인프런 커뮤니티 질문&답변
작성한 질문수

[섹션6] 작업형2 모의문제2 mape 평가 관련 질문입니다.
해결된 질문
작성
·
441
1
안녕하세요~ 계속 반복한 끝에 미숙하게나마 직접 데이터를 가공해서 모델을 만들어서 돌려보는 데까지 성공했습니다. 정말 좋은 강의 감사합니다.
저 같은 경우에는
name, host_id, host_name, last_review, reviews_per_month 이런 결측치가 많거나 object인 컬럼들은 모두 날려줬고
LabelEncoer, MinMaxScaler를 사용해서 피처엔지니어링을 해줬습니다.
그렇게 해서 평가에 사용한 모델은 RandomForestRegressor 고요.
다른 결과치들은 선생님께서 방송 중에 만들어주신 모델에 비해서 살짝 살짝 낮지만… 그래도 결과값이 나오긴 나와서 다행이라고 생각하고 있는데요.
(정말 고맙습니다!) 딱 하나 아래 mape 요 놈은 결과값이 inf로 나옵니다.
MAPE(Mean Absolute Percent Error)
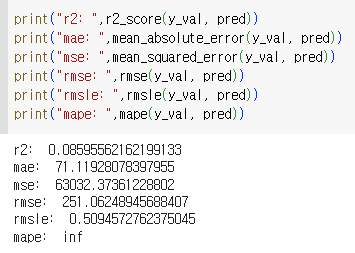
요건 Inf - 아마 무한대겠죠?
분모에 해당하는 수가 0에 가까워서 그런 게 아닐까 싶기도 한데요. 이 평가지표를 쓰라고 한다면 MinMaxScaler는 쓰면 안 되는 걸까요? 요게 영향을 주지 않았을까 싶어서요. 출근을 해야해서 일단 생각을 여기까지 해보고 퇴근하고 다시 올려보겠습니다.
랜덤포레스트 모델하고 LightBGM 요렇게 두 가지만 쓰려고 작정하고 준비하고 있습니다.
그럼~
답변 1
1
안녕하세요:)
와우!! 출근 전 학습 멋져요!! :)
MAPE의경우 분모가 0일경우 계산이 되지 않아 예를들면 0을 0.0001등 로 변경하는 방식을 사용하기도 합니다
이 부분은 크게 신경쓰지 않아도 될 것 같아요~ target에 0이 있다면 출제될 가능성은 희박합니다.
저도 같은문제로 이래저래 고민을하다diff = y_val - pred
y_val[y_val == 0] = 0.0000001print('mape:', np.mean(abs(diff/y_val))*100)
다음과 같이 변경하여 계산하니 답은 나오는데요
제가 궁금한건 시험에서 mape를 구해야 하는 문제일경우
test데이터의 답 (target)은 수험자의 영역에선 알수없고 수정도 할수없으니 0이 포함되어 inf가 출력되도록 문제가 출제될 일은 거의 없다는 말씀이신걸까요??
네 잘 알겠습니다. 고맙습니다. 작업형 2는 선생님 덕분에 큰 걱정이 안 됩니다. ㅎ