스 솔루션 우분투(Ubuntu)를 통해 누구나 도전하여 다량의 서버를 제작 운영하게 될 것입니다. 나아가, 게스트 운영체제에 대한 지식은 물론 다량의 서버를 통해 빅 데이터를 분산 기술로 바꾸게 되며 벌어지는 다량의 기술 경험을 축적할 수 있게 됩니다. 서버 가상화를 이용하여 하나의 물리적인 서버에서 혹은 운영체제에서 매우 효율적인 가상 머신의 어려 운영체제를 경험할 수 있는 특혜(?)를 누릴 수 있죠.
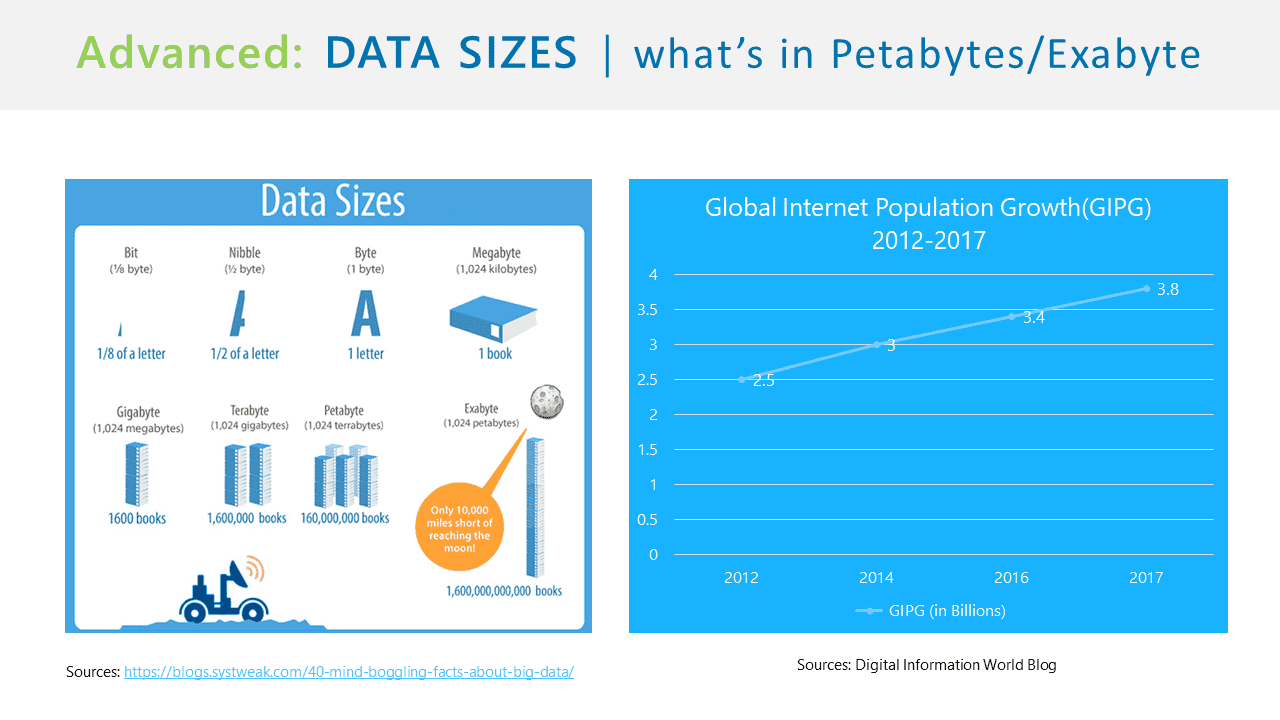
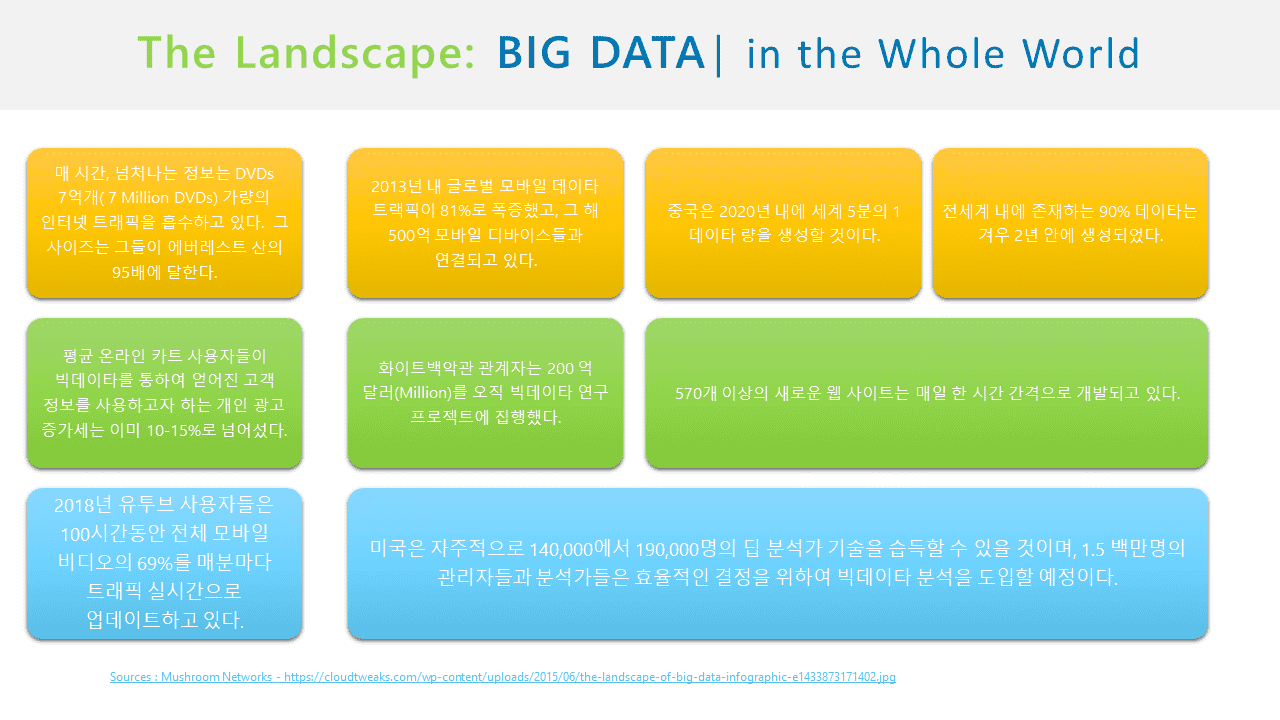
프론트엔드(FrontEnd) 개발자가 웹 애플리케이션을 개발할 때 자연스럽게 마주치는 리눅스 CLI(Command Line Interface) 방식의 도구를 사용하는 기초 방법부터, 하둡을 다루게 되는 리눅스 터미널을 자연스럽게 배울 예정입니다. 물론 비(非) Windows 기반의 GUI 환경에서 원도처럼 우분투를 사용하기 위한 제반 사항을 배우면서, 셀의 설정 파일과 같은 리눅스 시스템의 이해를 넘어 중급자 방향으로 자연스럽게 인도할 것입니다.
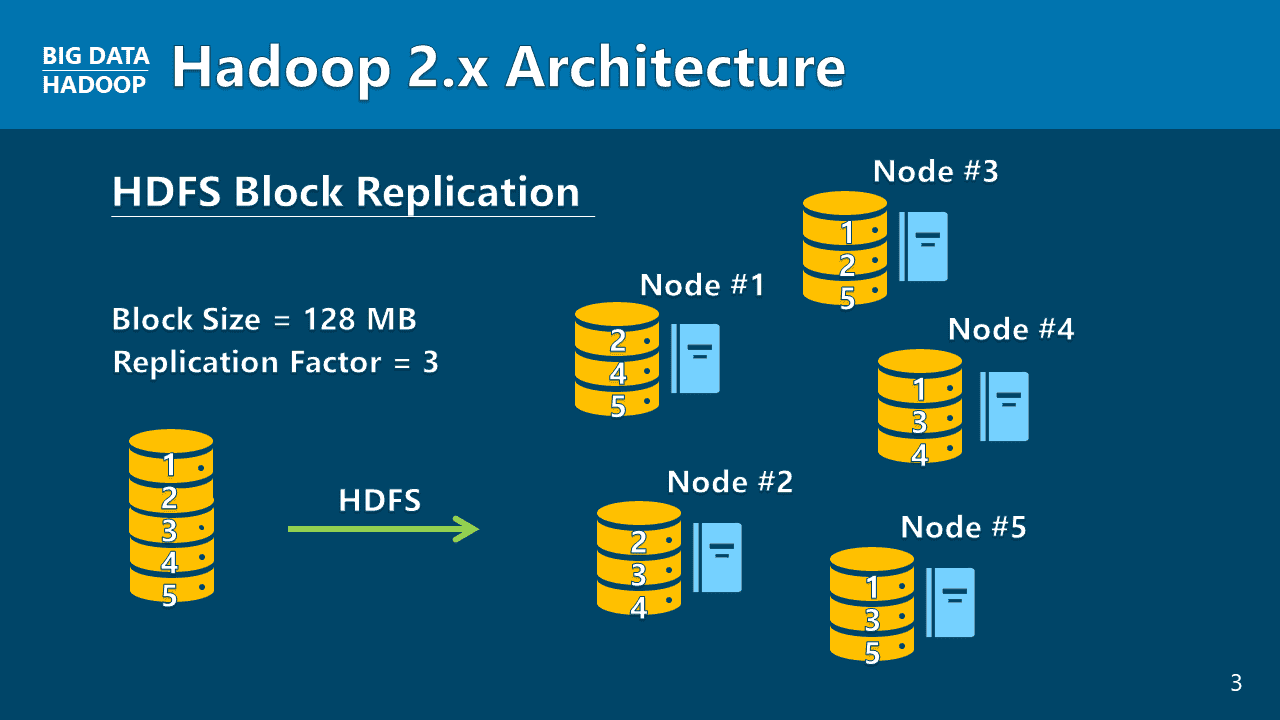

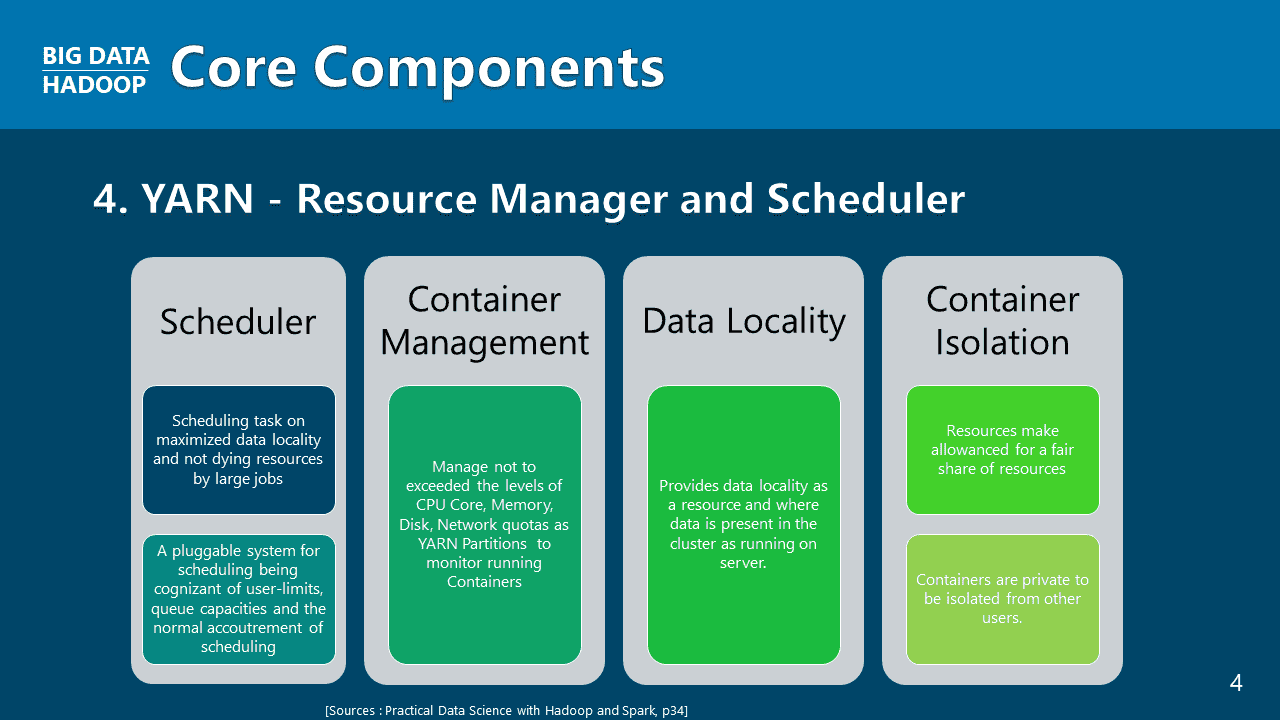
비정형 데이터 처리를 위한 빅데이터의 시작은 구글의 파일 시스템의 모형인 하둡 분산 파일 시스템(HDFS)과 맵리듀스(MapReduce), 그리고 얀(YARN)이라는 클러스터 확장 및 리소스 관리에 대한 이해입니다. 하둡버전 1, 2, 3의 아키텍쳐 구조에 대해 하나하나 살펴보며, 하둡 기술의 역사가 어떠한지 수강생 여러분께 그림을 그려드릴 것입니다.
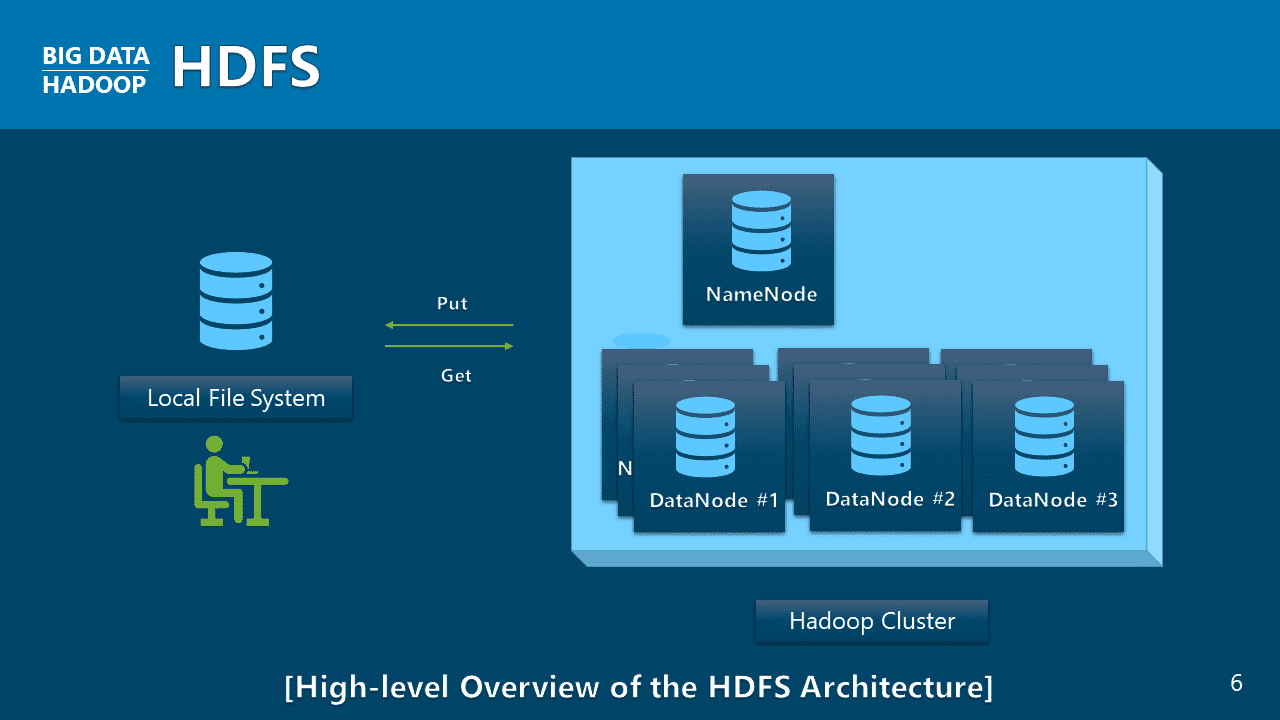
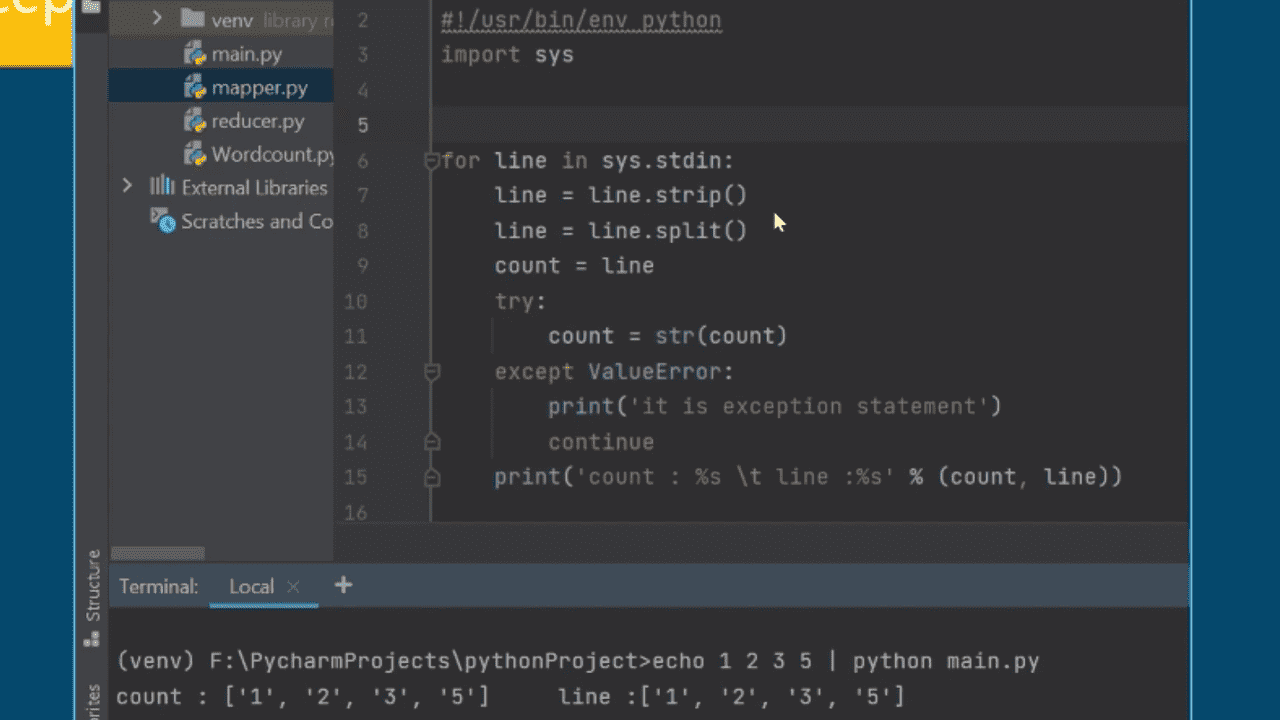
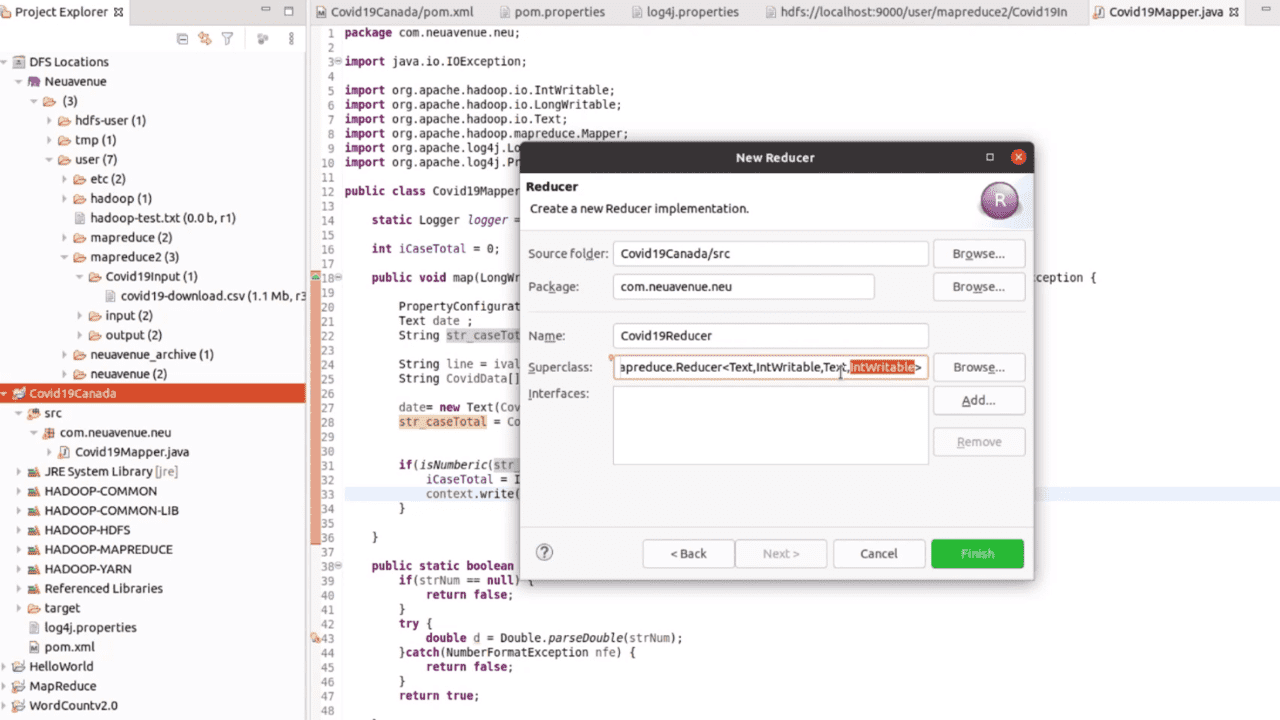
데이터 조작에 쓰이는 기술은 다양하지만, 빅데이터 분석의 기초는 맵리듀스 애플리케이션 제작에 있습니다. 프로그래밍 언어 파이썬(Python)으로 기본 워드카운트 맵리듀스 애플리케이션부터 이클립스(Eclipse) 기반의 자바(Java) 언어로 COVID-19 애플리케이션 제작에 이르기까지, 다양한 빅데이터 맵리듀스 애플리케이션 제작은 이제 선택을 넘어 필수로 나아가야 할 방향을 제시할 것입니다.
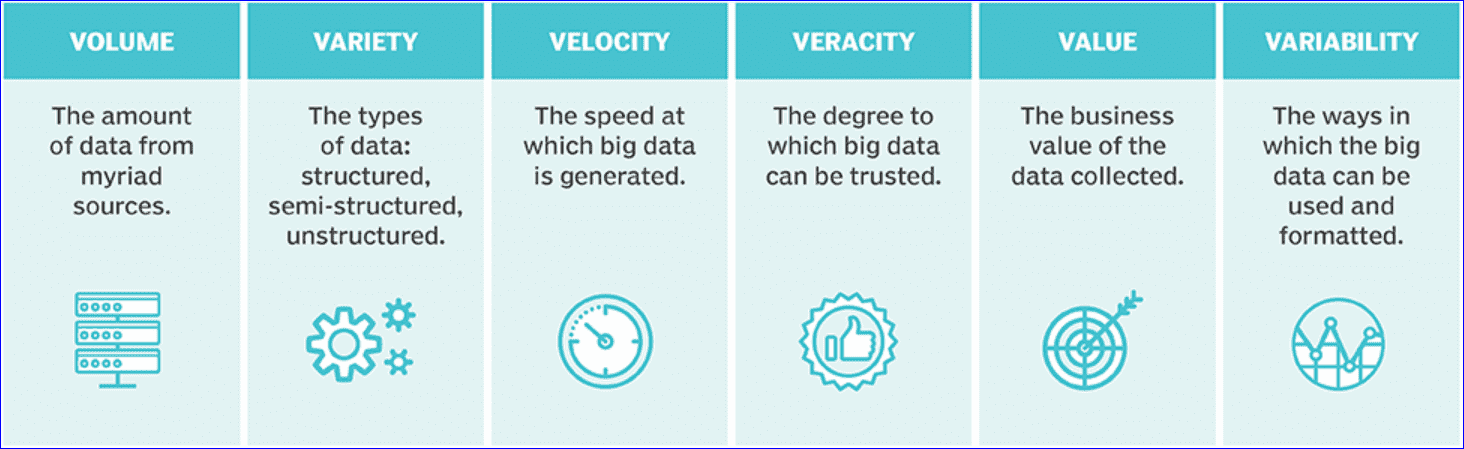
Q. 빅데이터란 무엇인가요? 하둡을 사용할 때 그 정의가 필요한가요?
네, 당연히 하둡(Hadoop)을 다룰 때 반드시 빅데이터에 대한 간략한 정의 및 이해를 요구합니다. 물론 완벽하고 깊이있는 수준의 숙지를 요구할 정도는 아닙니다. 다만 하둡을 다룰 때 꼭 필요한 이해 정도를 요구하는 형태겠죠.
빅데이터는 하둡 툴을 가지고 매우 큰 데이터셋을 다룹니다. 이 데이터셋은 수많은 기업들이 다루는 여러 패턴 및 트렌드를 파악하기 위해 분석하는 기초 데이터입니다. 인간의 사회적 행동 및 패턴, 그리고 상호작용 가운데 벌어지는 인류의 가치 창출과 연관이 서려 있지요.
Q. 하둡이 무엇인가요? 컴포넌트는 무엇이고, 하둡 스택은 또 무엇인가요?
테라바이트를 넘어 페타(Petta/Zettabyte)에 이르는 대규모 소셜 사이트의 데이터를 처리해야 하는 사명을 하둡이 돕고 있습니다. 하둡 스택(Hadoop Stack)이란 이런 빅데이터를 다루는 오픈 소스 프레임워크 방식을 가리킵니다.
단순히 ‘하둡’은 ‘하둡 스택’이라고 불립니다. 싸고 일상적인 커머디티 하드웨어(Commodity hardware)를 사용하여 클러스트를 제작하고 그 방대한 서버들의 집합체인 클러스트 내에 대용량 프로세스 처리를 하도록 돕는 것이 하둡이자 하둡 스택이죠. 하둡 스택은 ‘단순 배치 프로세스’라고도 하며, 자바 기반의 '분산 컴퓨팅 플랫폼'입니다. 그래서 개인이 원하는 만큼의 데이터를 주기별로 배치를 돌리며 처리하면서, 데이터들을 원하는 형태로 가공 분산하여 결과값을 산출하는 것이죠.
Q. 프로그래밍 지식이 필요한가요?
프로그래밍에 대한 지식이나 코드 작성 경험이 없어도 괜찮습니다. 자바나 파이썬을 처음 경험한다고 생각하고 가르칠 수 있도록, 깊이있는 이해를 바탕으로 수업을 진행합니다. 강의에 쓰인 문서는 영어로 되어 있지만 따라하시는 데는 지장이 없도록 한국어로 강의합니다. 간혹 영어로 설명을 하기는 하지만, 고등학교 수준이면 해석할 수 있지 않을까요? (저의 낮은 영어실력으로도 꿈을 이룬 것처럼요.)
Q. 하둡을 다루는데 빅 데이터는 어느 정도 연관이 있나요?
이 강의는 당연히 하둡을 다루고 있습니다. 단순히 RDMS라는 오라클이나 MSSQL, 혹은 MYSQL을 넘어서 대용량 처리를 시작으로 데이터 처리 속도 문제, 저비용 효과라는 기업의 필수 요소를 창출하고자 합니다. 특히 소셜을 다뤄야 하는 기업들, 즉 곧 로우와 컬럼에 기초한 데이터 RDMS에서 다루는 관계형 데이터를 다루는 스트럭쳐 데이터(Structured data)뿐만 아니라, 이미지, 오디오, 워드 프로세스 파일 그 자체를 다뤄야 하는 언스트럭쳐 데이터(Unstructred data) 등도 하둡이 다루게 됩니다.
서비스 스트럭쳐 데이터를 다룰 때는 Email, CSV, XML, and JSON 과 같은 웹 서버와의 통신과 데이터 연동에 관련된 데이터를 말하고 있죠. HTML, Web Sites, NoSQL Databases 역시도 여기에 포함됩니다. 물론 EDI라는 비지니스 서류 관련 전산 이동시키는 컴퓨터 대 컴퓨터 간의 이동 처리 문제를 다룰 때 쓰는 데이터셋 누적도 역시 여기에 속하죠.
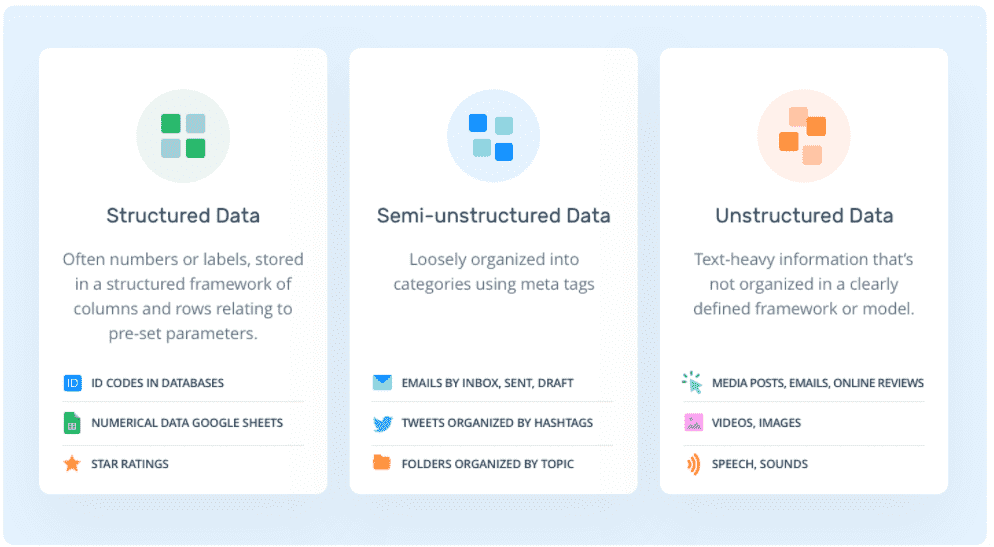
Q. 어느 정도 수준까지 내용을 다루나요?
이 강의는 Ubuntu(우분투) 20.04 LTS 기반에 Hadoop(하둡) 3.2.1을 직접 사용자가 설치할 수 있도록 도와줍니다. 유닉스나 리눅스 경험이 없어도 자연스럽게 따라오시면 리눅스를 바탕으로 이어지는 설치 요령 및 리눅스 운영체제를 자연히 숙지하게 됩니다. 또한 하둡이 다루는 CLI 언어나 사용자 언어를 익히는 기초적인 부분을 넘어, 구글이 가지고 있는 기술인 DFS and MapReduce 기술에 익숙해지도록 도와줄 것입니다. YARN(얀)에 대한 이해는 기초 이론만 가지게 되며, 추후 하둡 3.3.0 중급 과정에서 클러스트를 설치하면서 얀에 대한 보다 깊이있는 학습을 기대하시길 바랍니다.
Q. Ubuntu 20.04 LTS를 실습 환경으로 사용하는 이유가 있나요?
우분투(Ubuntu)는 무료로 사용할 수 있고, LTS(Long-Term Service)를 통해 장기 서비스 지원을 꿈꾸는 기업을 대상으로 하둡을 리눅스에서 설치하면서 자연스럽게 기업이 요구하는 운영체제 및 개발 환경을 구축할 수 있도록 돕고 있습니다. 동일한 환경 내에 이클립스나 인텔리전트를 사용하도록 도움으로써, 당장 빅데이터를 다루는 데이터 과학의 꿈을 실현시키는 데 함께 이바지하도록 하는 좋은 시간이 될 것입니다.

비슷한 환경, 즉 GUI(그래픽 유저 인터페이스)
환경을 통해 사용자를 돕고 있죠.
학습 대상은
누구일까요?
빅데이터의 기초를 처음부터 배우고자 하는 열공생
빅데이터 원리와 적용에 목말라하시는 분
데기업의 빅데이터를 다루고자 하둡을 배우고 싶은 분들
자바에 기초 지식이 있으신 분들
선수 지식,
필요할까요?
The Concept of Big Data (빅데이터 이해)
가상머신
데이터 셋 용어
리눅스 이해(Ubuntu)
자바 15
574
명
수강생
37
개
수강평
69
개
답변
4.6
점
강의 평점
2
개
강의
네오아베뉴 대표 빌리 리 입니다.
2022년 9월 한국에 가족 모두 귀국한 뒤 현대자동차 빅데이터 프로젝트에 TA 컨설팅 (2022.09 -11월까지)하였고, 에자일 PM과 빅데이터 C-ITS 시스템 구축으로 하둡 에코시스템 및 머신러닝 딥러닝 리드하여 프로젝트 관리자 (PMO)역할을 하였습니다. 이후 Azure Data Factory & Azure Databricks 을 가지고 데이터 관리 기술을 AIA 생명 보험 이노베이션 데이터 플랫폼 팀에서 근무하면서 데이터 과학자로 깊은 탐구와 열정을 불살랐습니다.
2012년에서 2020년 까지 센터니얼 칼리지 Software Eng. Technician 졸업한 열공생이자 한국에서는 9년의 IT 경력 소유자로 금융권 (재무, 금융 프로젝트 및 빅데이터 관련 ) 에 다수 근무했습니다.
1999년 필리핀 (Dasmarinas) 지역에서 P.T.S. 네트워크 엔지니어링 자원 봉사자로 1년 근무하면서 글로벌 IT 세계와 네트워크 지식을 쌓으며 이후 2000년 한국으로 돌아와 K.M.C.에서 Clarion 4GL 언어로 Warehouse Inventory Control and Management 그리고 PIS Operational Test PCS C/C++ 개발했었습니다.
2001년 LG-SOFT SCHOOL 자바 전문가 과정 이수 후 CNMTechnologies 에서 e-CRM/e-SFA R&D 연구 및 개발 2년 정도 (한국산업은행/대정정부청사/영진제약) 다양한 프로젝트를 섭렵하였습니다.
2004년부터 2012년 캐나다로 올 때까지 SKT/SK C&C (IMOS), SC제일은행(TBC), 프로덴션 생명(PFMS), 교보생명 AXA Kyobo Life Insurance Account Management, Kook-min Bank 국민은행 Financial Management Reconstruction NGM외 다수 프로젝트에 참여 개발 및 리드하였습니다.
2012년 연말에 캐나다에 거주하면서 세 아이의 아빠이자 Scrum Master로서 에자일 개발 방식을 채택하여 핸디맨 어플/이커머스 어플/프로덱트 개발/레시피 어플 개발한 미주 캐나다 지역의 실경험자입니다.
전체
85개 ∙ (6시간 39분)
해당 강의에서 제공:
전체
36개
4.6
36개의 수강평
수강평 3
∙
평균 평점 5.0
5
이 강의는 빅데이터를 다루는 하둡 전문가로 양성하고 싶은 마음에서 강의를 제작했습니다. 클라우데라와 같은 종합적인 온 프로메스 배포 소프트웨어 어플리케이션(On-Premise Distribution Software: OPD)을 사용하기 보다는 직접 하둡을 처음부터 설치하고 데이터셋을 추출하고 이동 및 로드하는 단계로 여러분을 이동시킬 것입니다. 1.x 버전부터 시작된 하둡은 이제 3.3 버전까지 많은 기능들이 추가되면서 무척 해비한 플랫폼이 되었지만 많은 도구들을 다루며 빅데이터 전문가로 양성되는 마음이 넘치는 강의되기를 바랍니다.
수강평 4
∙
평균 평점 5.0
5
장점: 하둡 맵리듀스 기초를 배울 수 있다. 한국어로 된 유일한 하둡 강의인 듯 아쉬운 점: 맵퍼를 두개 사용해서 하나의 공통 키로 추출하거나 키를 두개 쓰는 경우 , 컴퍼레이터를 직접 설정하는 방법 등 궁금했던 내용이 없어서 아쉬웠다. 단점: 강사님 한국어 발음이 명확하지 않은데 배경음악이 커서 여러번 무슨 말을 하는건지 다시 들어야했다. --------------------------------------- 선생님 답변 보고 별점 5로 수정합니다.
친절히 자세한 평가 감사합니다. 하둡의 이론은 방대하여 모든 일에 손을 댈수가 없다고 말할 수 있네요. 저의 강의를 듣고 하둡 전체를 이해하기는 더더욱 힘들죠. 배경음악을 제거한 뒤 선명한 목소리로 재녹음하였으니 재수강 고맙겠습니다. 업데이트한 강의도 있으니 고요한 시간에 들으시면서 하둡 전문가로 남기를 기대합니다.
지식공유자님의 다른 강의를 만나보세요!
같은 분야의 다른 강의를 만나보세요!
₩55,000

![[2025] SQLD 문제가 어려운 당신을 위한 노랭이 176 문제 풀이강의 썸네일](https://cdn.inflearn.com/public/files/courses/336270/cover/01jr03fxecqc2z7spwsjxhpc80?w=420)
![[리뉴얼] 처음하는 MongoDB(몽고DB) 와 NoSQL(빅데이터) 데이터베이스 부트캠프 [입문부터 활용까지] (업데이트)강의 썸네일](https://cdn.inflearn.com/public/courses/324183/cover/fbe9f0cc-4c42-4435-b855-f283f6932415/324183.png?w=420)

![[멘토링] 데이터로 미래를 그리다: 모두를 위한 데이터 리터러시강의 썸네일](https://cdn.inflearn.com/public/courses/333359/cover/4988013e-cded-41bf-b759-2b11d16bd08d/333359.png?w=420)

![[무료]기초 텍스트마이닝: 앱 리뷰 분석 with 파이썬(40분 완성)강의 썸네일](https://cdn.inflearn.com/public/courses/331163/cover/74cc657a-a8f9-4a78-8edb-0d5fcd4c4c75/331163.png?w=420)



![[관리코스 #3] DE, DBA (SSIS, SSAS, MachineLearning, BI, ETL)강의 썸네일](https://cdn.inflearn.com/public/courses/329784/cover/c5e6543b-72c3-4471-b43f-15b9002e65ed/329784-eng.png?w=420)