인프런 커뮤니티 질문&답변
작성한 질문수

말씀하신 부분중 궁금한게 있어서 문의남깁니다.
작성
·
178
0
1.4 테슬라 컴퓨터 비전 얘기를 하실때
7분 쯔음에 다수의 카메라가 동일한 물체를 표현할때 각기 다른 파트에 집중해서 CNN만으로 정보를 조합해서 우리가 만들어 놓은 공간으로 맵핑이 어렵다고 말씀하셨는지
왜 어려운지 이해가 안돼서 문의 남깁니다.
감사합니다.
-이아름 드림
답변 1
0
딥러닝호형
지식공유자
안녕하세요. 아름님!
좋은 질문 감사드립니다.
테슬라에서 소개한 바로는 카메라로부터 받은 데이터들을 특정 벡터 공간으로 projection을 시켜서 우리가 원하는 문제를 해결하는 방식입니다. 따라서 어떻게 피쳐를 image space에서 vector space로 변환할지가 중요합니다.
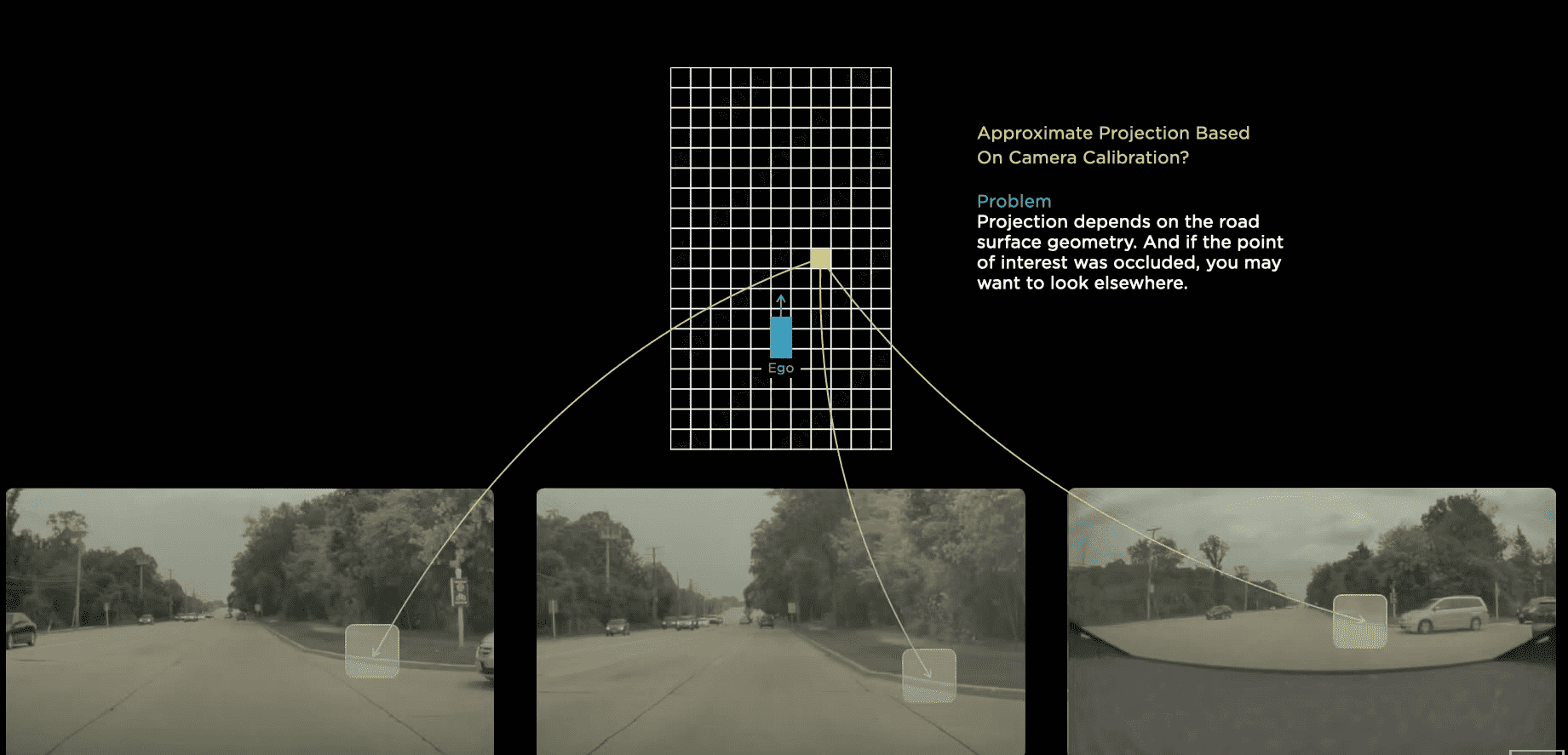
예를 들어 버드뷰(위에서 내려다보이는 맵)를 표현하고자 할 때 특정 물체가 있는 위치를 한 점으로 나타낼 수 있을 것입니다. 하지만 image space에서 같은 물체가 표현되는 점은 카메라마다 다르기도 하고 projection은 도로 상태에 따라 달라지기 때문에 고정된 transformation을 사용하여 projection하기 어렵습니다. 따라서 포지셔널 임베딩과 어텐션으로 구성 된 transformer를 이용하여 CNN으로 부터 얻어진 피쳐를 재표현하게 됩니다.