실리콘밸리 엔지니어와 함께하는 데이터 사이언스 기초편
데이터로 세상을 읽는 법: 당신만의 데이터 과학을 탐험하세요! 현대 데이터 과학의 핵심을 이루는 도구와 기술을 깊이 있고 실용적으로 탐구합니다. 특히, 데이터 과학의 필수 요소인 Anaconda, Numpy, Pandas, 그리고 Scikit-learn을 사용하여 데이터를 분석하고 알고리즘을 구현하는 방법을 배웁니다.

초급자를 위해 준비한
[데이터 분석] 강의입니다.
이런 걸 배울 수 있어요
Scikit-Learn (사이킷런)
Pandas (판다스)
데이터 사이언스
이론과 실습을 모두 잡는 데이터 과학,
기초부터 분석 + 머신러닝까지!

데이터 과학, 어렵게만 느껴지셨나요?

✅ 데이터 과학에 관심 있는 학생
✅ 데이터 과학의 기초를 알고 싶은 누구나!
데이터 과학의 필수 요소인 Anaconda, Numpy, Pandas 그리고 Scikit-Learn을 사용해 데이터를 분석하고 알고리즘을 구현하는 방법을 배웁니다.
기초부터 고급 기술까지
- 데이터 과학의 기본 개념과 도구에 대한 이해가 부족한 초보자들이 체계적으로 학습할 수 있습니다.
- Anaconda, Numpy, Pandas, Scikit-learn 같은 필수 도구들의 사용법을 배우면서 기초부터 심화 지식까지 단계별로 습득할 수 있습니다.
실무 적용의 어려움을 해결
- 데이터 분석이나 머신러닝 모델을 실제 업무에 적용하는 데 어려움을 겪는 분들에게 실제 사례와 프로젝트 기반 학습을 제공합니다.
- 실무에 바로 적용 가능한 데이터 사이언스 기술을 익힐 수 있습니다.
복잡한 데이터 처리, 분석도 OK
- 대용량 데이터를 효율적으로 처리하고 분석하는 방법을 알려드립니다.
- Numpy와 Pandas를 통해 데이터 전처리, 분석, 시각화 기술을 배울 수 있습니다.
직접 구축하는 다양한 머신러닝 모델
- Scikit-learn(사이킷런)을 사용해 다양한 머신러닝 모델을 구축하고 최적화하는 방법을 배웁니다.
- 머신러닝 알고리즘을 이해하고 자체적으로 개발하는 데 어려움을 겪으셨다면 특히 도움이 됩니다.
이 강의만의 핵심 강점
우리는 Anaconda 환경 설정에서 시작하여, 데이터 처리와 분석의 기본이 되는 Numpy와 Pandas의 사용법을 꼼꼼히 다룹니다.
이를 통해 대용량 데이터셋을 효과적으로 다루고, 데이터 전처리 및 변환 과정을 숙달할 수 있습니다.
Scikit-learn을 활용한 머신러닝 알고리즘의 구현 방법도 실습을 통해 배울 예정입니다.
다양한 머신러닝 모델을 구축하고, 실제 데이터셋에 적용해 인사이트를 도출하는 경험을 얻어가 보세요!
 Anaconda 소개 및 설치
Anaconda 소개 및 설치
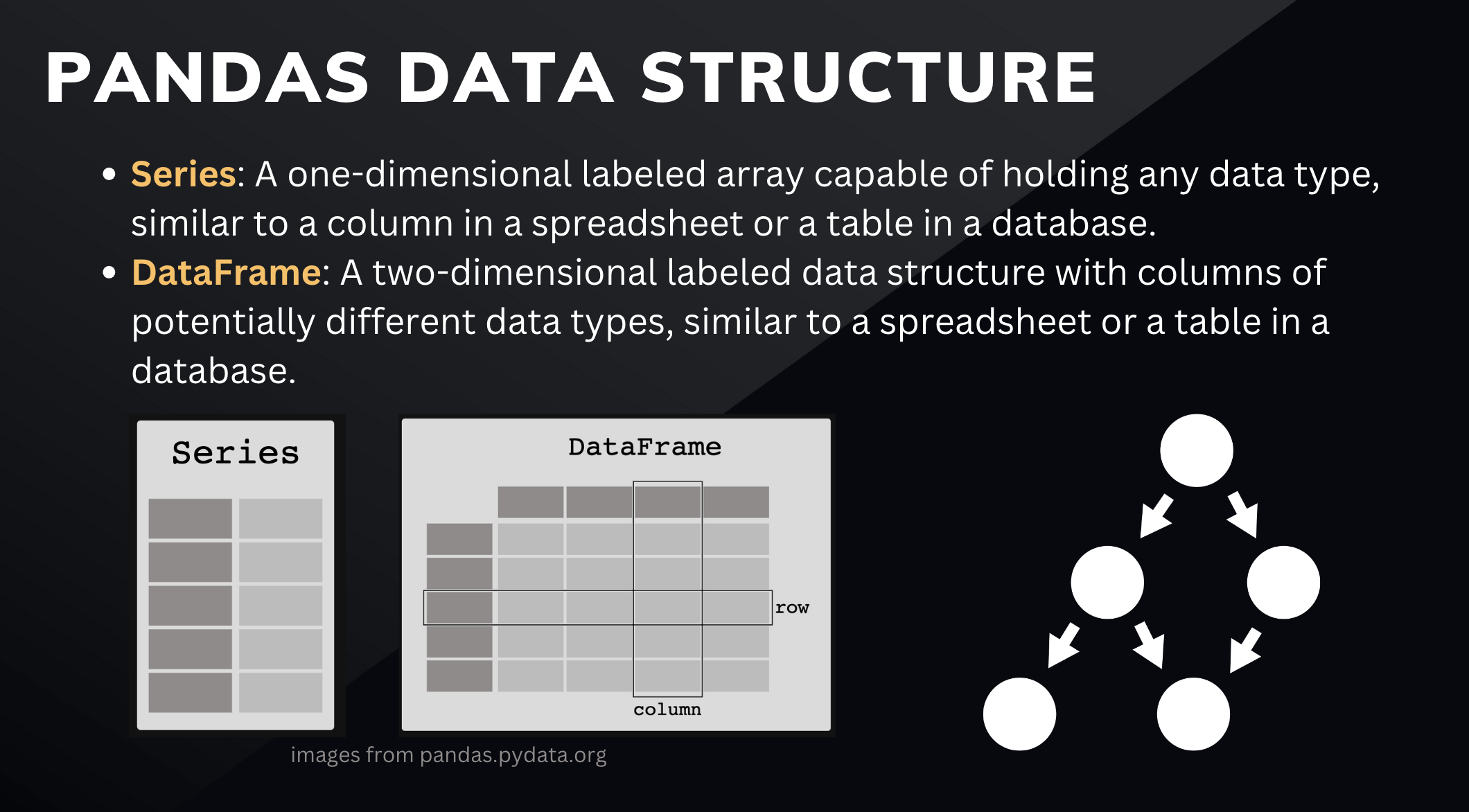 Pandas 데이터 구조 이해하기
Pandas 데이터 구조 이해하기
 Scikit-Learn 알아보기
Scikit-Learn 알아보기
이론으로 차근히, 실습으로 확실하게!
💡 이 강의는 이론과 실습을 병행하며, 각 모듈마다 실제 사례 연구와 프로젝트 작업이 포함되어 있어 실무에서 바로 적용 가능한 실력을 키울 수 있도록 설계되었습니다. 데이터 과학의 세계로의 여정을 시작하는 데 있어 이 강의가 훌륭한 길잡이가 되어 드릴 것입니다.
이 강의의 지식공유자
현직 실리콘밸리 엔지니어의 노하우를 그대로 전해드립니다!
저는 유튜브 "미쿡 엔지니어" 및 브런치 "실리콘 밸리 소식과 삶"을 운영하는 현직 소프트웨어 엔지니어입니다.
이력 사항
- 미국 University of California, Berkeley EECS 졸업
- 현 미국 실리콘밸리 글로벌 빅테크 기업 본사, 소프트웨어 엔지니어 (빅데이터 관련 업무)
포트폴리오/개인 영상
- 유튜브 "미쿡 엔지니어" 운영 중
- 브런치 "실리콘 밸리 소식과 삶" 운영 중
- 인프런 강의

Q&A 💬
Q. 왜 이 강의를 들어야 하나요?
이 강의는 데이터 과학의 기본 개념부터 시작해, Anaconda, Numpy, Pandas, Scikit-learn을 포함한 핵심 도구들을 실습을 통해 배울 수 있도록 구성되어 있습니다. 실무적인 데이터 분석 및 머신러닝 기술을 직접 경험할 수 있어, 이론과 실습을 통합적으로 학습하고 싶은 분들에게 이상적입니다.
Q. 이 강의를 듣고 나면 어떤 일을 할 수 있나요?
강의를 통해 배운 기술을 활용하여, 데이터 분석, 데이터 전처리, 시각화, 기본적인 머신러닝 모델의 구축 및 평가 등을 할 수 있습니다. 이는 비즈니스 인사이트를 도출하거나, 다양한 산업 분야에서 데이터 기반 의사 결정을 내리는 데 필수적인 역량입니다.
Q. 비전공자도 이 강의를 들을 수 있나요?
네, 가능합니다. 이 강의는 데이터 과학의 기본 개념부터 시작해 점차 심화 내용으로 나아가므로, 비전공자도 기본적인 컴퓨터 사용 능력과 수학에 대한 기본적인 이해만 있다면 충분히 따라갈 수 있습니다. 다만, Python 프로그래밍 언어에 대한 기본 지식이 있다면 강의를 더욱 효과적으로 수강할 수 있습니다. 수학적 배경 지식, 특히 통계학과 선형대수학에 대한 이해도 도움이 됩니다.
파이썬이 처음이시라면 유튜브를 통해 파이썬 기초를 학습하거나 아래 강의를 먼저 수강해주세요! 기초 부분만 보셔도 전체 강의를 따라오는 데 어려움은 없을 것입니다.
📢 실습 환경 및 자료 안내
Windows, macOS, Linux, Ubuntu 등 사용하는 PC 운영체제에 상관은 없지만, 강의는 macOS를 중심으로 진행됩니다. 상세 PC 사양은 아래와 같습니다.
- 프로세서(CPU) : 최소한 듀얼 코어 프로세서가 권장됩니다. 그러나 더 많은 코어를 갖는 프로세서는 데이터 처리 속도를 높이는 데 도움이 됩니다.
- 메모리(Memory) : 최소 4GB RAM이 필요하지만, 8GB 이상의 RAM을 권장합니다. 데이터 과학 작업은 종종 많은 양의 데이터를 메모리에 로드해야 하므로, 더 많은 RAM이 유리합니다.
- 저장 공간 : 충분한 하드 드라이브 또는 SSD 공간이 필요합니다. Scikit-learn 자체는 큰 공간을 차지하지 않지만, 사용할 데이터셋과 프로젝트 파일에 따라 상당한 저장 공간이 필요할 수 있습니다.
- 파이썬 버전 : Scikit-learn을 실행하기 위해서는 Python 3.6 이상이 필요합니다. 최신 버전의 Python을 사용하는 것이 좋습니다.
수강생에게는 PDF 형식의 강의 교안 및 Github을 통한 소스 코드를 공유합니다.
이런 분들께
추천드려요!
학습 대상은
누구일까요?
데이타 과학자가 되시고 싶은 분
데이타 과학의 기초를 공부하고 싶으신 분
선수 지식,
필요할까요?
Python (파이썬)
안녕하세요
미쿡엔지니어입니다.
7,546
명
수강생
350
개
수강평
277
개
답변
4.7
점
강의 평점
23
개
강의
한국에서 끝낼 거야? 영어로 세계 시장을 뚫어라! 🌍🚀
안녕하세요. UC Berkeley에서 💻 컴퓨터 공학(EECS)을 전공하고, 실리콘 밸리에서 15년 이상을 소프트웨어 엔지니어로 일해왔으며, 현재는 실리콘밸리 빅테크 본사에서 빅데이터와 DevOps를 다루는 Staff Software Engineer로 있습니다.
🧭 실리콘 밸리의 혁신 현장에서 직접 배운 기술과 노하우를 온라인 강의를 통해 이제 여러분과 함께 나누고자 합니다.
🚀 기술 혁신의 최전선에서 배우고 성장해 온 저와 함께, 여러분도 글로벌 무대에서 경쟁할 수 있는 역량을 키워보세요!
🫡 똑똑하지는 않지만, 포기하지 않고 꾸준히 하면 뭐든지 이룰수 있다는 점을 꼭 말씀드리고 싶습니다. 항상 좋은 자료로 옆에서 도움을 드리겠습니다
커리큘럼
전체
26개 ∙ (5시간 29분)
해당 강의에서 제공: