
입문자를 위해 준비한
[데이터 분석] 강의입니다.
이런 걸 배울 수 있어요
TEXTOM을 활용한 빅데이터 분석
빅데이터 분석에 대한 실전 예제들
1:1 코칭 예시텍스톰 사용이 어려우시다구요? 📊
이 강의로 여러분의 시간을 아껴드립니다!
(참고)24년에 리뉴얼된 TEXTOM24 신버전
강의가 추가되었습니다.
(계속 해서 최신 강의를 리뉴얼해드립니다!)
본 강의는 Textom입문자,초보자를 위한
기초적인 내용을 강의하고 있습니다
미리보기를 하시고 난 후
원하시는 내용이라면 수강해주세요!
(참고: 중급자용 강의)
시중에 있는 텍스트마이닝 강의들을 보고, 직접 분석이 가능하신가요?
“이론이 아니라 실제 분석에 적용한 예시나 실습 예제가 있었으면 해요.”
“동향분석, 인식분석 등 논문을 쓸 수 있게 하는 텍스트마이닝 강의가 필요합니다.”
👉 이런 후기들을 보고 저는 강의를 찍기로 마음먹었습니다.
요즘 트렌드인 빅데이터 분석,
비즈니스/연구에서 쓰이지 않는 분야가 없습니다.

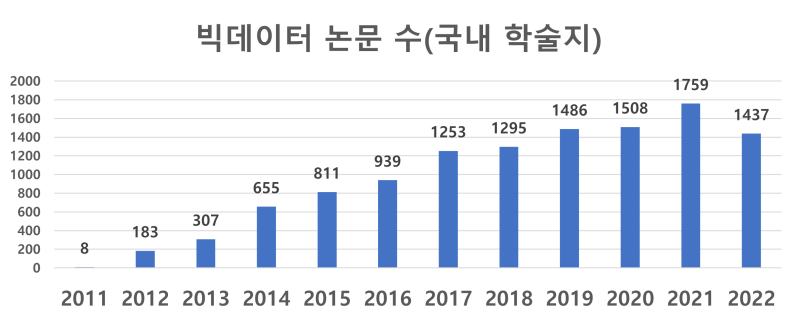
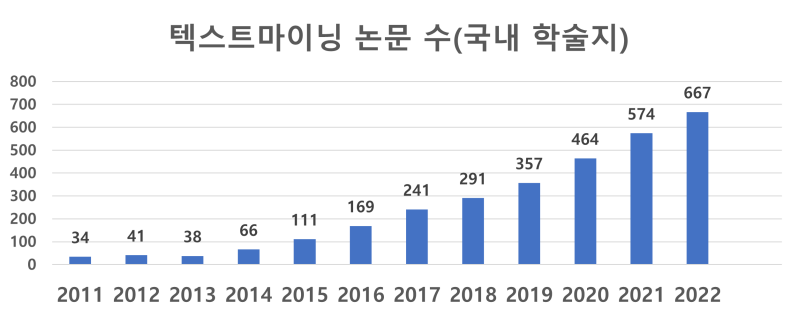
텍스트마이닝(Text Mining)은 점점 연구하는 데 필수적인 분석법이 되어가고 있습니다. 대세로 자리잡은 만큼, 많은 사람들이 배우고자 합니다.
텍스트마이닝을 위한 텍스톰
텍스톰(TEXTOM)은 코딩 없이 텍스트마이닝을 할 수 있는 좋은 프로그램입니다.
하지만 강의나 책을 보아도 텍스톰의 실제 사용법을 몰라서 많은 대학원생, 연구원, 직장인 분들이 시간을 허비하고 스트레스와 부담을 받고 있습니다.

직접 논문을 써보지 않은, 실무 경험 없는 강사?
“빅데이터 분석” 방법을 제대로 알려줄 수 없습니다.
텍스톰 하나로 반나절만에 빅데이터 분석을 완성한 핵심 노하우와 비법을 공개하겠습니다.
독학 절대 하지 마세요.
텍스트마이닝은 분석 기법이 너무 다양합니다.
자주 쓰이는 분석 기법, 사용법도 모르고 온전히 이론과 매뉴얼만 보고 진행하면 무조건 시간 손해입니다.
실무나 빅데이터 논문에서 자주 쓰이는 기법들을 위주로 실습을 한 후, 점점 이론적인 기반을 탄탄히 해야 나중에는 자유자재로 텍스트를 분석할 수 있습니다.
즉, 텍스트 분석에서 무엇이 중요한지 중요하지 않은지를 알아야 합니다. 이를 알면 짧게는 몇 주, 길게는 몇 달의 시간이 절약됩니다.
저에게는 이미 수백 번의 텍스톰 분석 경험을 통해 노하우가 축적되어 있습니다. 재능 공유 플랫폼(크몽)에서 데이터 분석 상위 2%에게 주어지는 Prime 전문가이기 때문에 ‘유일하게’ 가능한 이야기입니다.
효율적인 학습과 실제 적용을 위해, 이 강의로 텍스톰을 시작하시는 걸 권해 드립니다.
빅데이터 분석 , 이제 직접하세요.
고리타분한 이론 설명 대신 실전에 쓰이는 기법만 모았습니다.
텍스트마이닝을 배우기가 어려운 이유는 실전 예제 연습 없이 이론만 배웠기 때문입니다.
직접 구현해 보지 않으면 결코 분석을 할 수 없습니다.
빅데이터 분석을 자유자재로 하려면, 텍스톰을 통해 직접 스스로 실습을 해서 텍스트마이닝을 깊이 있게 이해해야 합니다.
연구 논문에 필요한 데이터를 추출할 만큼 가이드해드리겠습니다.
잘 정의된 핵심 개념에 대한 설명과 텍스톰을 활용한 실전 연습을 통해 여러분이 실무를 하거나 연구 논문을 작성하는 데 있어서 텍스트마이닝 분석을 자신있게 적용하는 전문가 수준으로 가이드해드리겠습니다.
실무에서 활용할 수 있는 핵심 기법만 담았습니다.
모든 연구 분야에서 점점 텍스트마이닝, 빅데이터를 도입합니다.
회사 실무 역시 텍스트 데이터를 다룰 줄 알아야 인정받을 수 있습니다.
요즘 대세인 빅데이터 및 텍스트마이닝을 복잡하고 어려운 코딩 없이 누구나 쉽게 따라할 수 있게끔 실전 연습 위주의 텍스톰 강의를 제작하였습니다.
실제 실무에서 사용하는 텍스트마이닝의 핵심적인 기법을 중심으로, 실무에서 쓰이지 않는 기능은 과감하게 생략한 축적된 실전 노하우를 담아 강의를 제작하였습니다.
- ✅ 실무에 통하는 텍스톰 데이터 추출
- ✅ 빅데이터 논문 작성을 위한 텍스톰 활용법

🚩 저 또한, 처음 텍스톰을 쓸 때 정말 많은 시행착오를 겪었습니다.
‘이럴 땐 텍스톰을 어떻게 사용해야 하지?’ 인터넷이나 매뉴얼을 뒤져보았지만... 시중에 있는 텍스톰 설명이나 강의들은 너무 이론 위주의 설명만 해서 초보자가 이해하기엔 너무 어려웠고, 이리저리 여러 메뉴를 찾으며 몇 날 며칠을 고민 끝에 해결한 기억이 있습니다.
초심자 시절의 저처럼 텍스톰을 사용하기 막막할 때 ‘누군가 옆에서 가이드 해줄 수 있었다면 좀 더 수월하게 빅데이터 분석도 하고 논문도 쓰지 않았을까?’ ‘텍스톰을 처음 접하거나 사용법을 찾는 사람들에게 가이드가 될 만한 강의가 있다면 정말 편할텐데’ 이런 생각을 하면서 이 강의를 준비했습니다.
본 강의는 텍스톰에 대해 장황한 이론적인 설명보다는 실제로 데이터 추출하는 과정을 직접 시연하며 빅데이터 분석에 대한 감을 잡을 수 있도록 강의를 구성하였습니다. 여러 번 반복해서 따라하시다 보면 파이썬 코딩 없이 누구나 빅데이터 분석, 텍스트마이닝 기법을 활용하실 수 있습니다.
실전 사용법 위주의
텍스트마이닝 강의입니다.
본 강의는 주로 이론적인 설명보다는 텍스트마이닝을 위한 텍스톰 실전 사용법에 초점을 맞춥니다.
강의를 듣고 따라하시면 동향 분석, 인식 분석 등 빅데이터 분석을 직접하실 수 있도록 강의를 구성하였습니다.

텍스트마이닝에 대한 기본 이론을 간단히 설명한 뒤 본격적으로 텍스톰 프로그램을 통해 직접 빅데이터를 추출해봅니다.
이 과정 속에서 여러분은 자연스럽게 텍스트마이닝을 이해하고, 빅데이터 분석을 하는 방법을 직접 구현할 수 있습니다.
아울러 요즘 트렌드인 SNS 빅데이터 분석을 직접 구현합니다.
텍스트마이닝이나 텍스톰이 무엇인지 어느 정도 이해하고 있고, 텍스톰에서 제공하는 매뉴얼을 가볍게 훑어보신 다음 이 강의로 실습 방법을 배우신다면 매우 빠르게 텍스트마이닝 분석 실력을 업그레이드할 수 있을 것입니다.
이런 분들께 추천합니다!
- 텍스톰으로 텍스트마이닝을 배우고 싶으신 분
- 이론적인 설명보다 텍스톰을 이용한 실제 구현 방법에 대해 알고 싶은 분
- 텍스톰으로 인식 분석, 동향분석 논문을 쓰고 싶은 대학원생, 연구원, 교수 등
💾 수강 전 확인해주세요!
- 실습을 위해 텍스톰 용량 확보가 꼭 필요합니다. 수강 전 텍스톰(TEXTOM) 계정을 만들고 유료 계정으로 최소 10MB 정도를 확보하셔야 합니다.
- 수강생에게 텍스트마이닝 이론에 관한 PPT를 제공합니다.
안녕하세요, 이진규입니다.
지식공유자 이력
- 現 동국대학교 AI 대학원 박사과정 (자연어처리 Natural Language Processing 전공)
- 現 AI 및 빅데이터 전문 스타트업에서 자연어처리 개발
- 前 공공기관 빅데이터 분석 연구원
- 단국대학교 등 파이썬 데이터 분석 및 빅데이터 분석 강의
- 데이터 분석 관련 다수의 개인 과외 경험
- 크몽(Kmong) AI 자연어처리, 빅데이터 분석 Prime 서비스 운영 (크몽 엄선 상위 2% 서비스)
- TEXTOM을 활용한 다수의 빅데이터 논문 작성 및 프로젝트 경험
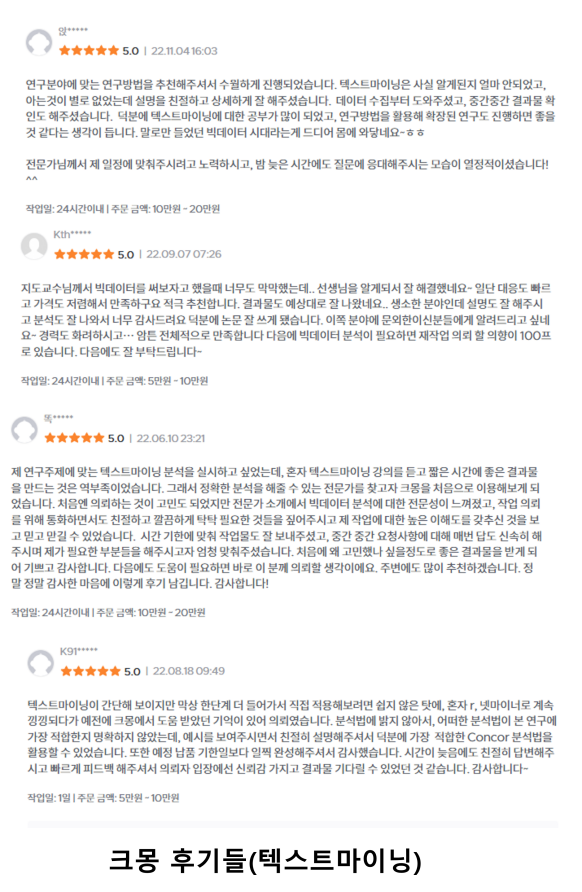
Q&A 💬
Q. 이 강의를 듣고 연구 동향이나 인식분석 빅데이터 논문을 쓸 수 있나요?
빅데이터 논문을 쓰고자 하시는 분들이 이 강의를 활용해 데이터를 추출할 수 있도록 도와드립니다.
Q. 텍스트마이닝을 실무에 적용하려는데 강의를 수강해도 괜찮을까요?
네, 본 강의는 일반적으로 텍스트마이닝에 쓰이는 분석방법에 관한 실습들로 이루어져 있습니다. 실무에 활용하고자 하시는 분들도 강의를 들으시면 좋습니다.
Q. 텍스트마이닝, 텍스톰 초보자인데 들을 수 있을까요?
네, 본 강의는 초보자를 대상으로 한 강의이면서도 실전에 활용할 수 있는 모든 분석 방법을 담았습니다. 그래도 완전 처음이라면 텍스톰 매뉴얼을 한번 읽고 학습하는 것을 추천드립니다.
💡 텍스트마이닝 & 텍스톰을 시작하는 분들께 도움이 되고 싶습니다!
여러분이 궁금해하는 텍스톰 사용법을 직접 하나하나 구현해 드리고, 어려워하는 텍스트마이닝에 대해 핵심 위주로 간결하게 설명해드리며, 여러분이 빅데이터 분석과 연구를 고민할 때 옆에서 손잡아 드리겠습니다. 글 읽어 주셔서 진심으로 감사합니다. 강의에서 뵙겠습니다!
" (참고)강의는 2024년 몇달 동안만 저렴하게 판매합니다. 그 뒤부터는 가격이 상승할예정입니다"
"강의 수강하시고 궁금증이 있다면 제 메일주소(leejinkyu0612@naver.com)나 크몽으로 궁금증을 남겨주시면 1:1로 코칭해 드립니다!"

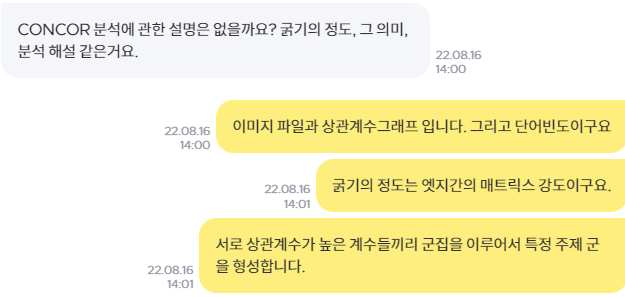
1:1 코칭 예시
이런 분들께
추천드려요!
학습 대상은
누구일까요?
텍스트마이닝을 배우고 싶으신 분
코딩을 모르지만 빅데이터 분석을 하고 싶으신 분
텍스톰 사용 방법을 알고 싶으신 분
이론이 아니라 실제 예시를 통해 텍스톰을 배우고 싶으신 분
선수 지식,
필요할까요?
텍스트마이닝에 관한 기초지식
텍스톰이 처음이라면, 텍스톰 공식 매뉴얼을 한번 읽어보기!
안녕하세요
이진규입니다.
3,002
명
수강생
87
개
수강평
44
개
답변
4.6
점
강의 평점
7
개
강의
안녕하세요 AI와 빅데이터 분석에 진심인 해피AI 이진규입니다.
[강사약력]
이진규 (Lee JinKyu)
해피AI 대표 (Happy AI CEO, HappyNLP CEO)
생성 AI 및 빅데이터 분석 분야의 최신 트렌드, 인사이트, 기술 활용 방법을 깊이 있게 전달합니다.
🎒 강연 및 외주 문의
[email] leejinkyu0612@naver.com
[Blog] 📺 https://blog.naver.com/leejinkyu0612
[YouTube] 📺 https://www.youtube.com/@HappyAI_0612
[github] https://github.com/leejin-kyu/
[Homepage] https://happyaidata.kr
[H.P] 010-9973-2113
[kakao] jinkyu0612
📘 크몽 Prime 전문가(상위 2%)📺 https://kmong.com/gig/345782
삼성전자, 서울대, 교육청, 한국데이터산업진흥원, 이화여자대학교, 서울기술연구원, 경기연구원, 청운대학교,한국대기환경학회, 국립공원관리공단, 서울디지털재단, 세종대학교, 전남대학교 등 다수의 정부기관 및 교육기관 프로젝트 진행
의료,커머스,생태,법학,경제,예체능 등 다양한 도메인의 연구경험(총 연구 프로젝트 200회 이상 진행)
📘 Bio
- 2024.07~ 생성 AI 및 빅데이터 분석 전문기업 해피AI 대표
- 2023.01~ 생성 AI 기반 빅데이터 분석 전문기업 해피NLP
- 2022. 동국대학교 AI대학원 박사과정 수료(자연어처리 및 LLM 전공)
- 2023~ 퍼블릭 뉴스 AI 칼럼니스트(AI편향 및 RAG챗봇 전문)
- 2021~2023 AI/빅데이터 전문 기업 스텔라비전 개발자
- 2018~2021 공공기관 자연어처리/빅데이터 분석 연구원 (인문사회과학 데이터 연구)
- 2021 자연어처리/빅데이터 전문기업 Textom 최우수 Analyst
🎒Courses & Activities
2024
Langchain 및 RAG 등 LLM 프로그래밍.삼성SDS(2024)
ChatGPT 기반 빅데이터 분석 입문. 렛유인에듀 (2024)
인공지능 기초 및 데이터 분석 기초 강의. 한국직업개발원 (2024)
LLM 실무자를 위한 LLM이론 및 Langchain 기반 RAG챗봇 개발 강의. 서울디지털 재단 (2024)
텍스톰(Textom)을 활용한 텍스트마이닝(연구동향, SNS) 논문 작성법 강의. 인프런 (2024)
쉽게 따라하는 LDA & 감성분석 빅데이터 논문 작성법 with ChatGPT. 인프런 (2024)
파이썬을 활용한 텍스트 분석 강의. 서울과학기술대학교 (2024)
파이썬 초보자를 위한 주가 데이터 분석 입문 강의. 인프런 (2024)
연구자와 대학원생을 위한 감성분석 기법 실습 강의. 인프런 (2024)
랭체인(LangChain)을 활용한 LLM 챗봇 만들기(feat.ChatGPT). 인프런 (2024)
2023
ChatGPT를 활용한 파이썬 기초 강의. 경기대학교 (2023)
빅데이터 전문가 과정 특강. 단국대학교 (2023)
빅데이터 분석 기초 강의. 렛유인에듀 (2023)
💻 Projects
LLM 기반 산림 복원 빅데이터 분석(국립산림과학원)
Private LLM 기반 RAG 챗봇 모델 구축 (한국전력공사)
AI 기반 빅데이터 분석 기법을 적용한 설문 데이터 분석 (A정부기관)
빅데이터 분석 기법을 통한 이용자 설문 데이터 분석 및 시각화 (코멘터리 사무소)
내부망 전용 LLM을 활용한 텍스트마이닝 솔루션 개발 (D 정부기관)
빅데이터 분석을 통한 한우시장 트렌드 분석 (이화브리오)
Instruction Tuning 및 강화학습(RLHF)을 통한 LLM 모델 개발 (서울디지털재단)
AI 언어모델 기반 헬스케어 서비스의 사용자 리뷰 텍스트 분석 (삼성전자)
단어 임베딩 유사도를 활용한 Word2Vec 언어 모델 기반의 텍스트마이닝 기법을 활용한 설문 빅데이터 분석 (정림건축)
AI 언어 모델 기반 텍스트마이닝 기법을 활용한 SNS 인식 분석 (LMC)
자연어 처리 기술 기반 텍스트마이닝을 활용한 연구동향 분석 (한국대기환경학회)
AI 모델 kopatBERT 기반 특허 논문 QA 모델 개발 (한국기술마켓)
자연어 처리 기법을 활용한 설문 질적연구 자료 분석 (청운대학교)
AI 모델 kopatBERT 기반 특허 논문 분류 모델 개발 (한국기술마켓)
딥러닝 기반 토픽모델링을 활용한 법학 설문 빅데이터 분석 (서울대학교)
딥러닝 및 머신러닝 기반 텍스트 분석 기법을 활용한 간호 설문 질적연구 자료 분석 (충북대학교)
KorQuad를 활용한 BERT 기반 금융권 QA task 모델링 (B사)
학술 데이터의 특성에 따른 Bert 기반 Multi-classification 모델 개발 (A사)
인공지능 자연어 처리(NLP) 분야에 대한 최신 트렌드 및 기술 경향 분석 (Textom)
AI 모델 Word2Vec 및 TF 기반 의료 설문 빅데이터 Keyword 추출 알고리즘 개발 (D사)
AI 모델 Word2Vec과 감성분석을 적용한 설문 문항 빅데이터 분석 (경기연구원)
딥러닝 기반 비대면 진료 관련 언론기사 토픽 분석 (한국보건의료연구원)
언론보도 분석을 통한 캠핑 트렌드 인사이트 도출 (한국관광컨설팅)
AI 모델 RNN 기반 리뷰 인사이트 추출 및 분석 프로그램 개발 (서클플랫폼)
주요 언론사 빅데이터 분석을 통한 안전사고 유형 분석 (서울기술연구원)
뉴스 빅데이터 분석을 통한 '나는 SOLO' 인기 요인 분석 (Textom)
우크라이나 러시아 전쟁에 대한 국민인식 분석 (Textom)
주요 도서 카테고리별 크롤링 프로그램 개발 및 빅데이터 분석 (데이원컴퍼니)
AI 모델 Word2Vec 기반 텍스트마이닝 솔루션 프로그램 개발 (서클플랫폼)
데이터 인력 분석을 위한 정보 수집 프로그램 개발 및 빅데이터 분석 (한국데이터산업진흥원)
헬스케어 스토어 상품 리뷰 분석 (오므론헬스케어)
기업 인터뷰 설문 빅데이터 분석 (인피플컨설팅)
빅데이터 분석을 통한 여성원피스에 대한 니즈 분석 (Textom)
NLP 기법을 활용한 정맥간호 관련 인식 분석 (울산대학교)
빅데이터 분석을 통한 인공지능에 대한 언론 보도경향 분석 (Textom)
빅데이터 분석을 통한 축산물 트렌드 파악 및 분석 (중원푸드)
빅데이터를 활용한 2022년 국립공원 탐방 키워드 분석 (국립공원관리공단)
빅데이터 분석을 통한 서울맛집에 대한 인식 분석 (Textom)
빅데이터 분석을 통한 재테크에 관한 언론보도 분석 (Textom)
언론보도 분석을 통한 '골때리는 그녀들'에 대한 인기 요인 도출 (Textom)
쇼팽 콩쿠르에 대한 언론보도 동향 분석 (Textom)
월드컵 최종예선에 대한 국민인식 분석 (Textom)
위드코로나에 대한 국민인식 분석 (Textom)
(언론보도자료) 빅데이터를 통해 본 국내 주요 숲길의 인기 비결 (국립산림과학원)
(언론보도자료) 빅데이터가 말하는 인제 자작나무 숲의 인기 비결 (국립산림과학원)
빅데이터 분석을 통한 숲길 네트워크 구축 및 관리방안 도출 연구 (국립산림과학원)
해외 휴양공간 빅데이터 제공 시설 구성요소 및 위계 분석을 통한 정보 서비스 체계 구축 (국립산림과학원)
빅데이터 분석을 통한 산림휴양공간 핫스팟 지역 수요 예측 및 관리 기술 개발 (국립산림과학원)
국내 주요 산림휴양공간별 빅데이터 분석을 통한 네트워크 체계 구축 및 중·장기 운영관리 로드맵 제시 (국립산림과학원)
데이터 마이닝을 통한 산림 휴양공간 이용자 인식 도출 및 운영관리방안 설계 (국립산림과학원)
GIS 공간데이터 및 비정형 텍스트 정보 자료 분석을 통한 DMZ 숲길 최적 노선 기술 개발 및 현장 적용성 검토 (국립산림과학원)
이외에도 다수의 공공기관, 기업체와 개인적 의뢰 등 총 200건 이상 프로젝트 진행
📖 Publication
Improving Commonsense Bias Classification by Mitigating the Influence of Demographic Terms.IEEE Access, JinKyu Lee, and Jihie Kim.2024. 논문 링크
Improving Generation of Sentiment Commonsense by Bias Mitigation" International Conference on Big Data and Smart Computing (BigComp). JinKyu Lee, and Jihie Kim.2023. 링크
Vanilla 프롬프팅 기법과 CoT 프롬프팅 기법 간 음악 편곡 결과 비교 분석 | 게임학회 | 2024
언론기사 빅데이터 분석을 통한 대규모 언어모델에 대한 기술 인식 분석: ChatGPT 등장 전후를 중심으로 | 한국멀티미디어학회 | 2024 논문 링크
정맥간호 인터넷 카페 Q & A 게시글의 키워드 네트워크 분석 | Healthcare Informatics Research | 2023.02 논문 링크
자연어 처리(NLP)기반 텍스트마이닝을 활용한 소나무에 대한 국내외 연구동향(2001∼2020)분석 | 농업생명과학연구 | 2022 논문 링크
텍스트마이닝을 활용한 백두대간에 관한 연구동향(2001‒2020) 분석 | 한국산림과학회지 | 2022 논문 링크
텍스트마이닝을 활용한 국내 산림생태 분야 연구동향(2001‒2020) 분석 | 한국산림과학회지 | 2022 논문 링크
(NLP) 편향(Bias) 완화를 통한 감성 상식(Commonse)문장 생성 향상 기법 연구 (BART모델 사용) 논문 링크
숲길에 대한 10 년간의 언론 인식분석-텍스트 마이닝 분석을 중심으로 | 산림경제연구 | 2021
산림관광지로서 인제 자작나무 숲에 대한 소셜미디어 이용자 인식 연구 | 한국산림휴양학회 | 2020
이외에도 타 분야에서 다수의 학술논문, 학술발표, 연구보고서 등의 성과 창출
Others
Python을 활용한 데이터분석 및 시각화
LLM을 활용한 데이터분석
ChatGPT와 LangChain을 활용한 업무 생산성 향상
커리큘럼
전체
78개 ∙ (9시간 38분)
해당 강의에서 제공:
[이론]LDA분석기법 소개
04:41
RISS 연구논문 데이터 수집하기
03:04
데이터 정제하기
08:21
데이터분석하기 - 빈도분석
08:33
빈도분석 후 데이터 전처리하기
09:30
N-gram분석하기
10:38
Tf-IDF분석하기
08:17
네트워크분석하기-에고네트워크분석
05:06
CONCOR분석
07:08
클러스터링
06:35
LDA토픽모델링 -토픽파라미터설정하기
07:07
[실습] 데이터 해석법(CONCOR)
04:16
[실습] 데이터 해석법(감성분석)
04:51