
초급자를 위해 준비한
[업무 자동화, 데이터 분석] 강의입니다.
이런 걸 배울 수 있어요
쿠팡, 구글 무비, 네이버 등 각종 사이트 스크래핑 전략
동적으로 로딩되는 페이지도 가뿐하게
Selenium 을 활용한 웹 자동화 기초 지식까지
재미있고 유용한 웹 스크래핑,
각종 데이터를 내 손으로 다루고 얻어보세요!
본 강의에서 다루는 쿠팡, 네이버 웹툰, 티스토리 등 웹 스크래핑 대상 사이트들은 강의 촬영 시점 이후에 지속적인 업데이트 및 개편으로 인해 페이지가 변경되었습니다. 또한 selenium 버전이 올라감에 따라 일부 기능은 더 이상 사용할 수 없게 된 부분도 있습니다. 이에 따라 실습 내용 중 많은 부분을 따라하기 힘든 문제가 발생하고 있습니다. 새롭게 강의를 수강하시는 분들은 이 점을 감안하셔서 학습 부탁드리며, 강의에서 보여드리는 모든 실습을 따라하기보다는 당시의 페이지 상황에 따라 어떻게 접근할 수 있는지에 대한 이해도를 높이는 목적으로 강의를 활용 부탁드립니다. 학습에 불편드려 대단히 죄송합니다.
혹시 늑대와 일곱 마리 아기 염소 이야기, 기억하시나요?

엄마가 집을 비운 사이 일곱 마리 아기 염소만 남아 있는데 나쁜 늑대가 찾아옵니다.
"나 엄마야, 문 좀 열어줘"
근데 한 아기 염소가 "우리 엄마 목소리는 그렇게 무섭지 않아!" 하면서 문을 열어주지 않지요.
다시 찾아온 늑대가 이번에는 예쁜 목소리로
"엄마란다, 문 좀 열어주겠니?"
하자 한 아기 염소가 물어봅니다.
"손을 내밀어 보세요"
그러고는 이내 진한 털에 발톱이 날카로운 발을 보고는
"우리 엄마 손은 아주 하얗단 말이에요" 라며 문을 열어주지 않아요.
뽀얀 밀가루를 잔뜩 묻히고 다시 나타난 늑대의 발을 보고,
이번에는 염소들이 속아서 문을 열어줬다가 낭패를 당합니다. (결말 스포는 안하겠습니다 ㅋㅋ)
자, 여기서 늑대는 염소의 집을 뚫기 위해서 3번의 시도를 합니다.
1. 엄마라는 거짓말
2. 엄마라는 거짓말 + 예쁜 목소리
3. 엄마라는 거짓말 + 예쁜 목소리 + 뽀얀 밀가루를 묻힌 발
결국 3번째에서 집을 뚫고 말지요.
웹 스크래핑(Web Scraping)?
서론이 길었는데요, 웹스크래핑은 바로 이러한 과정이 필요합니다. 마치 창과 방패의 싸움처럼, 쉬운 방패라면 그냥 아무 창이나 써도 되겠지만 튼튼한 방패를 뚫기 위해서는 더 날카롭고 정교하며 센 창으로 도전할 필요가 있지요.
그런데 웹 스크래핑에서는 사실 염소와 늑대의 입장이 조금 바뀝니다.
우리가 온순한 아기 늑대가 되고, 대상 서버가 우락부락한 근육질의 덩치 크고 뿔도 달린 엄마 염소가 됩니다. 저 서버를 어떻게든 공략을 해야 해요.


그러기 위해서 여러 접근 방법이 활용되는데 제 강의에서 위에 있는 늑대의 전략을 순서대로 하나씩 모두 설명을 드립니다.
아참, 웹 스크래핑과 웹 크롤링은 조금 다릅니다.
웹 크롤링은,
아재(저 포함)들은 아실 텐데 옛날에 '책 책 책 책을 읽읍시다' 라는 프로그램이 있었어요. 여기에서 하이라이트는, 책이 가득한 책장이 있고 옆에 카트가 하나를 두고 게스트에게 1분인가 시간을 줍니다. 그리고 그 시간동안 담을 수 있는 최대한 많은 책을 가져오면 그 책은 모두 게스트 소유가 되는 거에요. ("황금책"에 대한 설명은 논외로 하겠습니다 ^^)

이 때 여러분이 게스트라면 어떻게 하시겠어요?
아마 이것저것 따지지 않고 모조리 책을 최대한 빨리 담으려고 할 겁니다. 이게 웹 크롤링이라고 보시면 되구요.

반면에 웹 스크래핑은, 시험 전날에 선생님이 하얀 종이를 한 장 주면서 여러분이 어떤 내용이든 필기를 해 오라고 합니다. 그러면 시험 시간에 그 종이 딱 1장은 펼쳐놓고 시험을 칠 수 있는 거에요.
그럼 여러분은 아마도 수업시간에 배운 중요한 내용이나 외우기 어려운 공식, 영어 단어 같은 것들을 참고하기 쉬운 형태로 빼곡히 적겠지요. 이게 바로 웹 스크래핑입니다. 서로 다르죠?
다시 말하면 웹 스크래핑은 웹사이트에서 내가 원하는 데이터를 추출해와서 내가 원하는 형태로 가공하는 행위를 말합니다.
예를 들어 네이버 웹툰 페이지에 있는 모든 만화의 제목이나 실시간 순위 Top 1-10을 가져온다던지,
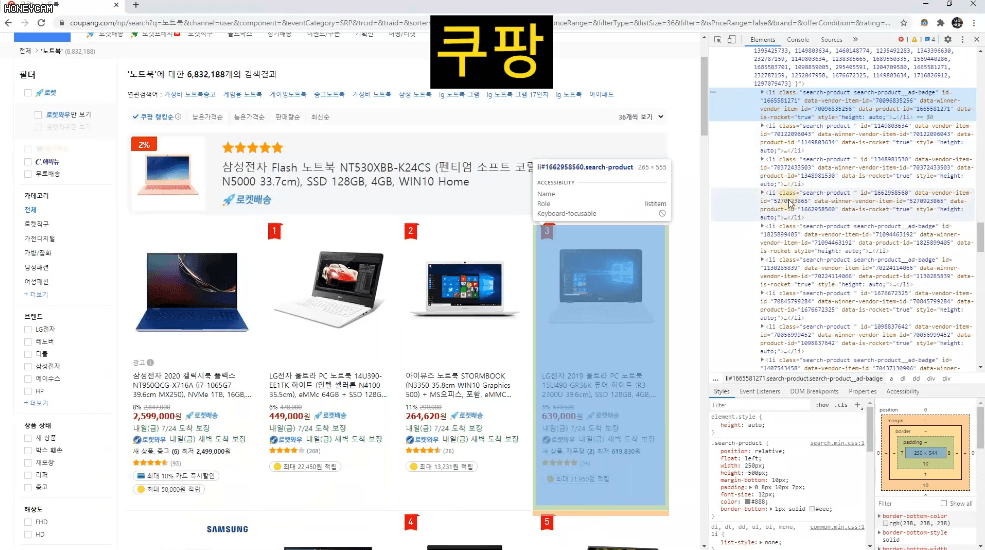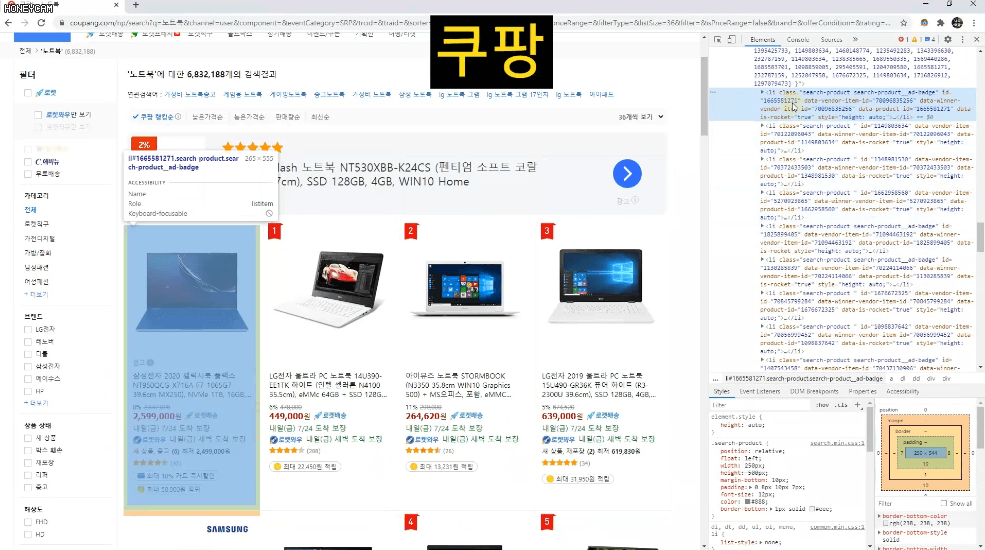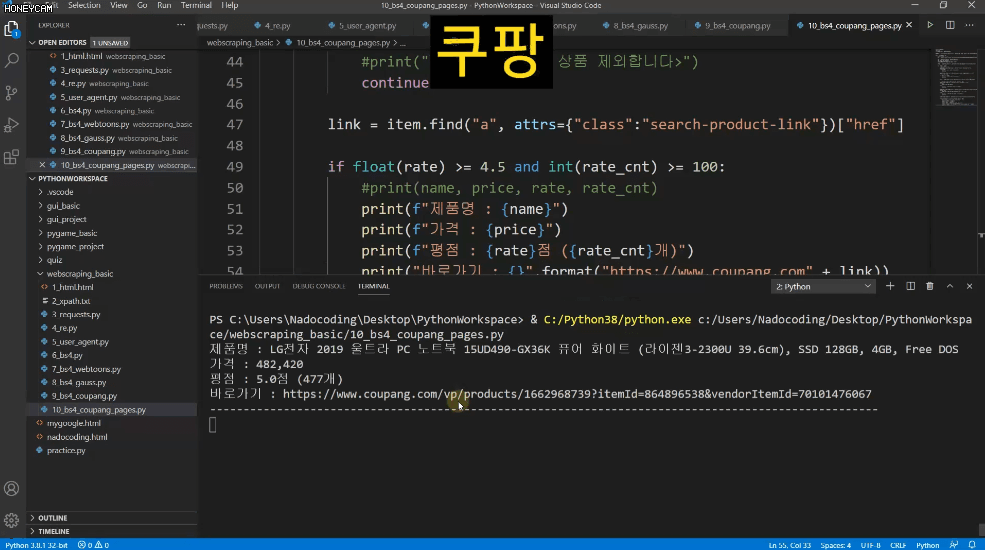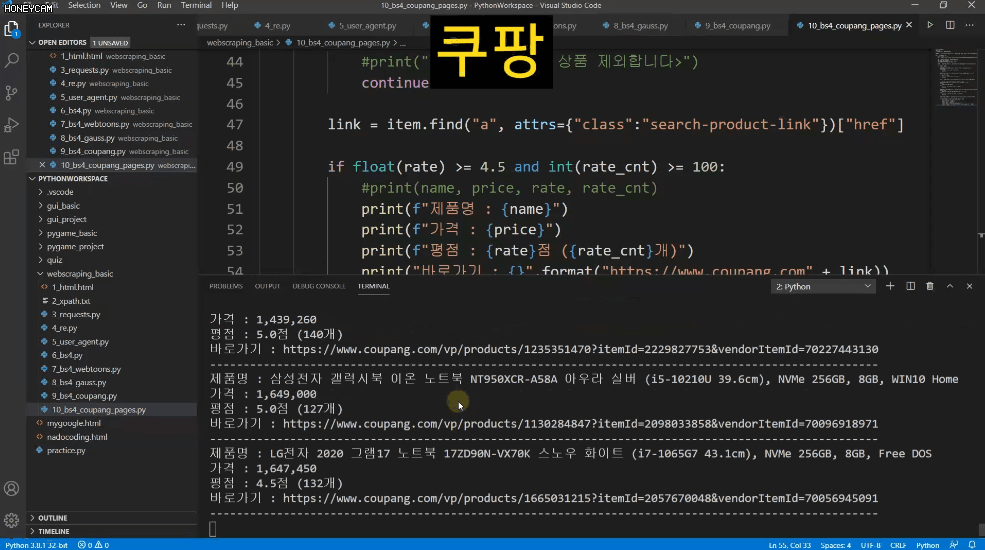
쿠팡 같은 쇼핑몰에서 딱 내가 원하는 조건에 맞는 상품만 링크와 함께 가져온다던지,
예제에서는
- 상위 1~5 페이지 내에서
- 리뷰가 100건이 넘고
- 평점이 4.5점이 넘으면서
- Apple 제품은 제외하고
- 광고 상품은 제외한
목록만 가져오도록 실습한답니다.
(절대 Apple이 싫다거나 한 건 아니고 그냥 연습용일 뿐입니다 ㅎㅎ )
이미지를 다운로드 받는 연습도 해보구요.
제가 영화를 굉장히 좋아하는데 어떤 영화를 보면 좋을지 결정장애가 있어서 그냥 최근 5년간 관객 수가 가장 많은 상위 5개 영화에 대해 총 25개 영화 포스터 이미지를 다운받아놓고 그중에 아무거나 선택을 하려 합니다. 이 이미지를 하나하나 저장하려면 굉장히 많은 시간과 클릭질이 필요하지만, 스크래핑 기술을 이용하면 몇 줄 안되는 코드로 파일명도 내가 원하는 대로 저장할 수 있게 되지요.
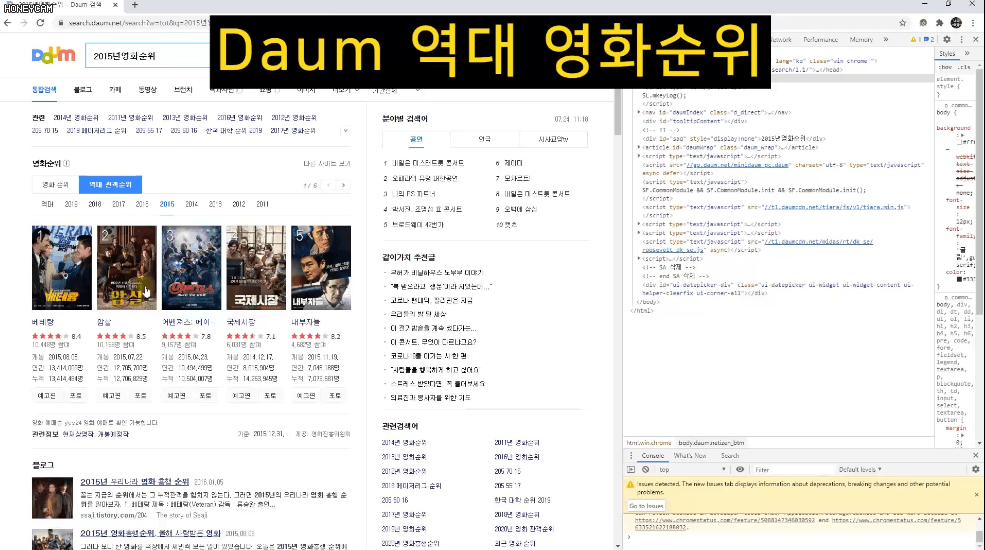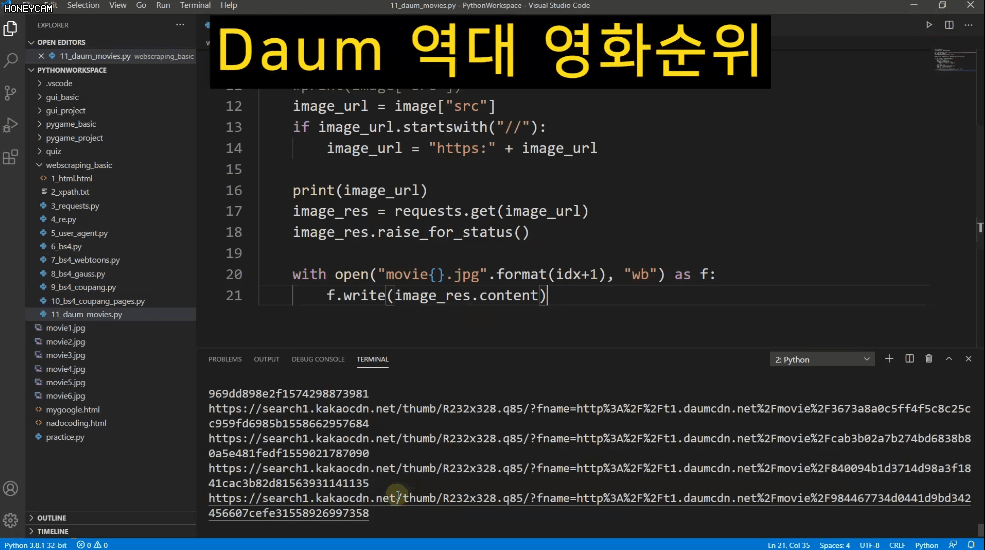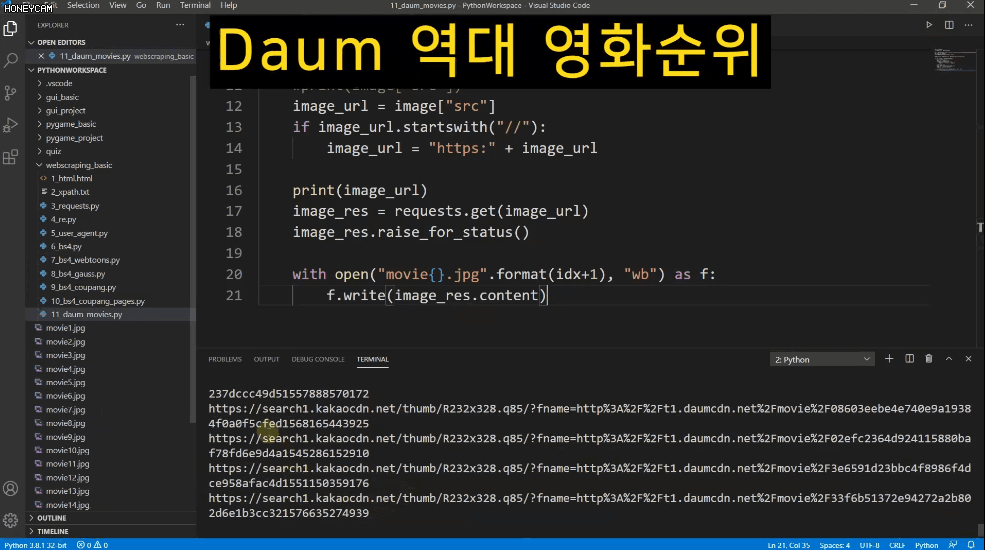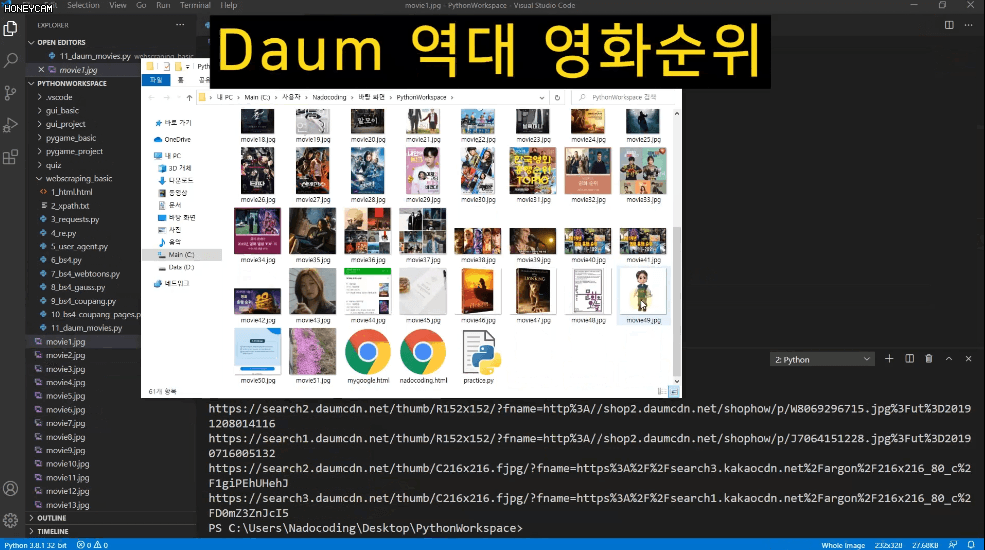
그리고 어떤 데이터들은 가지고 오고 나서 엑셀로 관리하거나 추가 작업을 해야 할 때도 있습니다. 그럴때는 간단하게 csv 형태로 파일을 만들면 바로 엑셀에서 열어볼 수도 있어요. 네이버 금융에서 코스피 시가총액 순위 정보를 모두 가져와보는 실습을 합니다.
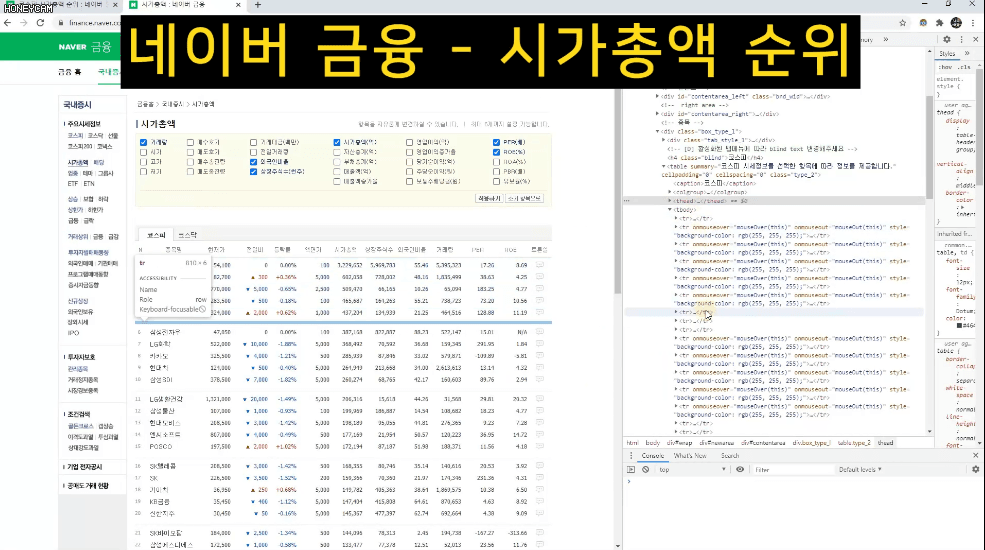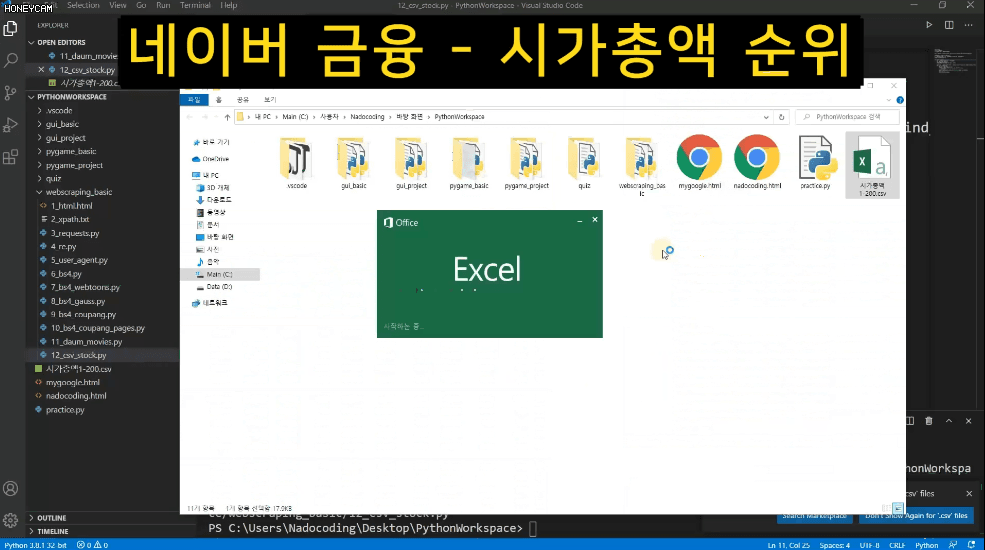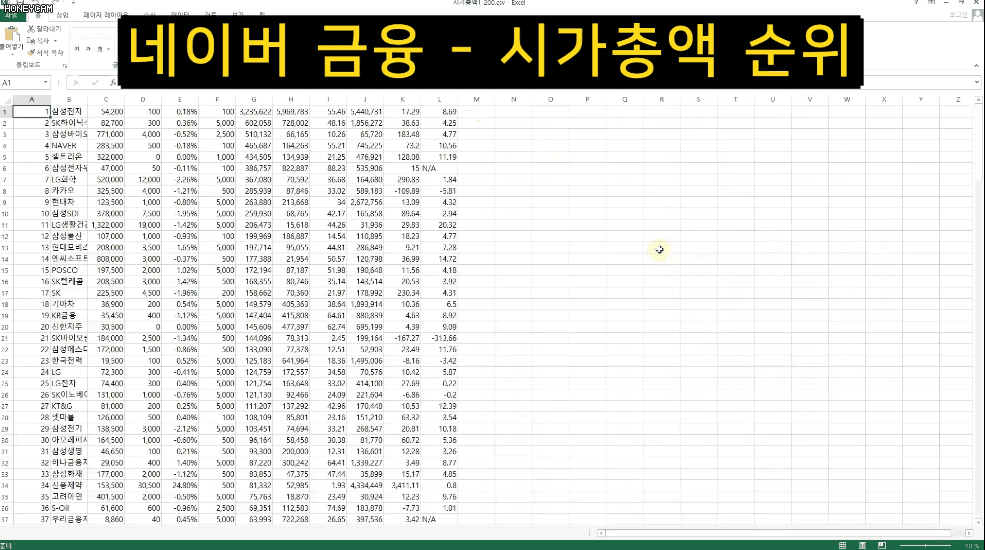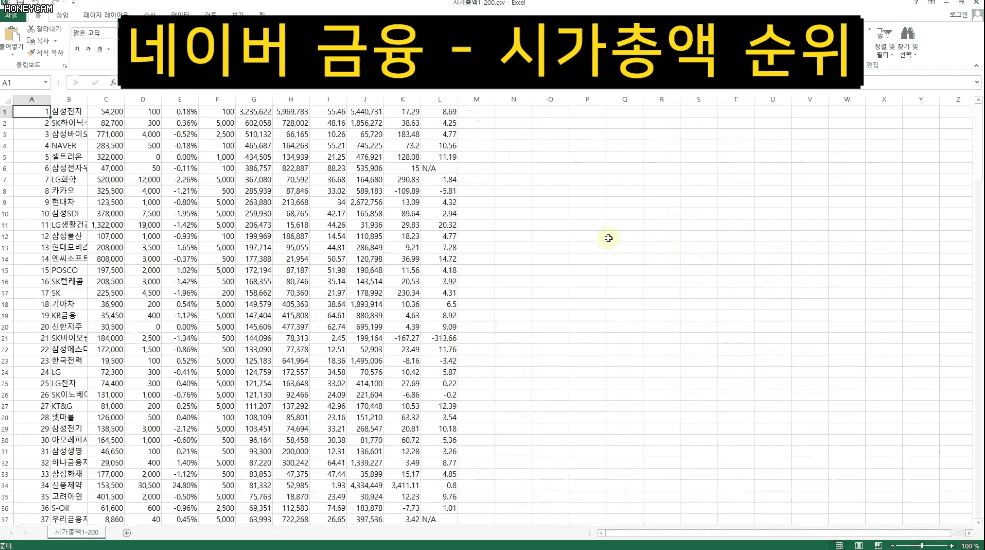
그런데 이런 사이트에서는 사람이 아닌 자동화 봇(Bot)이 정보를 빼가는 것을 썩 달가워하지는 않을수도 있습니다. 무단으로 정보를 사용할 수도 있거니와, 계속 페이지를 요청하게 되면 그만큼 서버에 큰 부담을 줄 수도 있거든요. 그래서 서버에서는 페이지를 볼 수 있는 권한을 주지 않거나 접근을 차단하는 등 다양한 방법으로 방어를 합니다.
그러나 늘 그렇듯 우리는 길을 찾을 겁니다.

때로는 로그인이 필요하거나 웹페이지에서 어떤 동작을 해야만 내가 원하는 데이터를 가져올 수도 있습니다. 동적으로 움직이는 웹페이지는 Selenium(셀레니움, 셀레늄)이라는 웹 테스트 자동화 프레임워크를 이용해서 우리가 직접 브라우저를 자동으로 컨트롤 할 수도 있습니다. 이전의 방법들이 잘 안 될 때, 그냥 Selenium으로 하면 웬만하면 해결이 될겁니다.
가령 구글 무비 페이지에서 인기차트 영화 중 현재 할인중인 영화 정보만 가져오고 싶은데 여기는 사용자가 스크롤을 내려야만 다음 목록이 불러와집니다.
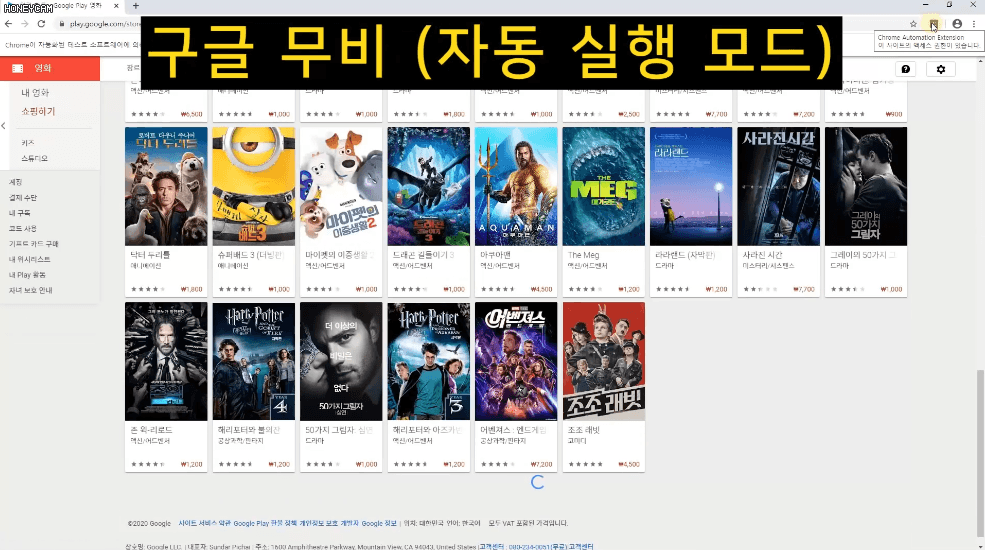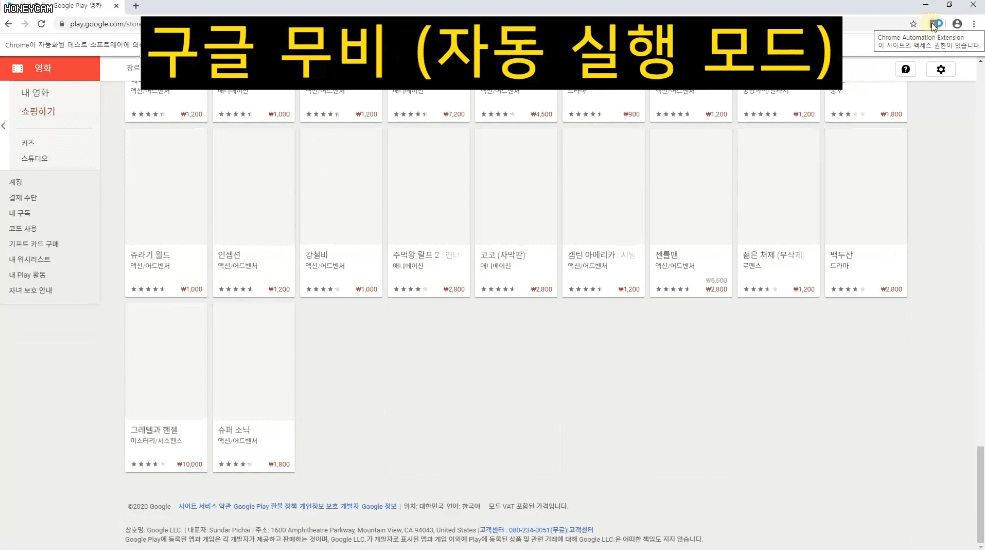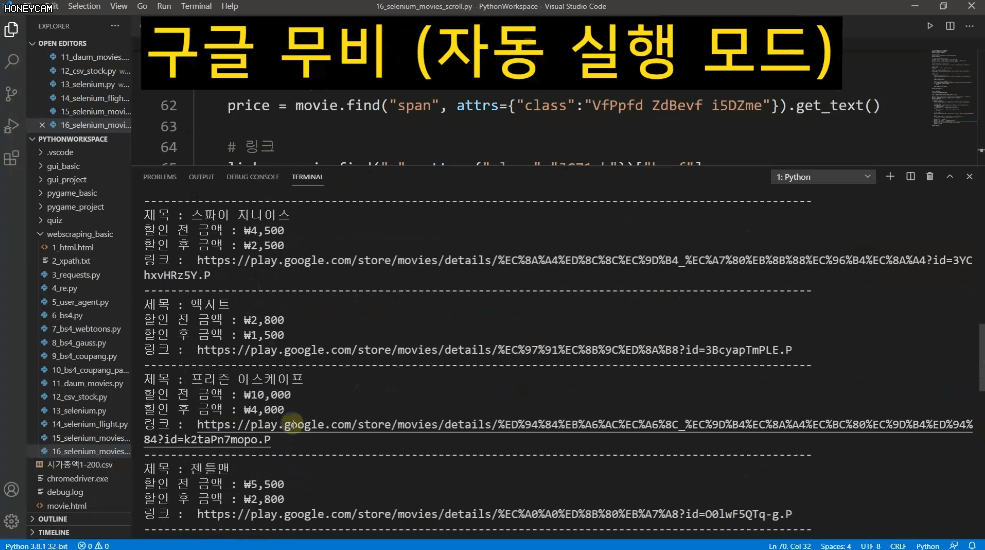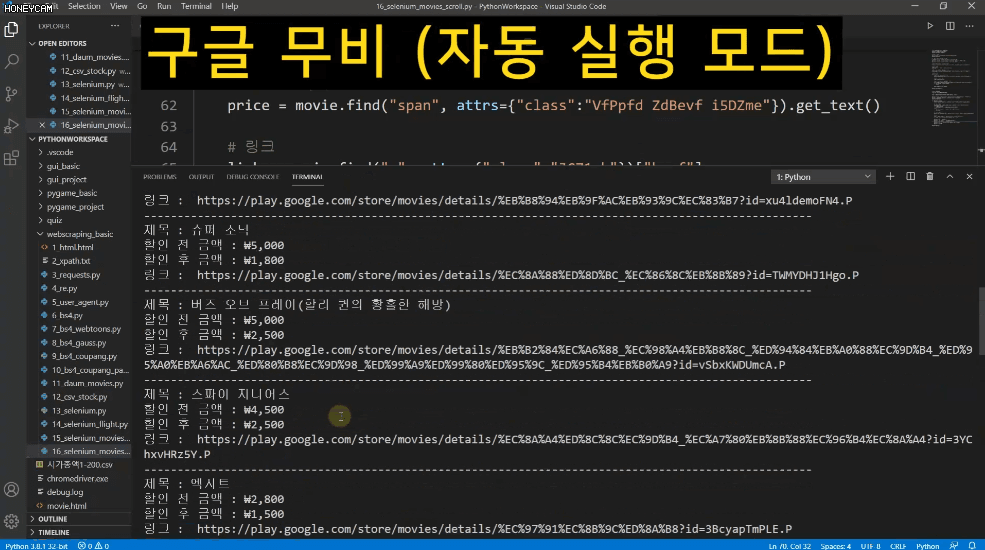
또는 네이버 항공권은 내가 원하는 일정을 입력하고 항공권 조회 버튼을 클릭하면 한참동안 로딩을 하고 나서 목록이 나타나기도 하지요.
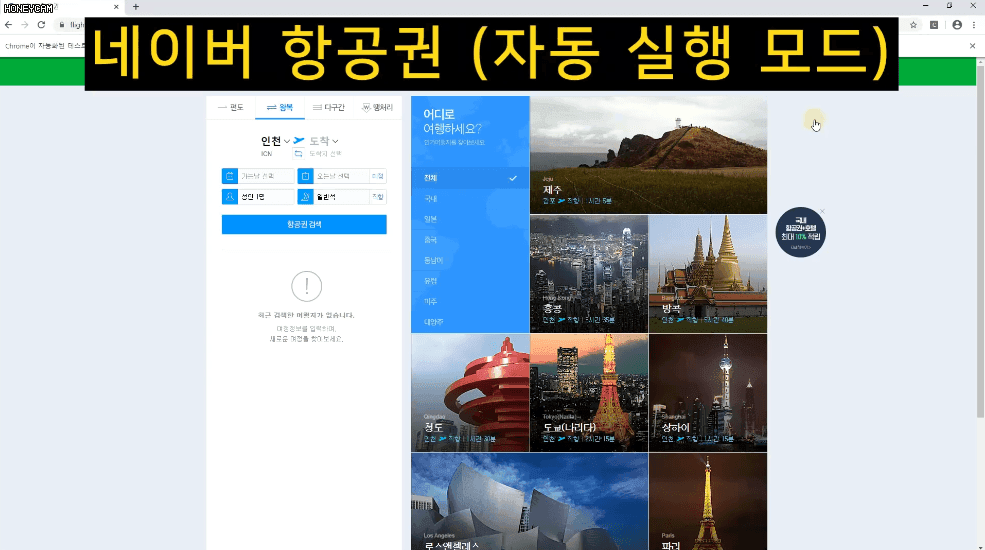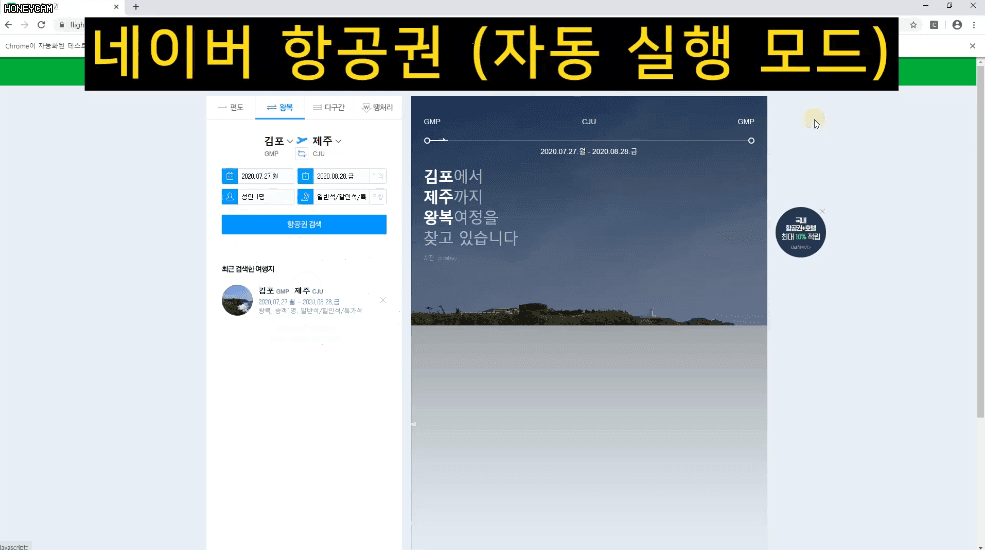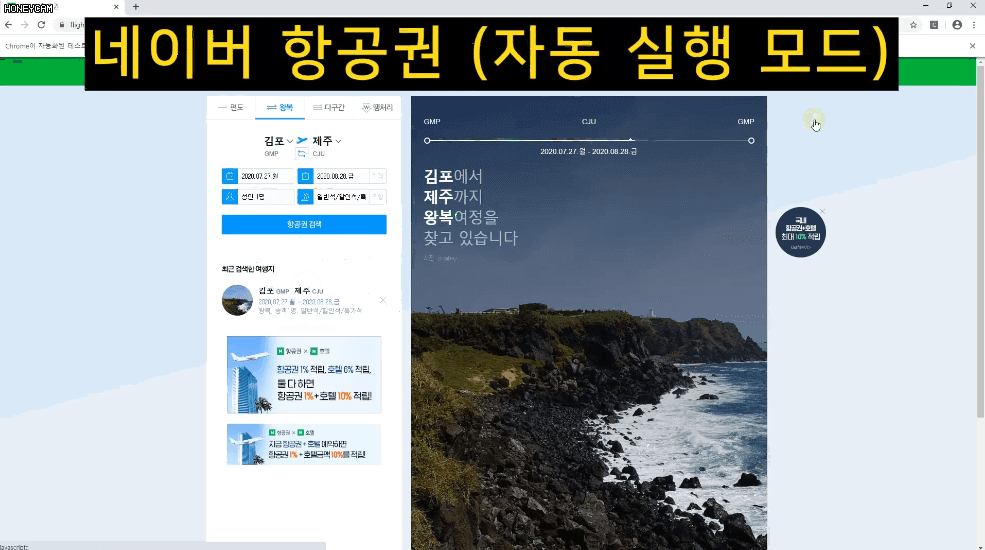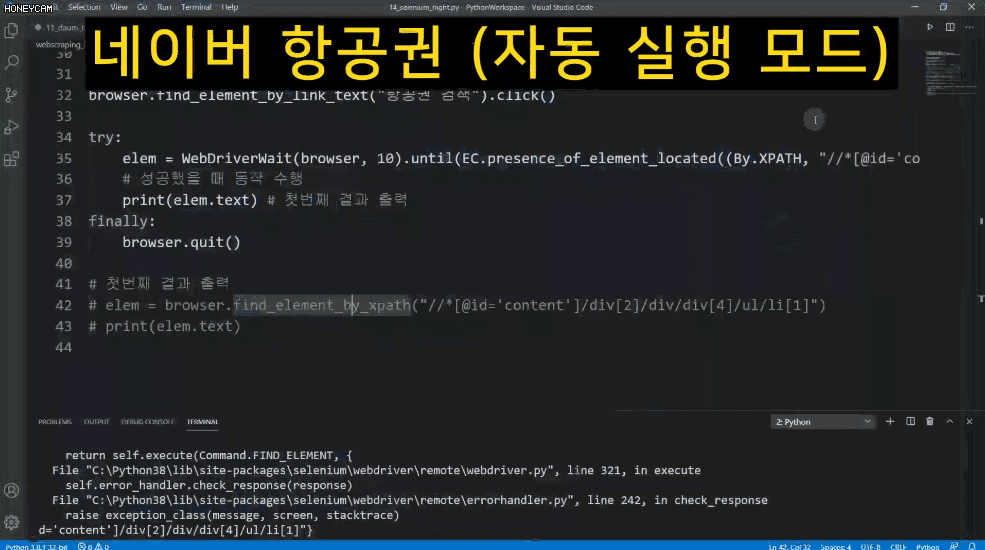
Selenium을 쓸 때도 이런 부분에 대해서는 오류를 줄이기 위해 보다 섬세한 접근이 필요하답니다. 물론 강의에서 모두 알려드립니다.
웹 스크래핑을 배우기 위해서는 사전지식이 필요한데요, 기본적으로 웹에 대해서 이해를 해야하기 때문에 간단히 HTML, XPath에 대해서 공부하고, 크롬(Google Chrome)을 활용하기 때문에 크롬 및 개발자도구 이용 방법에 대해서도 설명드립니다. 그리고 스크래핑 과정에 정규식이 필요할 수도 있어서 아주 가볍게 언급합니다. 이 때문에 앞부분에 이론 설명이 조금 길어서 지루할 수 있지만 조금만 지나면 다양한 페이지에 대해 많은 실습이 이루어지므로 조금만 잘 참고 따라와주시면 좋겠습니다.

많은 내용을 공부하다보니 정리가 안되실 수도 있을까봐 WrapUp 시간을 가지구요, 아무래도 웹스크래핑은 지금까지의 활용편 주제와는 달리 다른 누군가가 만든 사이트를 대상으로 사용하는 기술이기 때문에 반드시 주의해야 하는 점에 대해서도 다시 한번 알려드립니다. 바쁘시거나 핵심만 알고싶다 하시는 분은 이 부분만 봐도 강의 전반적인 내용은 파악 가능합니다.
물론 이번에도 퀴즈를 드리지요.
다음 부동산 매물에서 검색한 결과 정보를 직접 여러분이 스크래핑 해오는 시간을 가져보구요,
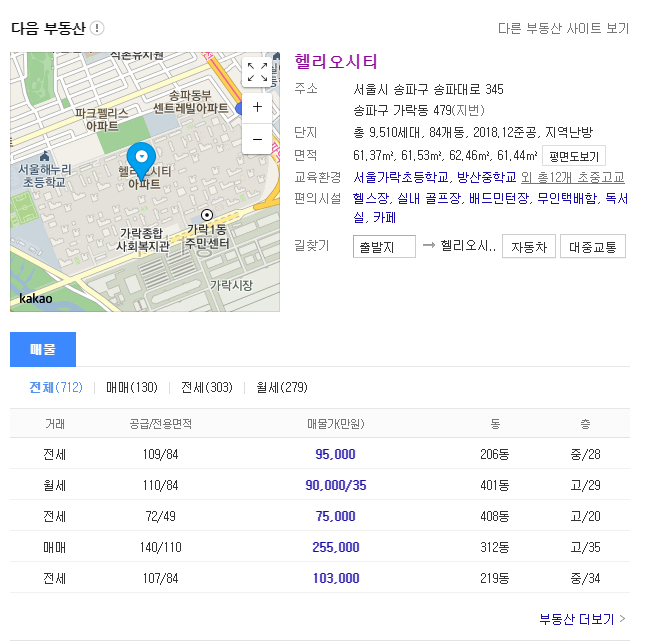
마지막으로는 프로젝트를 진행합니다. 프로젝트 주제는 "나만의 가상 비서" 인데요.
제가 매일 아침에 일어나서 날씨를 확인하고, 주요 뉴스 및 IT 분야 뉴스를 읽는 것을 쉽게 해주는 프로그램을 만들겁니다. 하는 김에 1일 1영어 학습을 위해 매일 새로운 영어 회화 지문을 가져오는 것도 함께 해봅니다. 클릭 한 번이면 이 모든 정보들이 제가 원하는 형태로 가져와지는 것이죠.

굉장히 편하겠죠? ^^
링크를 클릭하면 바로 뉴스 기사를 읽을수도 있게 됩니다. 그리고 이번 주제에서 다루지는 않지만 위에서 가져온 데이터를 이메일이나 카톡 등으로 보내면 매일 아침 아주 손쉽게 정보를 얻을 수 있을 겁니다.
파이썬 기초 문법을 배우신 후 실력을 쌓고 싶으신 분들이라면, 지금 바로 웹 스크래핑을 배워보세요.
이 영상 하나면 충분합니다.
거기에다 나도코딩은 "무료"입니다.
Designed by freepik
https://www.freepik.com
이런 분들께
추천드려요!
학습 대상은
누구일까요?
파이썬을 배웠는데 어디에 활용할지 고민이라면
웹에서 필요한 데이터를 하나 하나 복사 붙여넣기 하고 있다면
쇼핑몰 데이터를 몇 초만에 모두 가져오고 싶다면
선수 지식,
필요할까요?
파이썬 기초
안녕하세요
나도코딩입니다.
96,147
명
수강생
2,810
개
수강평
907
개
답변
4.9
점
강의 평점
11
개
강의
유튜브에서 코딩 교육 채널을 운영하고 있는 나도코딩입니다.
누구나 쉽고 재미있게 코딩을 공부하실 수 있도록 친절한 설명과 쉬운 예제로 강의합니다.
코딩, 함께 하실래요? 😊
🧡 유튜브 나도코딩
🎁 코딩 자율학습 나도코딩의 파이썬 입문
📚 코딩 자율학습 나도코딩의 C 언어 입문
커리큘럼
전체
39개 ∙ (5시간 26분)
HTML
09:24
XPath
11:20
크롬
03:32
Requests
07:40
정규식 기본 1
11:24
정규식 기본 2
08:03
User Agent
07:42
BeautifulSoup4 기본 2
09:34
CSV 기본 1 (네이버 금융)
08:44
CSV 기본 2
06:24
Selenium 기본 1
11:23
Selenium 기본 2
05:56
Selenium 활용 1-2
05:33
Selenium 활용 2-2
10:21
Selenium 활용 2-3
09:58
Selenium 활용 2-4
04:43
Headless 크롬
08:13
Wrap Up
08:41
퀴즈 (다음 부동산)
10:51