👋🏼 멘토 소개
안녕하세요 :) 문과생으로 대기업에 취업해 8년차 임베디드(반도체) SW 개발자입니다.
개인 유튜브 채널을 통해 코딩테스트와 취업 전반의 콘텐츠를 다룬 덕분에 프로그래머스/엘리스에서도 코딩테스트 입문 강의를 제작하고 수강생분들을 상담하고 있는 크리에이터입니다.
제 콘텐츠와 상담 방향이 궁금하신 분들은, 제가 유튜브 댓글로 상담 드린 아래의 사례들과 유튜브 채널에 올리는 취업 관련 콘텐츠를 참고해보셔도 좋을 것 같습니다!
유튜브 링크 : https://www.youtube.com/@gaebal
✅ 유튜브 댓글 상담 사례 1
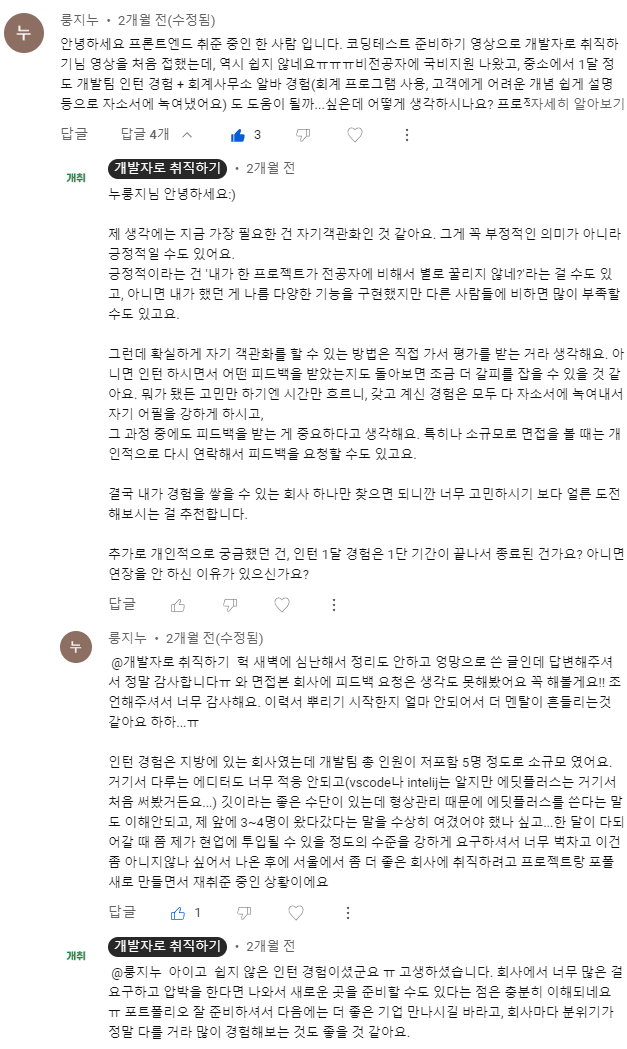
✅ 유튜브 댓글 상담 사례 2
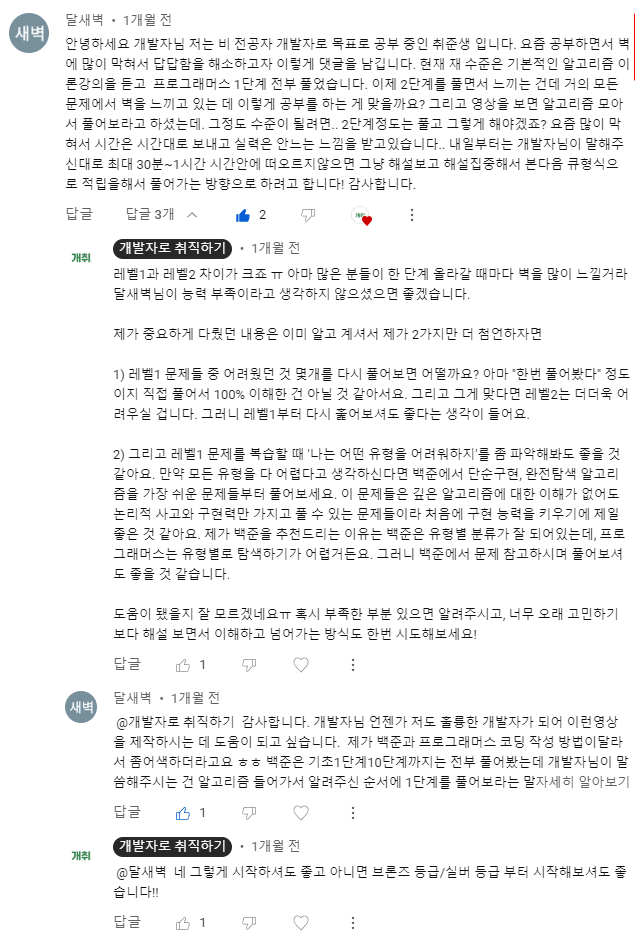
✅ 유튜브 댓글 상담 사례 3
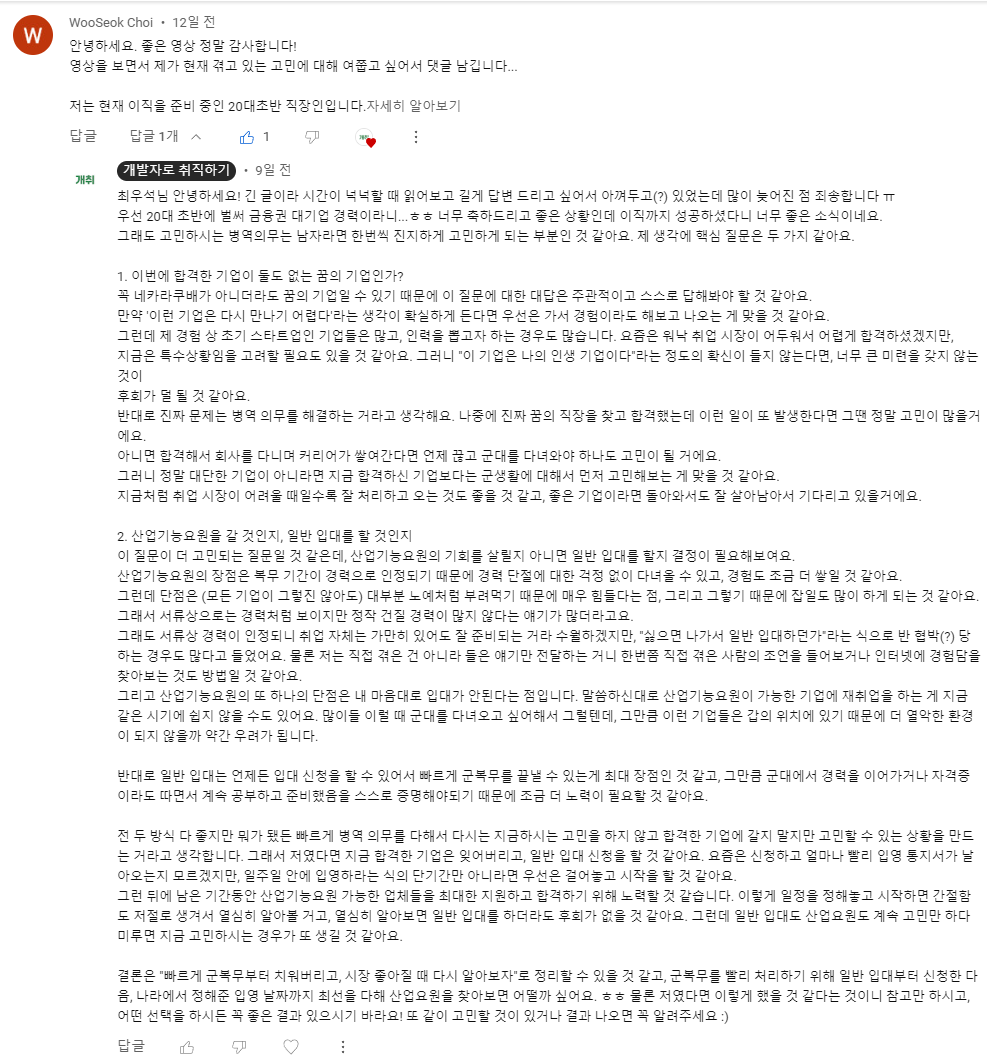
🏃🏻♀️ 가능한 멘토링 분야 및 진행 방식
- 코딩테스트 1:1 과외
- 프로그래머스 / 백준에서 코딩테스트 문제를 풀며 문제가 잘 안 풀리거나 어떻게 접근해야 할지 전략을 세우기 어려운 분들을 위한 1:1 과외를 제공합니다.
- 어려웠던 문제를 상담 신청 시 알려주시면 구글밋을 통해 온라인으로 자세하게 설명해 드립니다.
- 멘토링 세션 당 1개 문제를 설명해 드리고, 실제 상담 시간은 30분을 초과해도 한 문제에 대해서 최대한 설명해 드리니, 시간이 부족할 걱정은 하지 않으셔도 됩니다!
- 설명 가능한 언어는 Python/Java/C/C++ 입니다.
- 외안되?! - 내 코드가 죽는 이유 대리 디버깅
- 가끔 문제를 풀다 보면 "정답이랑 똑같은데 이게 왜 틀렸지?!"라고 답답하신 경우들 있으시죠? 이런 분들을 위해 전체 코드를 대신 분석해 드리는 상담입니다 :)
- 멘토링 세션 당 최대 2개 문제를 선택하셔서 질문 주시면, 이메일을 통해서 어디가 왜 틀렸는지, 그리고 이런 실수를 다시 하지 않기 위해서 주의할 부분들에 대해서 짚어드립니다.
- 프로그래머스 / 백준에 있는 문제는 모두 가능하고, 언어는 Python/Java/C/C++까지 가능합니다!
- 대기업 취업/커리어 상담
- 문과생/비전공자가 개발자로 취업하며 겪는 고충에 대해 상담해드리고, 당연히 전공자 분들도 상담 가능합니다!
- 부트캠프를 가야할까요? 독학할까요?
- 코테 실력이 늘지 않는데 어떻게 하면 좋을까요?
- 어떤 언어로 코딩테스트를 준비해야 할까요?
- 프로젝트와 포트폴리오는 어떻게 준비해야 할까요?
- 멘토링 신청 시 본인의 현 상황/경력/대학 학점 등을 최대한 구체적으로 말씀해 주시면, 그 상황에 맞게 구글밋을 통해 상담해 드립니다!
- 대기업 자기소개서 첨삭 및 컨설팅
- 대기업/중소기업에 제출할 자기소개서를 첨삭해 드리고 멘티분의 취업 컨셉을 잡도록 도와드립니다.
- 회사의 입장에서 취업은 유능한 인재를 선출하는 과정이기 때문에, "나"라는 개발자는 어떤 장점이 있는지 잘 부각시키는 것이 중요합니다.
- 본인의 장점이 자소서에 잘 묻어나올 수 있도록 컨셉과 전략을 잡아드리고, 최종 제출 전 마지막 최최최종 첨삭을 원하시는 분들을 위해서는 첨삭을 진행해 드립니다!
- 컨셉/전략 등 상담이 필요한 분들은 구글밋을 통해 온라인으로 상담을 진행합니다.
- 자소서 첨삭이 필요한 분들은 멘토링 신청 시 전달해 주신 자소서를 이메일을 통해 첨삭하여 전달해 드립니다!
- 현재 상황을 자세하게 설명해주시면 그만큼 더 깊이 있는 상담을 할 수 있으니 되도록 많은 내용 전달해주시면 좋습니다 :)
🔎 진행 방식
멘토링이 확정되면 구글밋 링크를 제공해 드려, 구글밋을 통한 화상회의 상담을 기본으로 하고 있고, 저도 현업에서 근무 중이라 얼굴은 나오지 않고 상반신만 나오는 상태에서 상담을 진행합니다.
간혹 온라인 상담보다 이메일/댓글 상담을 선호하시는 분들도 있어서, 원하신다면 이메일 상담도 가능합니다. 동일한 내용을 글로 정리하여 전달해 드리고 있으니 원하시는 분들은 이메일로 답변 달라고 해주시면, 정해진 멘토링 세션까지 답변드리겠습니다!
📚 멘토링에 필요한 준비
- 4개 상담 항목 중 어떤 항목을 원하시는지 알려주세요!
- 구글밋 상담 혹은 이메일/댓글 상담 중 원하시는 방법을 선택해 주세요! (이메일/댓글을 원하시는 경우 이메일 주소도 알려주세요)
- 문제 풀이 관련 상담을 원하신다면 프로그래머스/백준 문제의 링크를 첨부해 주시고, 본인이 고민했던 내용을 최대한 적어주세요. 어떤 부분에서 잘못 생각했는지 알면 훨씬 더 쉽게 설명해 드릴 수 있습니다!
- 커리어 상담/자소서 첨삭을 원하신다면 현재 상황에 대해서 최대한 자세하게 말씀해 주세요! 학력, 전공, 학점, 경력 등 공개 가능한 부분까지 최대한 알려주세요. 개인 정보는 양질의 상담을 위해 참고하고 전부 삭제하고 있으니 공개할 수 있으신 범위 내에서 최대한 알려주세요 :)

![[파이썬/Python] 문과생도 이해하는 DFS 알고리즘! - 입문편강의 썸네일](https://cdn.inflearn.com/public/courses/331842/cover/bc65732d-d4df-4d03-b804-625dbd6b1a83/331842-eng.png?w=420)
![[자바/Java] 문과생도 이해하는 DFS 알고리즘! - 입문편강의 썸네일](https://cdn.inflearn.com/public/courses/331159/cover/69d7b62d-e089-4f30-8c48-f8f7c8186ea4/331159-eng _v2.png?w=420)
![Thumbnail image of the [자바/Java] 문과생도 이해하는 DFS 알고리즘! - 입문편](https://cdn.inflearn.com/public/courses/331159/cover/69d7b62d-e089-4f30-8c48-f8f7c8186ea4/331159-eng _v2.png?w=148)
![Thumbnail image of the [파이썬/Python] 문과생도 이해하는 DFS 알고리즘! - 입문편](https://cdn.inflearn.com/public/courses/331842/cover/bc65732d-d4df-4d03-b804-625dbd6b1a83/331842-eng.png?w=148)