
인프런 커뮤니티 질문&답변
작성한 질문수 8

선생님 gpu->cpu 속도 개선에 대해서 질문드려요
해결된 질문
작성
·
513
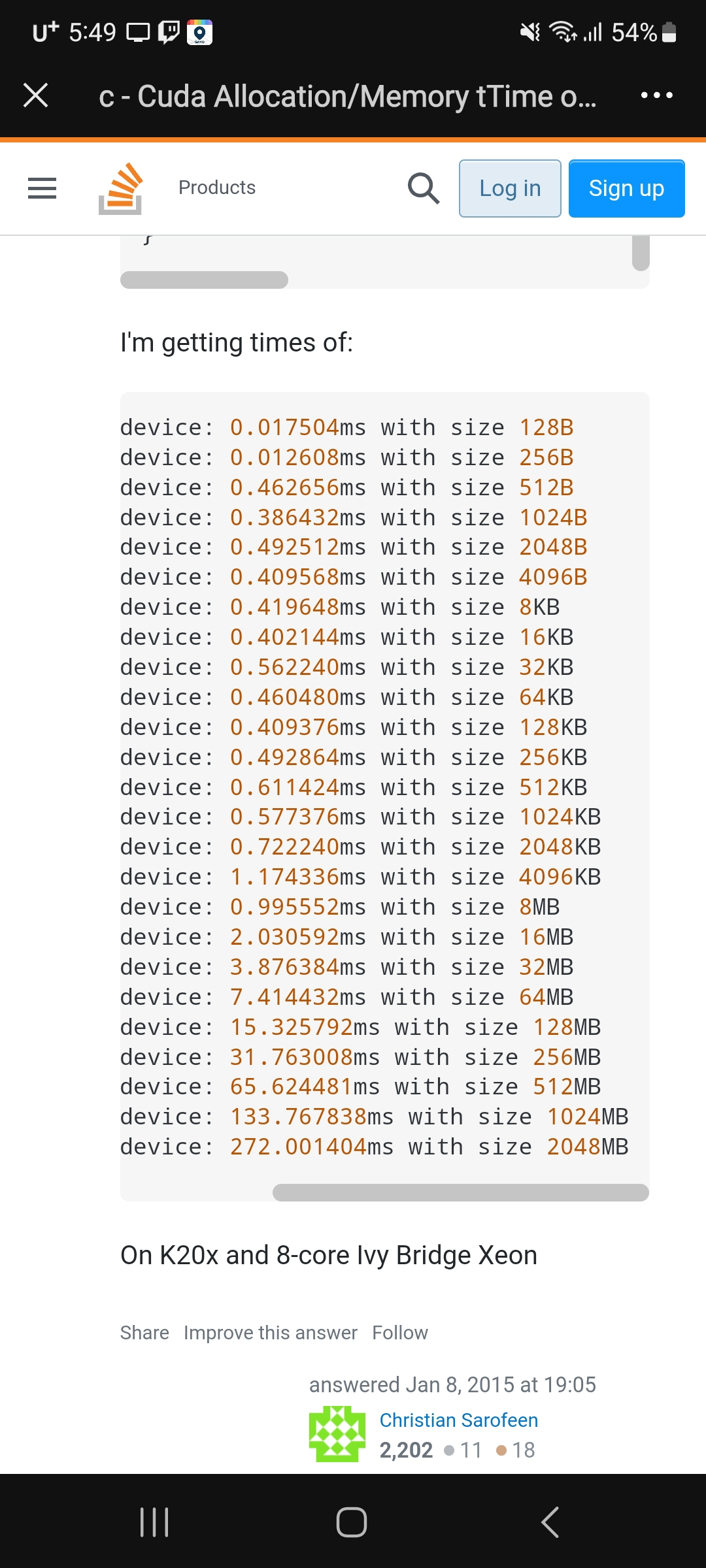
답변 1
0
안녕하세요.
우선, 알고 계시겠지만, 코딩 쪽의 문제는 재현이 힘든 경우도 있고,전혀 다른 것이 원인인 경우도 있어서, 말씀 드리는 내용이 꼭 정답은 아닐 수도 있습니다.
VRAM - RAM 간의 전송은 CUDA 에서는 주로 cudaMemcpy 함수를 사용하게 되는데, 함수 자체는 효율성이 보장되는 편입니다.
다만, 이 함수의 수행 시간을 보면, (준비작업) + (실제 copy) + (종료처리) 가 걸리게 되고,
일반적인 C/C++ 함수보다도 (준비작업) 에 시간이 더 걸릴 수 있습니다.
CPU, RAM, GPU, VRAM 모두의 충돌을 피해야 하니까, copy 작업 전에, 모두가 copy 해도 문제 없다는 것이 확실해야 copy가 일어날 겁니다. (특정 memory 영역을 서로 읽고, 쓰려는 쓰레드들이 경쟁하고 있다면, 다른 쓰레드들을 pending 시키고, copy 하고 다시 resume 시키고 한다는 점을 유의하셔야 합니다. VRAM-RAM 간의 버스도 서로 경쟁하는 상황이 생길 수 있습니다.)
그래서, 어차피 copy 할 거라면, 큰 사이즈를 한번에 copy 하는게 더 효율적 일 수 있습니다.
아니면, 최소한 일정 크기 이상의 데이터를 모아서 copy하는 방법도 고려해 볼 수 있습니다.
다음에, 데이터를 전부 생성하는데 시간이 많이 걸린다면, 일부만 생생해도 copy 를 시도하는 cudaMemcpyAsync 함수가 있습니다만,
이쪽은 동영상 강의에서는 cover 하지 않고 있습니다. (강의 분량상,이 부분이 커트 되었습니다. ㅠㅠ)
매뉴얼을 참고해서, 지금 구조를 변경하는 것도 가능하겠지만, 실제 속도 면에서는 크게 이득을 보지는 못할 겁니다.
copy 작업을 분산시키는 정도의 기능으로 봐야할 겁니다.
메모리 쪽은 의외의 원인이 있을 수 있어서, 여러가지로 검토를 해 보셔야 할 겁니다.
특히, 되도록 이면, 한쪽은 write 만 하고, 다른 쪽은 read 만 하는 구조로 해야 충돌이 줄어들어서 효율적이 될 겁니다.
도움이 되셨기를 바랍니다.
감사합니다.