인프런 커뮤니티 질문&답변
작성한 질문수

마지막 부분 이해가 ㅠ,ㅠ
작성
·
606
8
쿼리 메소드 - 벌크성 수정 쿼리 에서 질문이 있습니다!!
글로 적는거 보다 코드 밑에 TODO 통해 적는것이 이해하는게 편할꺼 같아서
이렇게 질문 드립니다!
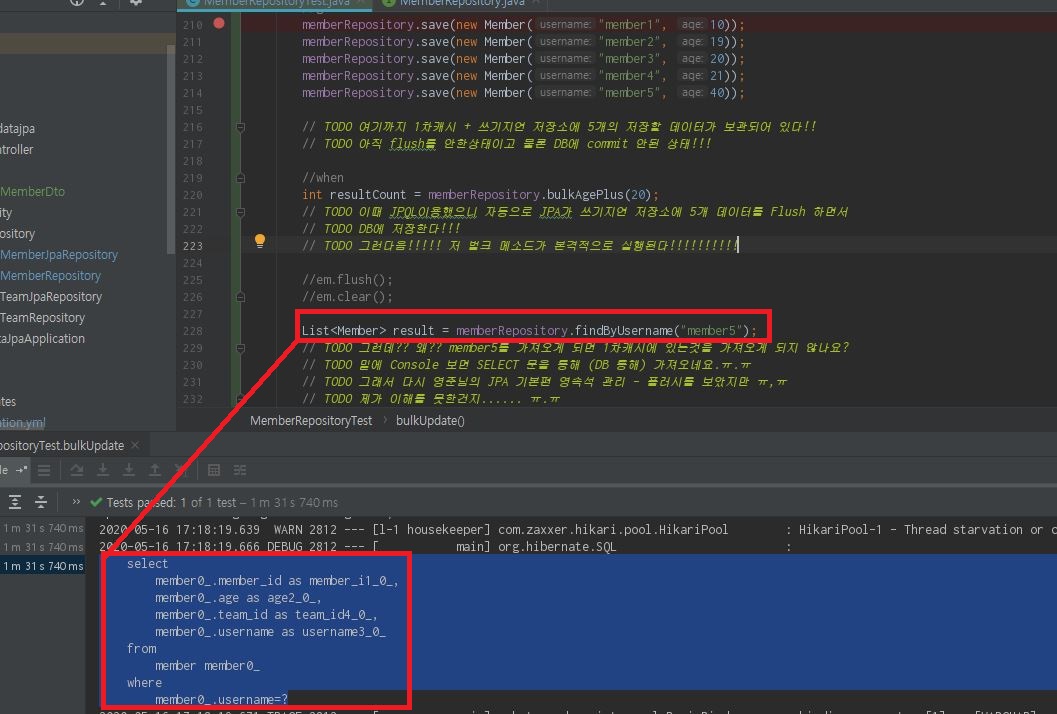
TODO로 남겨드렸습니다! 혹시 글자가 작은가요? ㅠ,ㅠ
답변 4
9
안녕하세요. 리나님^^ 저도 처음 공부할 때 이 부분에 대해서 여러가지 의문을 품었지만 다음 2가지 이유를 잘 고민해보시면 이렇게 한게 충분히 납득이 되실꺼에요. 좀 더 쉽게 풀어볼께요.
1. 기술적 한계
JPQL을 파싱해서 그 결과로 영속성 컨텍스트를 조회하기는 기술적으로 너무 어렵다. 거의 DB의 SQL 조회 기술이 JPA 구현체에 들어가야 한다.
2. 조회 데이터 누락
select m from member m 과 같은 JPQL이 실행되면, 현재 영속성 컨텍스트 뿐만 아니라 데이터베이스 전체를 조회해야 한다. 내가 조회 JPQL을 실행하기 직전에 누군에 회원을 추가할 수 있다. 결국 DB를 항상 조회해야 한다. (영속성 컨텍스트만 조회해서는 현재 영속성 컨텍스트의 범위를 넘어서는 결과를 얻을 수 있는 방법이 없다.)
감사합니다^^
8
안녕하세요. 리나님 이것도 좋은 질문입니다^^
findByUsername 메서드는, 스프링 데이터 JPA가 제공하는 메서드 이름으로 쿼리 호출 기능을 사용하신 것 같네요.
이 경우 스프링 데이터 JPA는 메서드 이름으로 JPQL을 만들어서 실행합니다.
결국 "select m from member m where m.username = ?" 같은 JPQL이 실행된 것이지요.
em.find()나, 지연로딩을 조회할 때는 1차 캐시에서 엔티티를 찾아오는 과정을 거칩니다.
반면에 JPA에서 JPQL은 항상 SQL로 번역되어서 DB를 통해 실행됩니다!
왜냐하면 em.find() 처럼 엔티티 하나를 찾아오는 것은 JPA 구현체 입장에서 key(식별자) 값이 명확하기 때문에 1차 캐시에서 찾기가 간단합니다. 그런데 JPQL은 식별자를 딱 찍어서 찾는 것도 아니고, 쿼리에 따라 1차 캐시보다 더 많은 데이터가 DB에 있을 수 도 있습니다. (예를 들어서 위 코드에서 벌크 연산 실행 직후에 누군가 member5의 데이터를 DB에 더 입력한다면 1차 캐시의 데이터 만으로는 그것을 다 알 수 없지요.) 그리고 기술적으로 JPQL을 분석해서 1차 캐시에서 조회하는 하도록 만드는 것도 매우 어렵습니다.
그래서 하이버네이트 구현체는 우선 JPQL을 실행하면 DB에서 데이터를 조회합니다.
단! 여기서 부터가 매우 중요한데요. (어드벤스 입니다 ㅎㅎ)
현재 1차 캐시에 다음과 같은 데이터가 있고,
ID: 1, name: memberA
DB에 다음과 같은 데이터가 있을 때
ID: 1, name: memberB
예를 들어서 다음과 같은 JPQL을 실행하면
select m from member m where m.id = 1
우선 JPQL이기 때문에 DB에서 쿼리로 id:1, memberB 데이터를 조회합니다.
그런데 1차 캐시에 이미 id:1 이라고, 식별자가 충돌이 됩니다.
JPA는 영속성 컨텍스트의 동일성을 보장합니다.
따라서 DB의 결과 값을 버리고, 1차 캐시에 있는 결과값을 반환합니다.
이 부분에 대해서 더 자세한 내용은 JPA책 10.6.2 영속성 컨텍스트와 JPQL을 참고해주세요^^
감사합니다.
3
답변 감사합니다!!!
죄송한데.. 말씀하시는것은 이해가 가는데
왜???(제가 감히 JPA를 태클 하는것은 아니지만..ㅠ.ㅠ)
JPA가 이렇게 행동하지?? 의문이 생겨서 말씀드립니다.
###################
우선 JPQL이기 때문에 DB에서 쿼리로 id:1, memberB 데이터를 조회합니다.
그런데 1차 캐시에 이미 id:1 이라고, 식별자가 충돌이 됩니다.
JPA는 영속성 컨텍스트의 동일성을 보장합니다.
따라서 DB의 결과 값을 버리고, 1차 캐시에 있는 결과값을 반환합니다.
#####################
이부분인데요.
이럴꺼면.. 차라리 먼저 1차 캐시에 있는 값(id:1이라는 값이 1차캐시에 있다면)을 식별자가 충돌되는지 안되는지
먼저 확인 후에 충돌 되면
1차 캐시에 있는것을 반환 하는게 좋지 않을까요?
왜 JPQL이기 때문에 먼저 1차 캐시에 있는 데이터가 있나없나 확인 안하고 (위에 기술적으로 힘들다고..ㅠㅠ)
DB 커넥션 맺어서 해당 데이터를 가져오고
그럼다음 1차캐시에 식별자 비교해서 충돌나면
DB에서 가져온것을 무시하고(영속성 컨텍스트 동일성 보장하기 위해)
1차 캐시에 있는것을 가져오는지??
음.. 맨처음 DB에서 가져와서 해당 PK를 가져올수 있어서 1차캐시를 비교 하는게 가능케 할려고
어쩔수없이 하는건가요?
감사합니다!
1