
나도코딩의 자바 기본편 - 풀코스 (20시간)
나도코딩
배움의 즐거움을 알게 해주는 강의. 나도코딩의 자바 기본편을 소개합니다.
입문
Java, 객체지향
드디어 나왔습니다. 세상에서 가장 쉬운 머신러닝 강의 무료인데 뭘 망설이세요? 어서 '학습하기' 버튼을 꾸욱 눌러보세요

파이썬 머신러닝의 필수 패키지인 사이킷런 사용법
지도학습, 비지도학습의 주요 머신러닝 알고리즘
넷플릭스는 어떻게 만들까? 영화 추천 시스템 프로젝트
텍스트 분석은 덤으로!
파이썬 머신러닝으로
영화 추천 시스템 만들어보세요! 🎞️

머신러닝, 한 번쯤은 들어보셨죠? 머신러닝은 인공지능의 한 분야로 우리말로는 기계학습이라고 하는데, 양질의 데이터를 주면 그 데이터를 스스로 학습해서 모델이라는 것을 만드는데요. 이 모델을 이용하면 새로운 입력값이 들어왔을 때 출력값을 예측하는 식으로, 그러니까 함수를 직접 만드는 거라고 이해하시면 됩니다.
 참고로 이거 아닙니다 :)
참고로 이거 아닙니다 :)
대형 놀이공원은 절대 하루 만에 모든 놀이기구를 이용할 수 없지요. 하지만 한번 방문해보면 놀이공원이 어떻게 생겼고 어느 곳에 어떤 놀이기구들이 있는지, 다음에 방문한다면 무엇을 먼저 타면 좋을지에 대한 큰 그림은 그릴 수 있을 겁니다.
제 강의는 이렇게 놀이공원에 처음 방문하는 느낌으로 공부하시면 좋겠습니다. 머신러닝에 대해 모든 것을 알기는 어렵지만, 머신러닝이 무엇인지, 학습을 위해서 고려해야 할 부분이 무엇인지, 어떤 내용을 더 공부해보면 좋을지 감을 잡는 것이죠. 그러면 여기에서 한 걸음 더 나아가서 다양한 자료를 통해 더 깊은 지식을 쌓을 수 있게 될 겁니다. 함께 시작해볼까요?
여기에 이런 점들이 뿌려져 있습니다.
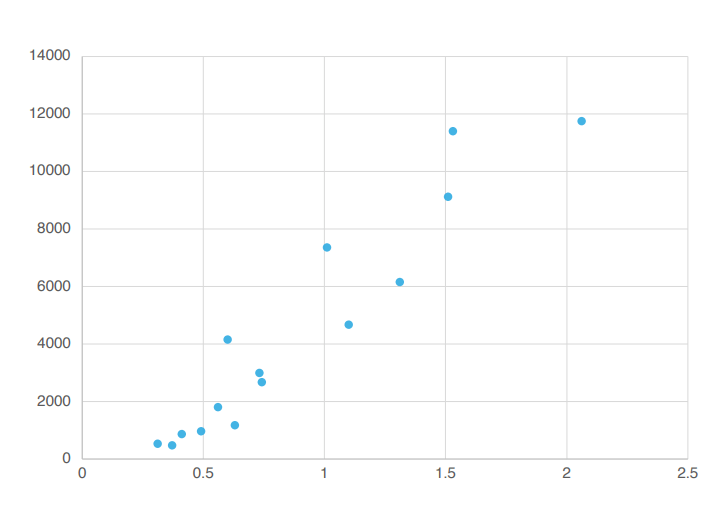
이때 이 점들을 가장 잘 표현하는 직선을 딱 하나 찾으라면 무엇일까요?
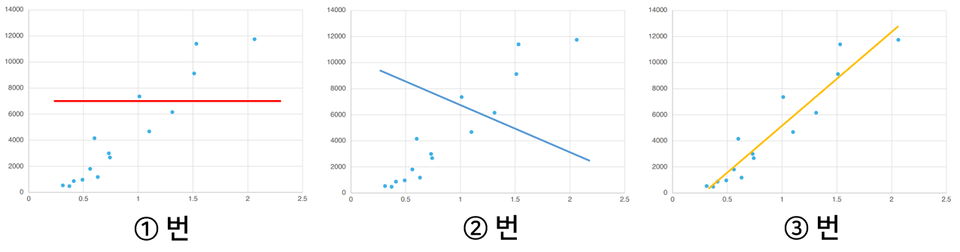
그렇죠! 바로 3번입니다. 왜 그렇게 생각하셨나요? 그렇습니다. 딱 봐도 그냥 그렇게 보이죠?
우리는 방금 기계가 스스로 학습을 통해 모델을 만드는 과정을 경험했습니다. 이러한 모델(여기서는 직선)이 만들어지고 나면 이제 예측이란 걸 해볼 수가 있습니다.
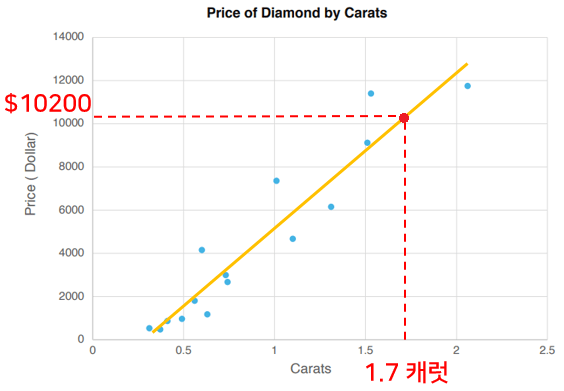
이 그래프가 캐럿에 따른 다이아몬드의 가격 데이터이고 x 축이 캐럿, y 축이 가격이라고 하면, 새로운 1.7 캐럿 다이아몬드가 있을 때 대략 얼마일지를 가늠해볼 수 있는 거죠. 이처럼 연속적인 숫자 데이터를 통해 예측하는 것을 회귀 모델이라고 합니다.
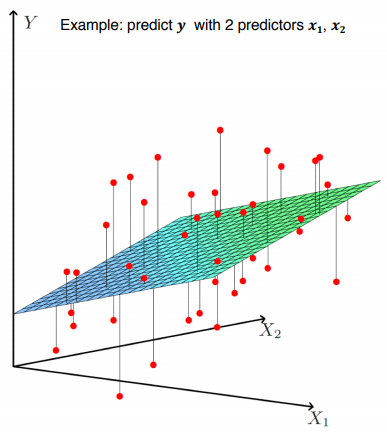
회귀 모델은 때에 따라 더 복잡해질 수도 있어요. 가령 공부 시간에 따른 시험 점수를 예측하려고 한다면, 점수에 영향을 끼치는 게 꼭 공부 시간 하나만 있는 건 아니겠죠? 이렇게 시험 점수라는 결과에 영향을 미치는 요소들을 독립 변수라고 하며, 그때의 결과를 종속 변수라고 합니다. 그리고 독립 변수가 많아지면 조금 더 복잡한 형태의 다중 선형 회귀 모델이 필요해집니다. 차원이 늘어나면서 그래프가 조금 복잡해진다고 생각하시면 됩니다.
무더운 여름철에는 오랫동안 에어컨을 사용하기가 무서워지는데요. 가정용 전기에는 누진 구간이 있어서 조금 사용하다 보면 전기료가 확 뛰고 그러다 보면 수십만 원을 훌쩍 넘는 경우도 생기지요. 누진 구간에 따라 막막 증가하는 데이터처럼 x의 변화에 따라 y가 급격히 변하는 등의 경우라면 직선 하나만으로 표현하기에는 다소 무리가 있습니다. 이때 다항 회귀 모델을 이용해볼 수 있어요.
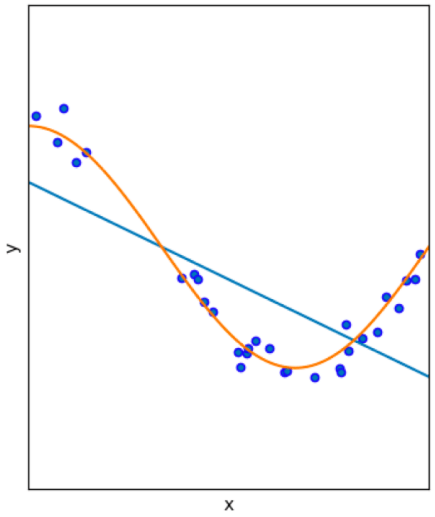
파란색 점들의 데이터를 표현하기 위한 2개의 모델이 있을 때, 직선의 하늘색보다는 곡선 형태의 주황색이 훨씬 낫지요!
그런데 이런 예측 모델들을 만들었을 때 정말 이게 잘 예측하는지는 어떻게 장담할 수 있을까요? 그래서 모델을 만들고 나면 이 모델의 성능이 얼마나 좋은지 평가해야 합니다. 그렇게 하기 위해서 데이터 세트 전체를 둘로 나눠서 하나는 훈련용으로 하나는 테스트용으로 쓰는데, 보통 80:20의 비율로 나눠서 훈련용 세트로만 학습을 시킨 다음에 모델이 괜찮은지를 테스트 세트로 검증해봅니다. 그리고 경우에 따라 세트를 섞어가면서 검증하기도 하지요.
이 과정에서 훈련 세트에 대해서는 정말 잘 예측하는데, 테스트 세트에 대해서는 형편없는 예측을 하는 것을 과대적합이라고 하며, 훈련 세트조차 예측을 잘 못하는 경우를 과소적합이라고 합니다. 모델을 만들 때 과대적합 또는 과소적합이 발생하지 않도록 하는 게 중요하지요.


이런 연속적인 데이터 말고 범주형 데이터라고 하는 것도 있습니다. 회귀가 아니라 분류에 해당하는 내용인데요. 공부 시간에 따른 시험 점수가 아니라, 이번에는 자격증 시험으로 바꿔서 합격/불합격으로 나뉘는 것으로 보시면 됩니다. 그래서 4시간 공부했을 때는 불합격, 6시간 공부했을 때는 합격했다는 데이터가 있을 때 7시간을 공부하면 합격일지 불합격일지를 나누게 되는 거지요.
머신러닝에서 대표적인 분류 알고리즘은 로지스틱 회귀입니다. 이름은 회귀이지만 실제로는 분류를 위해 사용되는 모델이며, 분류 모델은 필요에 따라 기준을 조금 조정하기도 합니다. 즉 모델에서는 '너 4시간 공부하면 합격하겠더라'라고 나온다고 해도 보수적으로 접근해서 '너 6시간은 공부해야겠더라'라고 말을 하는 거죠.
지금까지 설명된 내용은 머신러닝 중에서 지도학습에 해당하는 부분이었는데, 머신러닝에는 정답을 알려주지 않는 비지도 학습이란 것도 있습니다. 비지도 학습은 기계가 스스로 데이터 내에서 유의미한 패턴이나 구조를 찾아내는 건데, 이런 유사한 패턴을 보이는 데이터들끼리 무리를 지어주는 군집화라는 게 있습니다. 뉴스 기사들을 과학/기술, 스포츠, 건강 등의 카테고리로 나눠주는 것도 군집화의 한 예시입니다.
군집화의 대표적인 알고리즘으로 K-평균이라는 게 있는데요. 여러분이 과수원에서 처음으로 사과를 따서 상품으로 판매하기 위해 나눈다고 할 때, 어떻게 나누면 가장 좋을까요? 그냥 크기에 따라 큰 것과 작은 것, 이렇게 둘로 나눌 수도 있고 대/중/소 3개의 분류로, 또는 예쁜 것과 못난 것으로 나누어서 못난 것들은 싸게 파는 식으로 할 수도 있을 거에요.

이때 몇 개의 그룹에 해당하는 게 바로 K인데요. 사과가 아닌, 복잡하고 많은 양의 데이터를 군집화한다면 몇 개를 정하는 게 어려워질 수 있어요. 다행히 최적의 K를 찾기 위해 참고할 만한 방법이 있습니다. 팔꿈치 모양을 닮아서 엘보우 방법인데요. 간단히 설명해 드리면 K의 변화에 따른 각 데이터로부터 각 클러스터(그룹)의 중심점까지의 거리 평균을 계산해서, 그래프상에서 경사가 완만해지기 시작하는 그 시점을 K로 보는 것입니다.
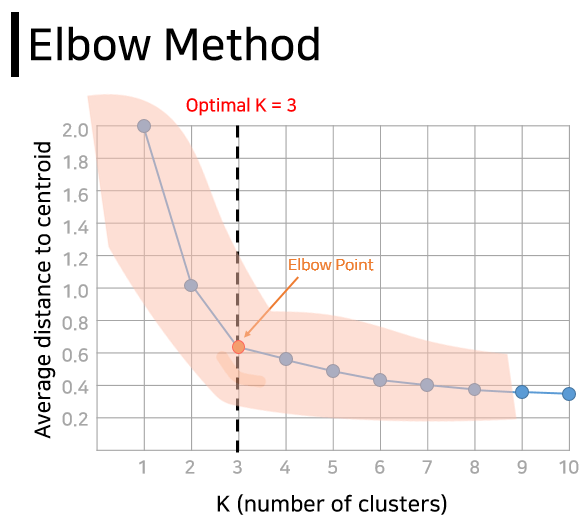
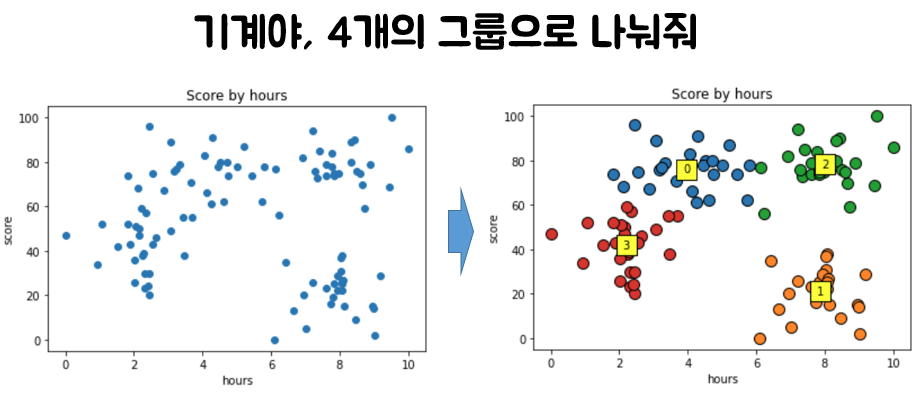
이렇게 K가 정해지면 우리는 아무렇게나 흩어져 있는 데이터로부터 아래와 같이 K개의 클러스터(그룹)로 나눠진 결과를 얻을 수 있게 되지요. 이 예시가 시험공부 시간에 따른 점수라고 한다면 각 그룹에 있는 친구들에게 서로 다른 공부 전략을 제공해줄 수도 있겠고요.
위에서 다룬 머신러닝의 기본적인 내용들은 자세한 이론 설명과 실습으로 공부하게 됩니다. 끝나면 퀴즈를 통해서 지금까지 배운 내용을 복습합니다.
퀴즈에서는 데이터 세트만 달랑 주어지고 그 데이터를 가지고 해야 하는 7가지 작은 미션들이 있는데요. 기본 내용을 잘 공부하셨다면 충분히 소화해내실 수 있습니다. 그리고 퀴즈를 스스로 풀 수 있다는 말은, 여러분이 스스로 데이터 분리, 훈련 세트를 통한 학습, 데이터 시각화, 평가 및 예측까지 할 수 있게 된다는 의미에요. 굉장하죠? 😃
퀴즈를 풀고 나면 이제 뭔가 써먹어 봐야겠죠! 다른 모든 활용편 강의들도 그랬듯이, 머신러닝 편에서도 프로젝트를 진행합니다. 프로젝트 주제는 영화 추천 시스템인데요. 약 5,000개의 영화 관련 데이터 세트를 가지고 분석 및 학습을 통해 추천 영화 10개를 뽑는 내용을 공부합니다. 추천의 방법에도 몇 가지가 있는데, 간단히 다음 3개를 공부합니다.
1. 많은 사람이 좋아하는 영화 추천
2. 어떤 특정 영화와 아주 비슷한 영화 추천
3. 개인의 영화 취향에 따른 맞춤형 추천
이 과정에서 텍스트 분석 방법에 대해서도 어느 정도 배우게 될 거고요. 그리고 코드만 보면 지겨우니까 streamlit이라고 하는, 몇 줄 안 되는 코드로 예쁜 웹페이지를 만들 수 있는 패키지를 통해 영화 추천 시스템 사이트를 직접 만들어봅니다. 여기에서는 어떤 영화를 선택하면 그 영화의 장르, 감독, 출연 배우 등의 정보를 토대로 추천 영화 10개를 뽑아서 한국어로 된 포스터 이미지를 짠~ 하고 보여준답니다. 그럴듯하죠?
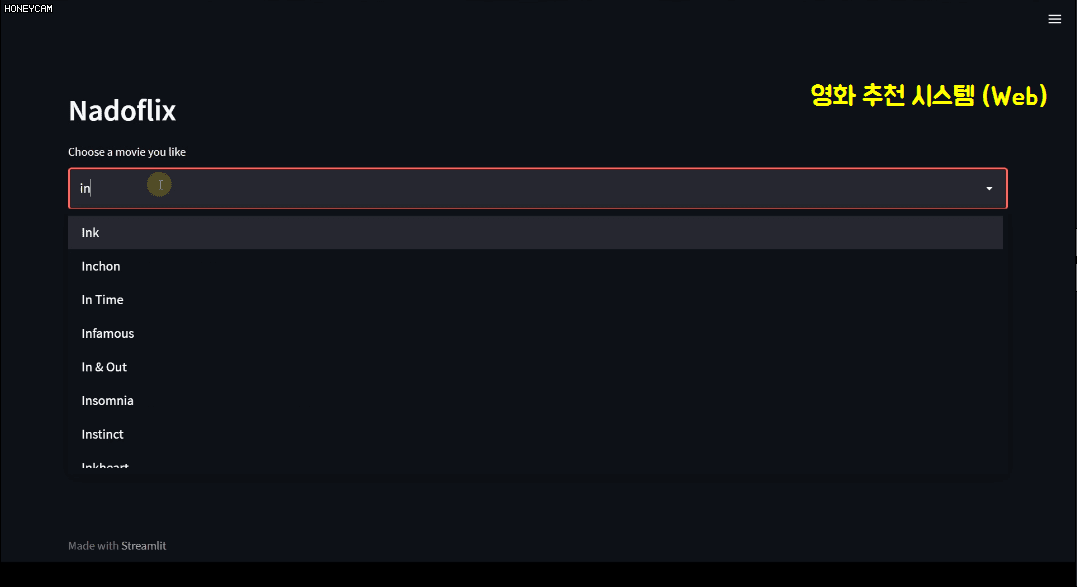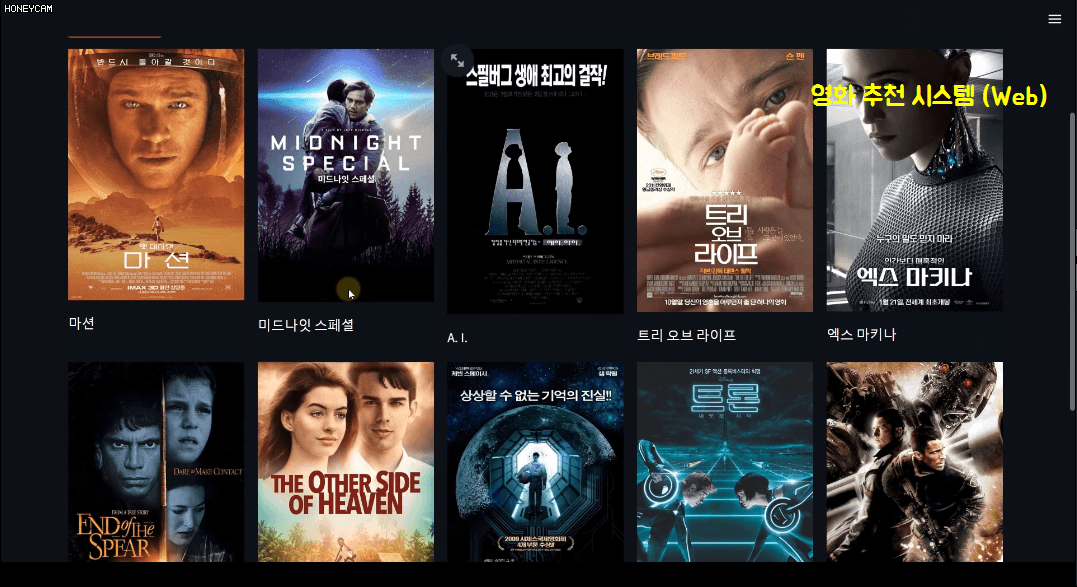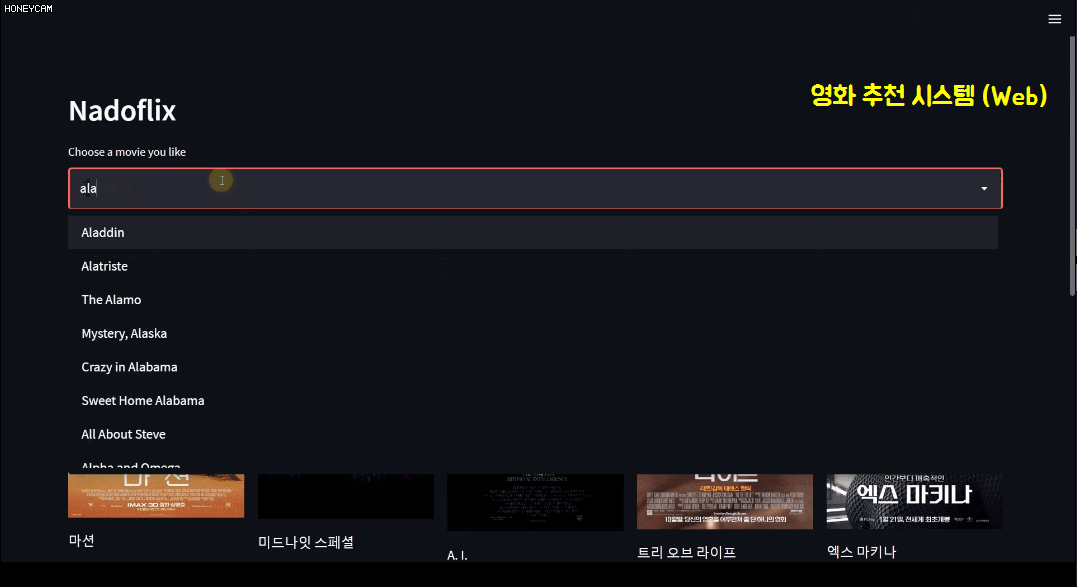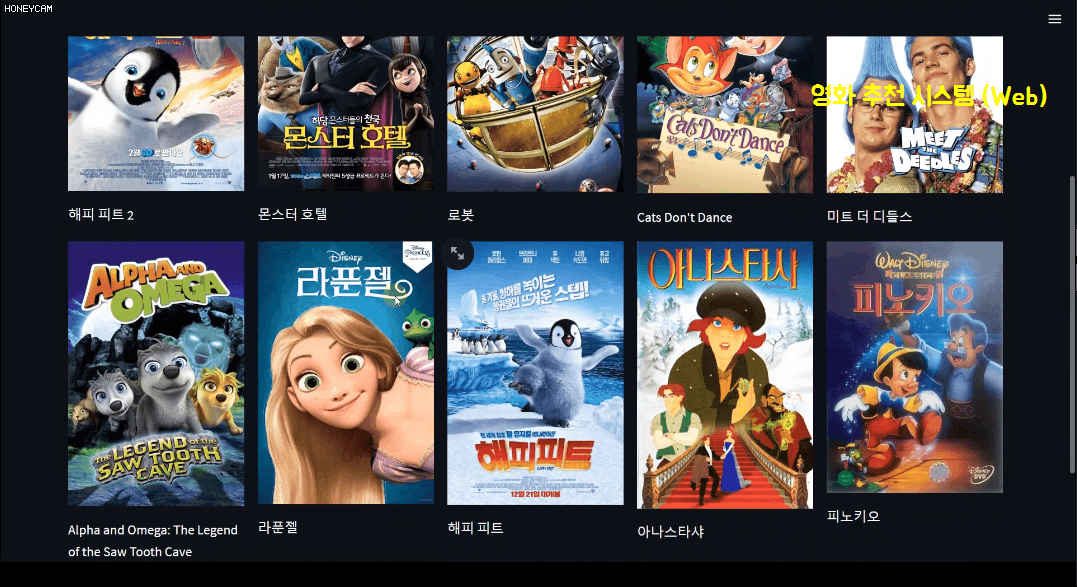
특히 마지막의 개인 영화 취향에 따른 맞춤형 추천은 Surprise라는 패키지를 이용하는데, 지금까지 쌓인 판매 이력 데이터를 통해서 어떤 고객에게 어떤 상품을 추천하면 좋을지, 어떤 물건들을 세트로 판매하면 더 잘 팔릴지 등에 대한 전략을 세우는 데 큰 도움이 될 수 있을 거예요.
Images, Videos by pixabay, pexels
: https://www.pixabay.com
: https://www.pexels.com
Designed by freepik, flaticon
: https://www.freepik.com
: https://www.flaticon.com
학습 대상은
누구일까요?
머신러닝이 어렵게만 느껴졌던 분들
정말 쉽고 상세한 설명이 필요하신 분들
이론을 넘어선 실전 프로젝트로 지식을 완성하고 싶은 분들
선수 지식,
필요할까요?
파이썬 기본 문법
주피터 노트북 기본 사용법
97,936
명
수강생
2,964
개
수강평
910
개
답변
4.9
점
강의 평점
11
개
강의
유튜브에서 코딩 교육 채널을 운영하고 있는 나도코딩입니다.
누구나 쉽고 재미있게 코딩을 공부하실 수 있도록 친절한 설명과 쉬운 예제로 강의합니다.
코딩, 함께 하실래요? 😊
🧡 유튜브 나도코딩
🎁 코딩 자율학습 나도코딩의 파이썬 입문
📚 코딩 자율학습 나도코딩의 C 언어 입문
전체
51개 ∙ (6시간 41분)
해당 강의에서 제공:
1. Intro
00:16
2. 활용편7 소개
01:46
3. 머신러닝 소개
01:59
5. 머신러닝 개요
10:30
6. 지도 학습
05:13
7. 선형 회귀
05:36
8. 선형 회귀 (실습 #1)
10:44
9. 선형 회귀 (실습 #2)
07:03
10. 데이터 세트 분리
02:09
11. 데이터 세트 분리 (실습)
13:42
12. 경사 하강법
06:31
13. 경사 하강법 (실습)
10:29
14. 다중 선형 회귀
02:14
15. 원-핫 인코딩
02:04
16. 다중 공선성
02:17
17. 다중 선형 회귀 (실습 #1)
06:39
18. 다중 선형 회귀 (실습 #2)
05:10
19. 회귀 모델 평가
12:17
20. 회귀 모델 평가 (실습)
04:34
21. 다항 회귀
07:37
22. 다항 회귀 (실습 #1)
06:13
23. 다항 회귀 (실습 #2)
13:12
24. 다항 회귀 (실습 #3)
05:11
25. 로지스틱 회귀
05:34
26. 로지스틱 회귀 (실습 #1)
11:04
27. 로지스틱 회귀 (실습 #2)
10:26
28. 혼동 행렬 (실습)
06:55
29. 비지도 학습
01:49
30. K-평균
10:04
31. 엘보우 방법
02:29
32. 유사도
04:41
33. K-평균 (실습 #1)
13:41
34. K-평균 (실습 #2)
06:42
35. K-평균 (실습 #3)
09:42
36. K-평균 (실습 #4)
06:50
37. 퀴즈
21:37
전체
46개
5.0
46개의 수강평
수강평 2
∙
평균 평점 4.5
수강평 3
∙
평균 평점 5.0
수강평 231
∙
평균 평점 5.0
수강평 1
∙
평균 평점 5.0
수강평 2
∙
평균 평점 5.0
무료




















![[PY 0201] 인공지능을 위한 파이썬 레벨1강의 썸네일](https://cdn.inflearn.com/public/courses/332643/cover/db98c954-be00-44ca-bd33-3cd69e290fff/Untitled.001.png?w=420)
![[PY 0204] 인공지능을 위한 파이썬 레벨3 - 함수강의 썸네일](https://cdn.inflearn.com/public/courses/333279/cover/eb80d90b-0359-4c7d-b9ee-f4997c35171d/333279.png?w=420)



![[PL 0301] 파이썬 가상환경과 아나콘다강의 썸네일](https://cdn.inflearn.com/public/courses/334755/cover/9d8ca8fb-2031-4dba-aa31-efb43963dba7/334755.png?w=420)


