인프런 커뮤니티 질문&답변
작성한 질문수

to_csv() 한글 깨짐
작성
·
657
0
dataframe 변수, df 에 naver 일별 주가 데이터가 있는 상태에서,
df.to_csv("data.csv")를 해서 만든 data.csv를 열어보면,
한글 컬럼명들이 캐져 있습니다.
1. to_csv("data.csv", encoding="utf-8-sig" ) 이렇게 해주니 깨지지 않았습니다. 동영상에서는 이걸 따로 설정 안해도 깨지지 않았는데 왜 그런걸까요? 한글이 있으면, to_csv()를 사용할 때마다, encoding을 해주어야할까요?
2. df.set_index("날짜")를 하여 "날짜"가 index가 되도록 한 후에, df.to_csv(..)를 해서, 만들어진 data.csv를 열어보면,
정수 index가 자동으로 붙어서 파일이 만들어져 있습니다. 그러니까, "정수 index", "날짜", "종가", ... 이런식으로 되어있죠. to_csv를 하면 정수 index가 자동으로 붙는 것이 기본인가요?
강의 동영상에서는 정수 index가 붙어있지 않던데 왜 그런걸까요?
답변 2
0
2번 질문은 해결했습니다. df.set_index("날짜")를 한 후에, df에 다시 세팅을 해줘야 하는데 안해서 생긴 문제였습니다.
1번: 저는 윈도우10 사용자입니다.
df.to_csv()를 해서 만든 csv 파일을 엑셀에서 열면, 한글컬럼명이 깨져있고, 컬럼 갯수도 1개 모자라네요.
그런데, read_csv를 해보면, 한글 컬럼명이 깨지지 않았습니다.
이상하네요...
******** 방금 csv 파일을 메모장으로 열어보니, 한글이 깨지지 않았습니다. 엑셀 문제인가 봅니다..
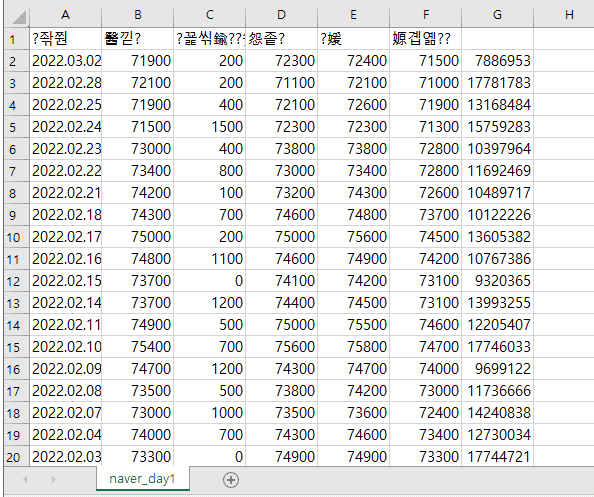
(1) df.to_csv("naver_day1.csv")
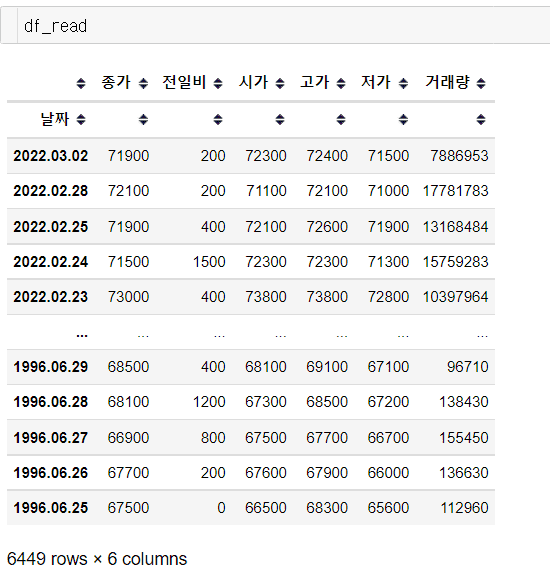
(2) df_read = pd.read_csv("naver_day1.csv", index_col="날짜")
0
1. 혹시 윈도우 사용자이신가요? 기본적으로 to_csv 시 utf8이 적용되기 때문에 깨지는 현상이 없는것이 정상입니다. jupyter에서 read_csv로 그대로 읽었을 때도 한글이 깨지는지 판단해보시겠어요?
2. set_index를 설정하면 정수index는 따로 붙지 않습니다. 해당 코드와 결과 스샷 첨부해주시면 더 정확한 판단 가능할 듯 합니다.
감사합니다.
안녕하세요!
맞습니다. 해당 부분은 엑셀 혹은 메모장 등 파일을 여는 프로그램의 인코딩 문제입니다.
각 응용프로그램의 인코딩 바꾸는 방법(utf8, euc-kr 등)을 구글링 검색해서 적용하시면 정상적으로 보일것이라 판단됩니다.
감사합니다.