인프런 커뮤니티 질문&답변
작성한 질문수

Schedulers.computation()에 관하여
해결된 질문
작성
·
354
0
RxJava 1부 강의 예제 ObservableFromFutureExample.java에서 스케줄러 computation을 적용해보았습니다. (코드 일부를 추가해보았습니다.)
- ObservableFromFutureExample.java
public class ObservableFromFutureExample {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Logger.log(LogType.PRINT, "# start time : ");
TimeUtil.start();
// 긴 처리 시간이 걸리는 작업
Future<Double> future = longTimeWork();
// 짧은 처리 시간이 걸리는 작업
shortTimeWork();
Observable.fromFuture(future)
.subscribeOn(Schedulers.computation())
.subscribe(data -> Logger.log(LogType.PRINT, "# 긴 처리 시간 작업 결과 : " + data));
TimeUtil.end(); TimeUtil.takeTime();
Logger.log(LogType.PRINT, "# end time" );
}
public static CompletableFuture<Double> longTimeWork(){
return CompletableFuture.supplyAsync(() -> calculate());
}
private static Double calculate() {
Logger.log(LogType.PRINT, "# 긴 처리 시간이 걸리는 작업 중.........");
TimeUtil.sleep(6000L);
return 100000000000000000.0;
}
private static void shortTimeWork() {
TimeUtil.sleep(3000L);
Logger.log(LogType.PRINT, "# 짧은 처리 시간 작업 완료!");
}
}
- Result
print() | main | 02:35:32.127 | # start time : print() | ForkJoinPool.commonPool-worker-3 | 02:35:32.136 | # 긴 처리 시간이 걸리는 작업 중......... print() | main | 02:35:35.151 | # 짧은 처리 시간 작업 완료! # 실행시간: 3120 ms print() | main | 02:35:35.250 | # end time
1. Schedulers.computation()를 적용하면 subscribe( ) 메소드에서 구독자에게 발행되는 데이터 결과 값이 출력되지 않는 이유를 알고 싶습니다.
2. Schedules.computation()을 적용했음에도 불구하고 위 결과처럼 'ForkJoinPool.commonPool-worker-3'라는 스레드에서 실행되는 이유를 알고 싶습니다!
*
2. 자문자답
CompletableFuture.java를 살펴보았더니, supplyAsync( ) 메소드의 기본 실행자가 ForkJoinPool.commonPool()이라는 설명을 찾았습니다.
- CompletableFuture.java
/**
* Default executor -- ForkJoinPool.commonPool() unless it cannot
* support parallelism.
*/
private static final Executor ASYNC_POOL = USE_COMMON_POOL ?
ForkJoinPool.commonPool() : new ThreadPerTaskExecutor();

그렇다면, fromFuture( ) 및 CompletableFuture를 이용하는 경우 subscribeOn( ) 함수로 굳이 스케줄러를 지정하지 않아도 되는건가요?
답변 5
1
1
아래 두가지 질문에 대해서 한꺼번에 제가 생각하는 의견을 드리도록 하겠습니다.
"1. Schedulers.computation()를 적용하면 subscribe( ) 메소드에서 구독자에게 발행되는 데이터 결과 값이 출력되지 않는 이유를 알고 싶습니다."
"2. Schedules.computation()을 적용했음에도 불구하고 위 결과처럼 'ForkJoinPool.commonPool-worker-3'라는 스레드에서 실행되는 이유를 알고 싶습니다!"
CompletableFuture의 supplyAsync( ) 가 ForkJoinPool.commonPool 쓰레드인것은 맞습니다.
그런데 subscribeOn( )을 사용하지 않은 원래 소스 코드에서 CompletableFuture의 supplyAsync를 호출 하는 쓰레드는 main 쓰레드인데요.
즉, ForkJoinPool.commonPool 쓰레드의 작업이 끝날때까지 기다리는 쓰레드는 main 쓰레드인데, subscribeOn(Schedulers.computation())을 붙이므로 인해서 기다리는 쓰레드가 main 쓰레드가 아닌computation 쓰레드로 바뀜으로 인해서 Future의 작업을 기다려주지 못하고 이미 computation 쓰레드의 실행이 종료되었을거라고 판단됩니다. Future가 실행되는 시점에서는 결과값을 던져주어야 할 쓰레드가 main 쓰레드인데 subscribeOn( )을 통해서 구독자 즉, 소비자가 값을 전달 받는 쓰레드는 main 쓰레드가 아니기 때문인것으로 판단되네요. subscribeOn( )은 소비자 쪽에서 구독을 신청하는 시점에 생산자 쪽에서 데이터를 통지하는 쓰레드의 흐름을 바꿀때 사용을 하거든요.
이런 판단이 어느 정도 맞을 가능성이 있는 이유가 아래 코드를 보시면,
Observable.fromFuture(future)
.map(data -> data + "!!!!!!")
.observeOn(Schedulers.computation())
.doOnNext(data -> Logger.log(LogType.DO_ON_NEXT, data))
.subscribe(data ->
Logger.log(
LogType.PRINT, "# 긴 처리 시간 작업 결과 : "
+ data
));
코드에서 observeOn(Schedulers.computation())을 사용하여 쓰레드를 변경하였을 경우에는 소비자 쪽에서 정상적으로 결과 데이터를 전달 받는데요. 이를 통해서 예상할 수 있는건 구독 시점에 생산자 쪽에서의 쓰레드가 여전히 main 쓰레드이기때문에 Future에서 결과 값을 전달을 받을 수 있는것이라고 예상할 수 있습니다.
observeOn( )의 경우에는 생산자 쪽의 쓰레드를 변경하는 것이 아니라 생산자 쪽에서 통지한 데이터를 가공하는 그 시점의 쓰레드를 변경하는 것이기때문에 Future가 결과값을 던져주기 위한 쓰레드에 영향을 주지 않기때문이라고 생각됩니다.
설명이 좀 장황해진 부분이 있는것 같은데 요점은 Future가 결과값으로 전달해야 될 쓰레드를 subscribeOn()이 바꿔버렸다라고 말씀을 드릴 수 있을 것 같습니다.
답변이 충분했는지 모르겠네요.
0
대댓글이 보이지 않는다는건 저도 몰랐네요. 참고하도록 할게요. 그런데 대댓글을 댓글로 작성하면 depth가 같아져서 어떤 글에 대한 답변인지 좀 헷갈릴 수도 있다는 생각도 들긴하네요.ㅎ
이 문제는 인프런측에서 대댓글까지 보이게 해주시는게 제일 좋을것 같다는 생각도 듭니다. ^^
0
건의사항이 있는데요,
강의 화면의 사이드 메뉴의 커뮤니티에 올린 중 게시글(=첫 번째 댓글?)만 보여지고, 대댓글은 강의 화면에서 보이지 않은 것을 발견했습니다.
인프런 첫 번째 댓글과 대댓글 기능이 어느 화면이냐에 따라 일부 분리가 되어있는 것 같습니다.
강사님께서 답글을 작성해주실 때 대댓글이 아닌 그냥 댓글로 작성해 주시면 다른 수강생들이 질문을 참고할 때 좋을 것 같습니다!
0
추가 질문 있습니다
답변해 주신 내용 중
'observeOn( )의 경우에는 ... 생산자 쪽에서 통지한 데이터를 가공하는 그 시점의 쓰레드를 변경하는 것이기 때문에 Future가 결과값을 던져주기 위한 쓰레드에 영향을 주지 않기 때문이라고 생각됩니다.'
라고 해주셨습니다.
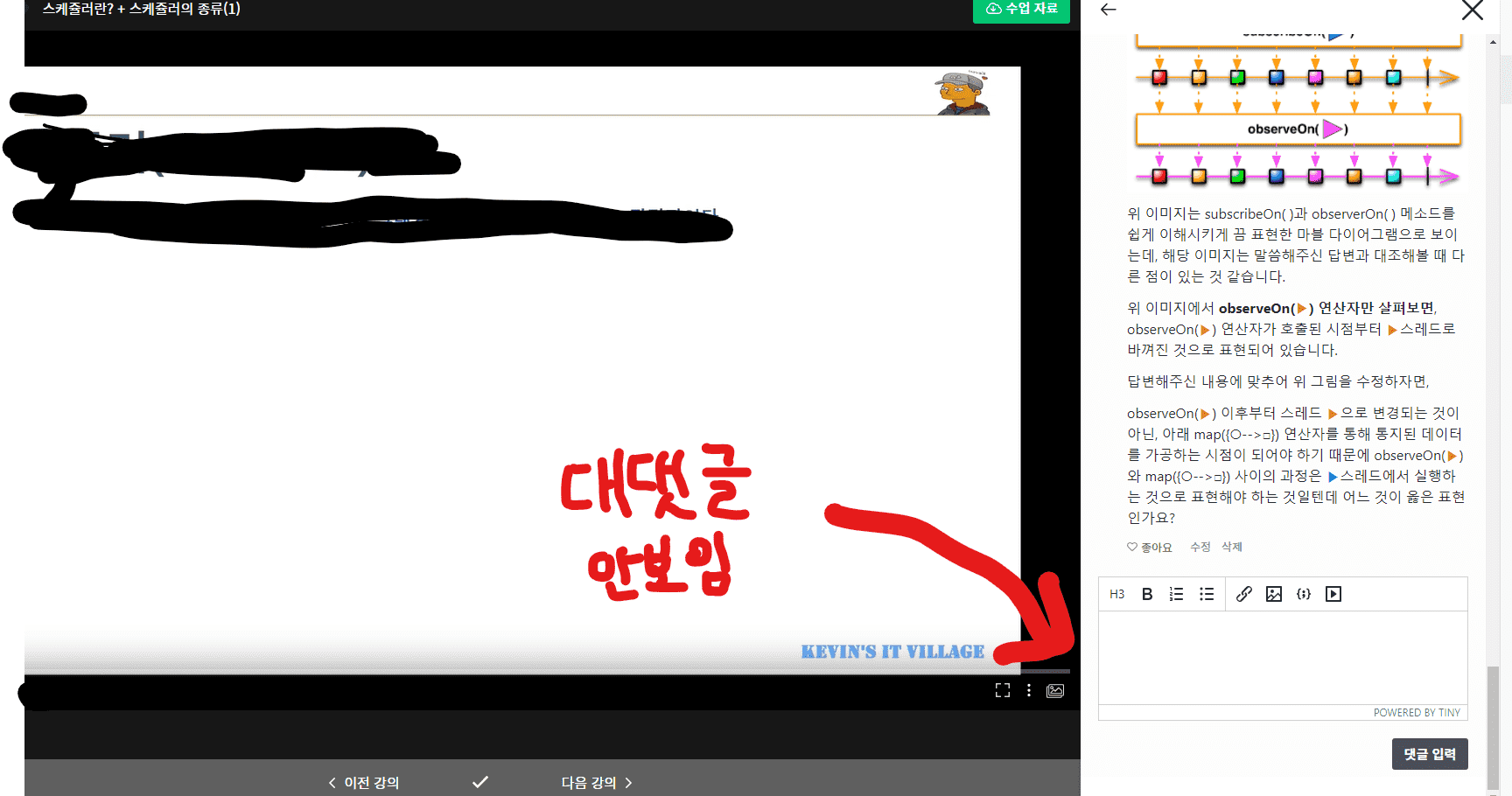
제가 복습하면서 이것과 관련해서 인터넷에서 찾은 이미지가 있는데요,

위 이미지는 subscribeOn( )과 observerOn( ) 메소드를 쉽게 이해시키게 끔 표현한 마블 다이어그램으로 보이는데, 해당 이미지는 말씀해주신 답변과 대조해볼 때 다른 점이 있는 것 같습니다.
위 이미지에서 observeOn(▶) 연산자만 살펴보면, observeOn(▶) 연산자가 호출된 시점부터 ▶스레드로 변경된 것으로 표현되어 있습니다.
그에 반면, 답변해주신 내용에 맞춰 위 그림의 내용을 수정하자면,
observeOn(▶) 이후부터 스레드 ▶으로 변경되는 것이 아닌, 아래 map({○-->□}) 연산자를 통해 통지된 데이터를 가공하는 시점이 되어야 하기 때문에 observeOn(▶)와 map({○-->□}) 사이의 과정은 ▶스레드에서 실행하는 것으로 나타내야 할텐데 어느 것이 옳은 것일까요?
제가 설명한 문장에 오해의 소지가 있는것 같네요.
쉽게 설명 드리기위해서 썼던 문장인데 오해의 소지가 있는것 같아서 바로 잡겠습니다.
observeOn 이 호출되는 시점에 Downstream의 쓰레드가 변경이 됩니다. map이 호출되는 시점에쓰레드가 바뀌는것이 아니구요. 그래서 observeOn 은 호출될때마다 쓰레드가 바뀔테구요.
그런데 subscribeOn은 몇번을 사용해도 한번만 쓰레드가 바뀌는데 위 그림에서는 observOn 다음에 호출했기때문에 쓰레드가 바뀌지 않을거에요.
그래서 일반적으로 subscribeOn으로 최상위 Upstream 즉, 최초로 데이터를 생성해서 통지하는 생성 연산자 바로 다음에 사용을 합니다.
subscribeOn 이 생산자의 데이터 통지 흐름을 제어하기위해서 사용하는것이기 때문에 fromArray 같은 생성 연산자 바로 다음에 호출하는게 제일 자연스럽다고 생각하시면 될것 같아요.
음 우선 제가 먼저 질문한 내용에 대해서 이해는 했습니다. 제가 올린 그림이 틀린 것이 아니었고, 웬만하면 생산 연산자 바로 다음에 사용하도록 해야겠네요.
대신 'observeOn 다음에 (subscribeOn을) 호출했기때문에 쓰레드가 바뀌지 않을거에요.'라는 부분에서 조금 혼동이 옵니다.
그리고 답변해주신 내용으로는 subscribeOn은 일반적으로 최초로 데이터를 생성해서 통지하는 생성 연산자 바로 다음에 사용한다고 하셨습니다,
위 그림처럼 subscribeOn이 Observable 연산 체인 어느 위치에 있든지 간에 최상위 Upstream부터 subscribeOn에서 지정한 스레드에서 실행한다는 뜻이죠??
네, 말씀하신대로 subscribeOn 은 어떤 위치에 있든지 간에 최상위 Upstream의 실행 쓰레드를 지정한다는 의미가 맞습니다. observOn 의 쓰레드를 변경하지는 않는다라고 말씀 드리는게 더 정확할것 같은데 혼란스럽게 만든것 같네요.
subscribeOn을 제일 먼저 호출하는건 관례라고 보시면 될것 같습니다.
넵 평일에 인프런에 문의해봐야겠네요!