인프런 커뮤니티 질문&답변
작성자 없음
작성자 정보가 삭제된 글입니다.

[FPGA 22장] 전체 HW 연산 시간 관련 질문드립니다.
해결된 질문
작성
·
430
1
안녕하세요 맛비님. [FPGA 22장] 프로젝트 Fully Connected Layer 설계 - 실습편 강의 중 질문사항이 생겨 문의드립니다.
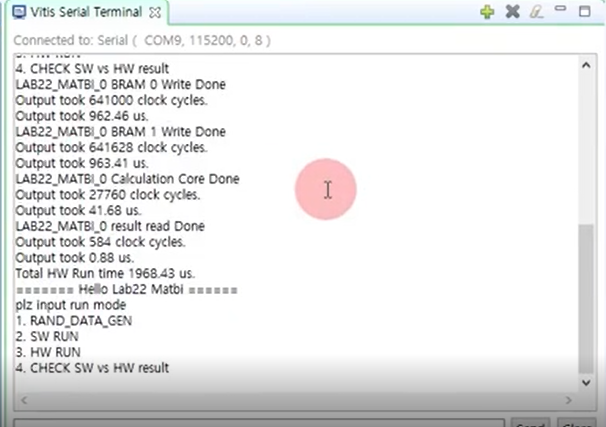
HW 가속기의 연산 시간은 BRAM 0에 input을 넣는 962 us + BRAM 1에 weight를 넣는 963 us + fc 연산 41.68 + 결과값 받아오기 0.88 us 여서 총 1968 us 라는 점 이해 잘 됐습니다.
BRAM 0과 BRAM 1에 데이터를 넣는 과정은 순차적으로 (bram 0에 다 넣고, bram 1에 넣기 시작) 진행되는거라서 둘의 연산 시간을 더해주는 건가요? 그렇다면 두 연산을 병렬로 처리할 수는 없나요? HW 가속기의 장점은 병렬연산이 가능한 것인데, 혹시 AXI를 통해 PS에서 BRAM으로 데이터를 전송하는 과정들은 병렬 처리가 불가능한건지 궁금합니다.
전체 run의 수를 늘려서 output node의 수를 4개가 아닌 더 많이 생산할 수 있다고 배웠습니다. 이때 run을 1024번을 하여 output node를 4096개 만드는 경우, 맛비님께서 전체 HW 연산 시간에서 BRAM 0에 input을 넣는 시간인 962.46us는 배제해도 된다고 하셨습니다. (나머지 3개 연산 시간만 더하면 그게 전체 HW 연산 시간이라고 들었습니다.) 하지만 해당 부분을 배제하면 안되는 것 아닌가요? (혹시 1024번의 RUN을 실행하면 962.46us 너무 작은 숫자라 배제해도 된다는 뜻인건가요..?)
항상 좋은 강의 제작해주셔서 감사합니다. 새해 복 많이 받으세요!
답변 1
0
안녕하세요 :)
BRAM 0과 BRAM 1에 데이터를 넣는 과정은 순차적으로 (bram 0에 다 넣고, bram 1에 넣기 시작) 진행되는거라서 둘의 연산 시간을 더해주는 건가요? 그렇다면 두 연산을 병렬로 처리할 수는 없나요? HW 가속기의 장점은 병렬연산이 가능한 것인데, 혹시 AXI를 통해 PS에서 BRAM으로 데이터를 전송하는 과정들은 병렬 처리가 불가능한건지 궁금합니다.
병렬처리 가능합니다.
Data loading 시간이 너무 길기 때문에 문제가 되는 것으로 판단이 되고요.
가능합니다. Double buffering 이라는 기법을 사용하면 됩니다. 요지는 core 를 쉬게 하지 않는 것입니다. 다음 방법을 적용하려면 SW 단의 thread 또한 필요합니다.
예를 들면, 기존의 BRAM0, BRAM1 구조에서, BRAM_0_0, BRAM_0_1, BRAM_1_0, BRAM_1_1 구조로 HW 를 변경합니다. 필요하면 buffer 의 개수를 더 늘리는 방법이 있겠습니다.



위와 같이 (글씨가 이상하지만) SW 와 HW 가 바라보는 BRAM 영역을 switching 해주면 됩니다.
하지만 위 방법 만으로는, 현 예제에서 속도 개선이 되지않습니다.
현재는 SW 에서 BRAM 에 값을 읽어가고, 쓰는 과정이 bottle neck 임으로 그것을 먼저 해결하는 것이 performance 를 올리는데 더 중요합니다. 결국 느린쪽으로 performance 는 align 이 됩니다.
결론은 SW 는 thread 가 필요하고, HW 는 충분한 buffer 를 확보하면 쉬지 않고 병렬처리 할 수 있습니다. 이 예제에서는 병렬처리도 문제이지만 가장 시급한건, SW 의 BRAM 접근 시간을 개선하는 것이 문제입니다. 그 bottle neck 을 해결하면 됩니다. AXI4-Lite 대신 다른 I/F 적용이 필요합니다. 이 부분은 Verilog HDL Season2 에서 다룰 예정입니다.
전체 run의 수를 늘려서 output node의 수를 4개가 아닌 더 많이 생산할 수 있다고 배웠습니다. 이때 run을 1024번을 하여 output node를 4096개 만드는 경우, 맛비님께서 전체 HW 연산 시간에서 BRAM 0에 input을 넣는 시간인 962.46us는 배제해도 된다고 하셨습니다. (나머지 3개 연산 시간만 더하면 그게 전체 HW 연산 시간이라고 들었습니다.) 하지만 해당 부분을 배제하면 안되는 것 아닌가요? (혹시 1024번의 RUN을 실행하면 962.46us 너무 작은 숫자라 배제해도 된다는 뜻인건가요..?)
이 부분은 제가 정확히 이해한 것인지 모르겠으나, (아래 예제의 숫자가 너무 커서 혼란이 될 순 있는데, 의미만 이해 부탁드립니다.)
만약에 input node 가 1024개 이고, output node 는 4096 입니다.
연산에 필요한 weight 의 개수는 1024 * 4096 입니다.
즉 input node 는 fix 입니다. weight 만 바꿔가면서 output node 의 값을 구할 수 있습니다.
추가적인 input node 의 update 과정은 필요가 없음으로 해당 내용을 말씀드린 것으로 기억합니다.
영상의 37분대 인것 같네요.
즐공하세요 :)