실전 데이터 사이언스 Part 3. 머신러닝의 이해
기업의 디지털 전환(DT), 인공지능(AI) 도입은 머신러닝 모델 구축에서 시작합니다. 그러나 머신러닝 기술 범위는 매우 넓으며 최적의 방법을 선택하려면 기본 개념을 분명히 이해해야 합니다. 이 강의에서는 머신러닝의 기본 개념을 명확하게 이해하는데 필요한 핵심 내용을 다섯개의 예제를 중심으로 소개합니다.

초급자를 위해 준비한
[데이터 분석] 강의입니다.
이런 걸
배워요!
머신러닝이 무엇인지, 어떻게 동작하는지 기본원리를 이해합니다.
머신러닝 모델을 파이썬으로 구현하는 방법과 모델의 성능을 평가하는 다양한 성능 지표를 이해합니다.
전통적인 통계 분석과 머신러닝의 차이를 이해하고 확률분포, 독립검정, 카이제곱 검정 등 주요 통계 기법을 예제를 통해서 배웁니다.
핵심만 담았다!
모델 구축을 위한 머신러닝 기본 이해

머신러닝이란? 👩💻
머신러닝은 수치를 예측하는 작업(회귀), 카테고리를 예측하는 분류, 최적의 추천 등을 수행하는 소프트웨어로, 데이터를 보고 학습하여 점차 성능이 개선되는 소프트웨어를 의미합니다.
현재 인공지능을 구현하는 대표적인 방법이 머신러닝 기법입니다. 머신러닝의 핵심 기능은 지능적인 동작을 수행하는 머신러닝 "모델"을 만드는 것입니다.
머신러닝 모델 📖
입력 데이터(X)로부터 최적의 출력(y)을 얻는 소프트웨어를 말하며 최적의 출력이란 정답(label, target)을 잘 예측하는 것을 말합니다.
모델의 종류에는 선형모델, 로지스틱 회귀, SVM, 결정트리, 랜덤 포레스트, kNN, 베이시언, 딥러닝 모델 (MLP, CNN, RNN) 등이 있습니다. 이 강의에서는 이 알고리즘들의 내용을 설명하지는 않지만 머신러닝 모델을 구현하는 기본적이며 공통적인 방법을 선형 모델을 사용하여 배웁니다. 각 모델의 특징에 대해서는 다른 강의에서 다룹니다.
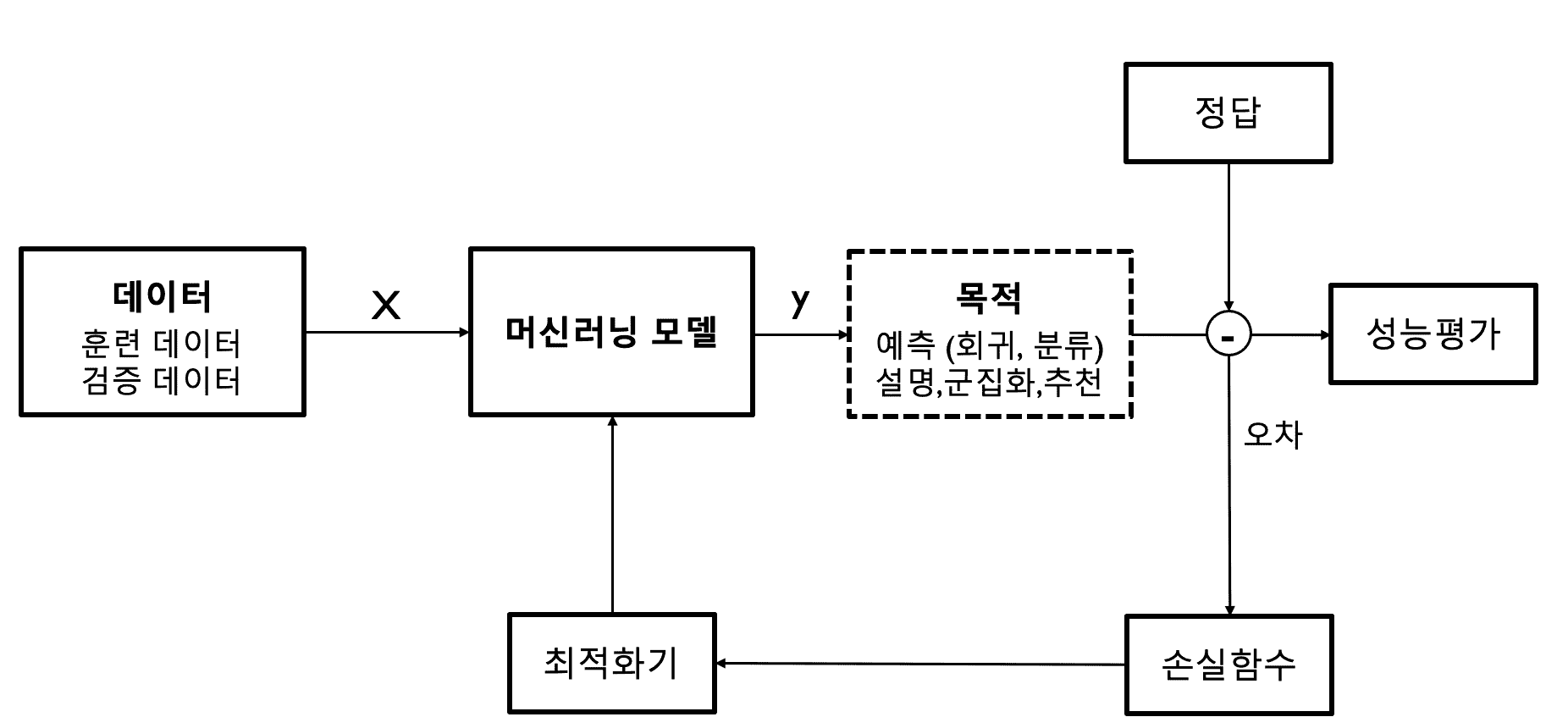
머신러닝 모델 구성 요소 🚦
1️⃣ 입력 데이터
최적의 모델을 구현하려면, 모델을 학습시키는데 필요한 훈련 (train) 데이터, 그리고 학습시킨 모델의 동작을 검증하는데 필요한 검증 (validation) 데이터를 잘 준비해야 합니다.
원시(raw) 데이터로부터 적절한 학습 및 검증 데이터를 만드는 과정이 데이터 전처리이며 데이터 전처리가 머신러닝 모델의 성능을 크게 좌우합니다.
2️⃣ 머신러닝 모델의 목적
머신러닝 모델을 사용하는 목적은 다음과 같이 4가지로 나누어집니다.

이 강의에서 배우는 것 👨🏫
✅ 머신러닝 모델
머신러닝 개요를 학습하고 머신러닝을 이해하기 위한 핵심 개념을 다섯 개의 예제 중심으로 설명합니다.
✅ 성능 평가
먼저 회귀 모델의 구현, 학습, 검증 방법 그리고 모델 성능 평가 척도인 R-squared, MAE, RMSE 등을 배웁니다.
다음에는 분류 모델 구현 방법과 결정 경계, 컨퓨전 매트릭스, 정확도, 정밀도(precision), 리콜(recall), f-1 점수의 개념을 배웁니다. 분류의 성능 평가를 하려면 컨퓨전 매트릭스를 명확히 이해해야 하며 예제를 통해서 이를 상세하게 소개합니다.
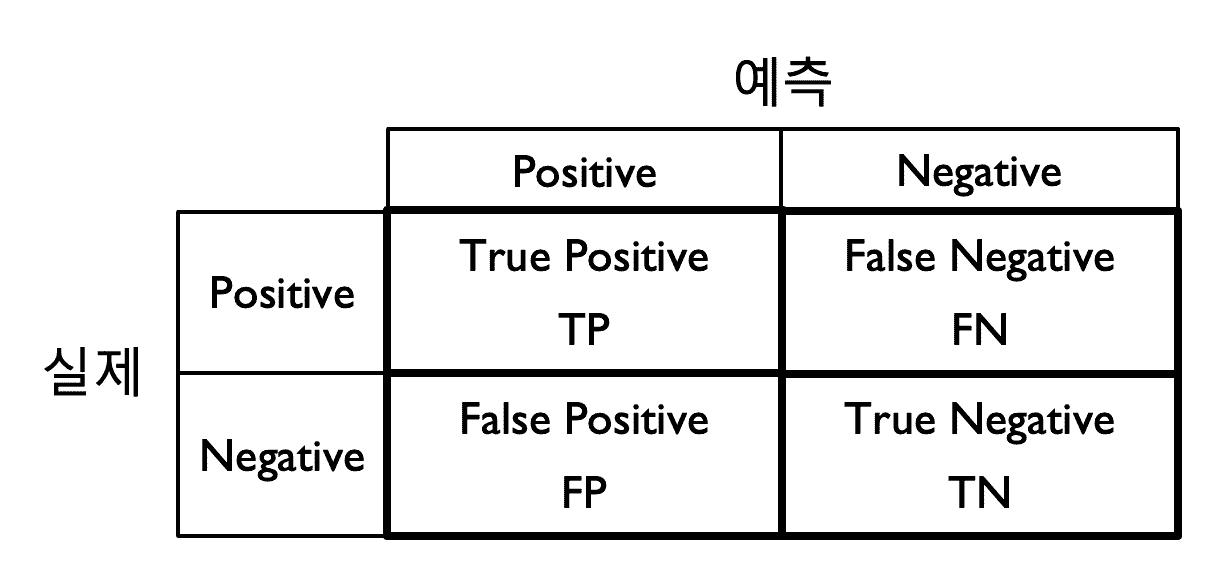
분류 모델의 종합적인 성능 평가를 위해서는 예측 순위(랭킹)를 평가해야 하는데 이를 위해서 ROC-AUC, precision-recall curve의 사용법을 설명합니다.
✅ 분류 경계치(threshold) 찾기
실제 업무에서는 분류 모델이 만족시켜야 할 최소한의 정밀도나 리콜값 요구 기준이 있으며 이를 만족하는 최적의 분류 경계값(threshold)을 선택해야 할 일이 많습니다. Precision-Recall 커브를 이용하여 최적의 경계값을 찾는 방법을 자세히 다룹니다.
✅ 통계 분석과 머신러닝의 차이
머신러닝을 배우면서 가장 궁금해하는 것 중 하나가 통계 분석과의 차이를 이해하는 것입니다. 통계 분석은 기술통계, 추정, 가설검증으로 나누어집니다.
- 기술(descriptive) 통계
- 데이터의 평균, 표준편차, 확률 분포, 상관관계 등 파악하여 데이터에 포함된 어떤 의미, 통찰력(insight)를 얻는 것을 말합니다.
- 추정(estimation)
- 표본 샘플을 보고 모집단의 특성을 추정하는 것으로 평균, 표준편차 등 특정 수치 값을 추정하는 점추정과 신뢰구간 등을 추정하는 구간 추정이 있습니다.
- 가설 검정 (testing hypothesis)
- 샘플 데이터를 보고 주장하고자 하는 대립가설(alternative hypothesis)이 맞는지를 검정(testing)하는 것을 말합니다.
통계학에서는 이론적인 근거를 설명하는 것을 중요시하여 가설, 확률, 신뢰구간, 오차범위 등을 다룹니다. 반면, 머신러닝은 이론적인 근거 제시보다는 예측이나 분류를 잘 수행하는 소프트웨어 모델을 만드는 것을 목표로 합니다.
분석할 데이터의 크기가 작으면 통계적 분석에 의존하여 설명, 추정, 가설검증 등을 해야 하나, 데이터가 충분히 많으면 머신러닝 모델을 만들어 실전에서 사용 가능한 모델을 만드는 것이 더 유용합니다.
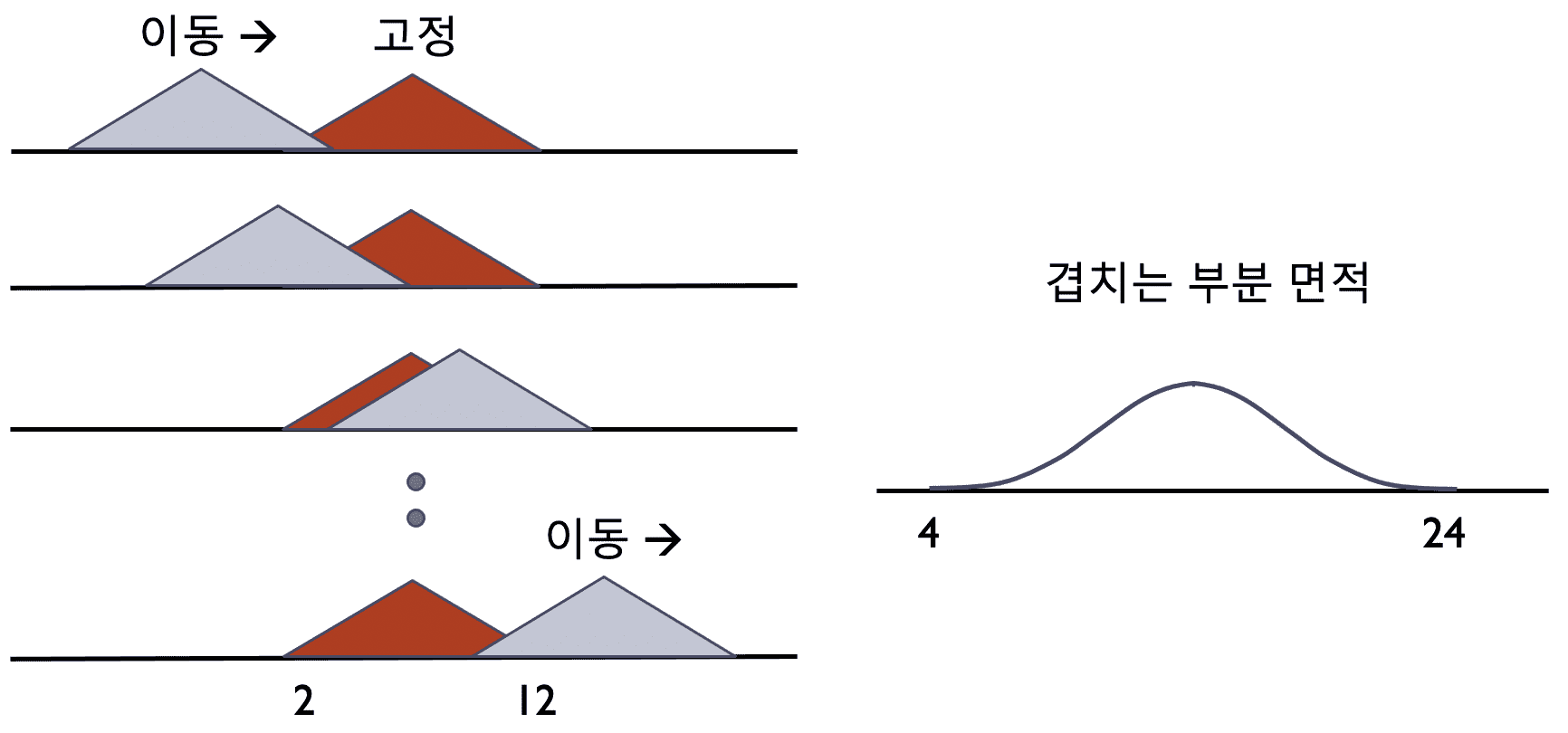
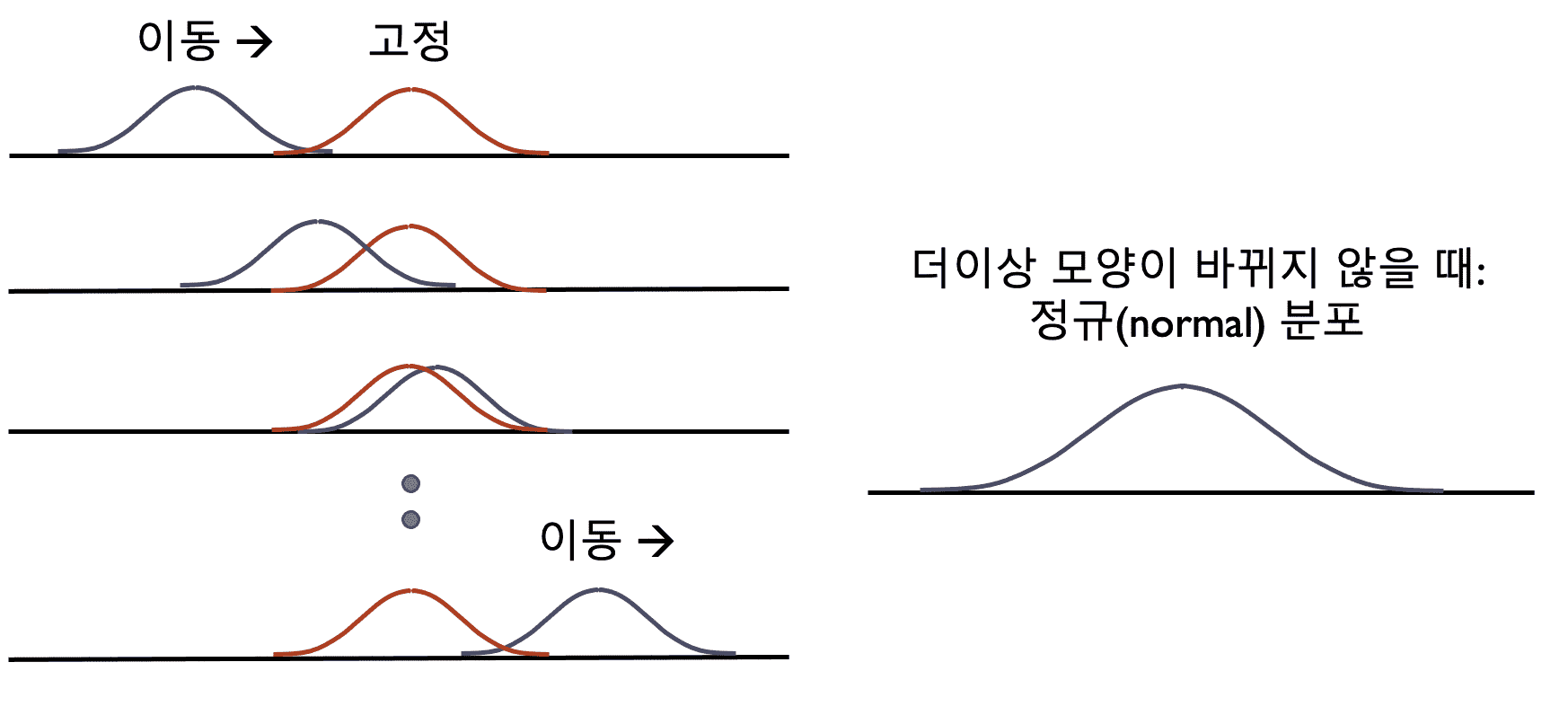
이 강의에서는 정규분포의 특성 등 통계 분석의 기본적인 내용을 소개합니다. 참고로 정규분포란 누적되는 샘플들의 확률 분포 함수가 더 이상 바뀌지 않고 수렴한 때의 확률 분포 함수입니다. (아래 그림)
🌟 핵심 데이터 사이언스 강의보기

본 강의는 파이썬 기초 지식이 선수 되는 강의입니다.
파이썬 언어에 대한 기초 지식이 없으신 분들은
선수 지식 학습을 추천드립니다.

기업에서 가장 많이 다루는 데이터 분석 성능에
가장 큰 영향을 주는 데이터 전처리 관련 강의입니다.
데이터 전처리에 대해 집중적으로 학습하고 싶으신 분들은
실전 데이터 사이언스 Part2. 데이터 전처리 강의 학습을
추천드립니다.
이런 분들께
추천드려요!
학습 대상은
누구일까요?
머신러닝의 동작원리를 처음 배우시는 분
머신러닝을 본인의 업무에 적용해야 하나 많은 시간을 투자하기 어려운 경우, 단시간에 머신러닝의 핵심을 배우려는 분에게 도움이 될 것입니다.
선수 지식,
필요할까요?
파이썬 기초 지식이 필요합니다.
안녕하세요
김화종입니다.
"고장난 라디오 고칠 수 있어?"
제가 전자공학과에 입학한 후 친구로부터 받은 질문입니다. 뭐, 대답은 했습니다. "전자공학과에서는 라디오 만드는 원리를 배우는 것이지 고장난 전자제품 고치는 것은 우리 일이 아니고..."
이론으로 무장한 전문가보다 문제 해결사가 필요한 경우가 더 많습니다. 저는 실전 문제 해결이 더 중요하다고 생각합니다.
최근에는 머신러닝으로 금융, 에너지, 전자, 중장비, 물류, 신약개발, 식품 등 산업 영역의 문제를 해결하는 일을 하고 있는데, 정말 배울 것도 많고 할 일도 무궁무진한 영역인 것 같습니다. 본업은 교수지만 (강원대 컴퓨터공학과), 현장의 문제해결에 관심이 많아 여러 겸직을 하고 있습니다. AI신약개발지원센터장, KAIST 겸임교수, 그리고 데이터사이언스랩 대표를 맡고 있습니다.
AI 시대에 가장 필요한 인재는 실전 문제를 해결할 수 있는 데이터 사이언티스트라고 믿으며 여러분 모두 인기 있는 데이터 사이언티스트가 되기를 바랍니다.
커리큘럼
전체
20개 ∙ (4시간 45분)
강의 소개
03:26
머신러닝 정의
17:44
훈련 및 검증 데이터 생성
15:01
선형회귀 모델
14:57
회귀모델 성능평가
16:12
실제 키-몸무게 예측 모델
08:43
다중변수 회귀 모델
11:28
카테고리 변수 사용
09:33