
중급자를 위해 준비한
[데이터 엔지니어링, 데브옵스 · 인프라] 강의입니다.
이런 걸
배워요!
KSQLDB의 기반 개념부터 Advanced 아키텍처까지
Stream과 Table의 차이, 그리고 Stateful(상태가 있는) Streaming 처리 메커니즘
KSQLDB 주요 오브젝트들의 생성 및 관리 정보, 다양한 Data 타입의 이해
KSQLDB에서 RocksDB 동작 메커니즘
KSQLDB의 다양한 쿼리 구문과 함수 이해
Group by 와 Mview 이해와 활용, 그리고 특수성과 제약
다양한 유형의 KSQLDB 조인 이해와 활용 그리고 특수성과 제약
여러가지 유형의 Window들의 이해 및 Time 기반 Window Aggregation과 Window 조인의 동작 메커니즘
KSQLDB에서 Connect 활용
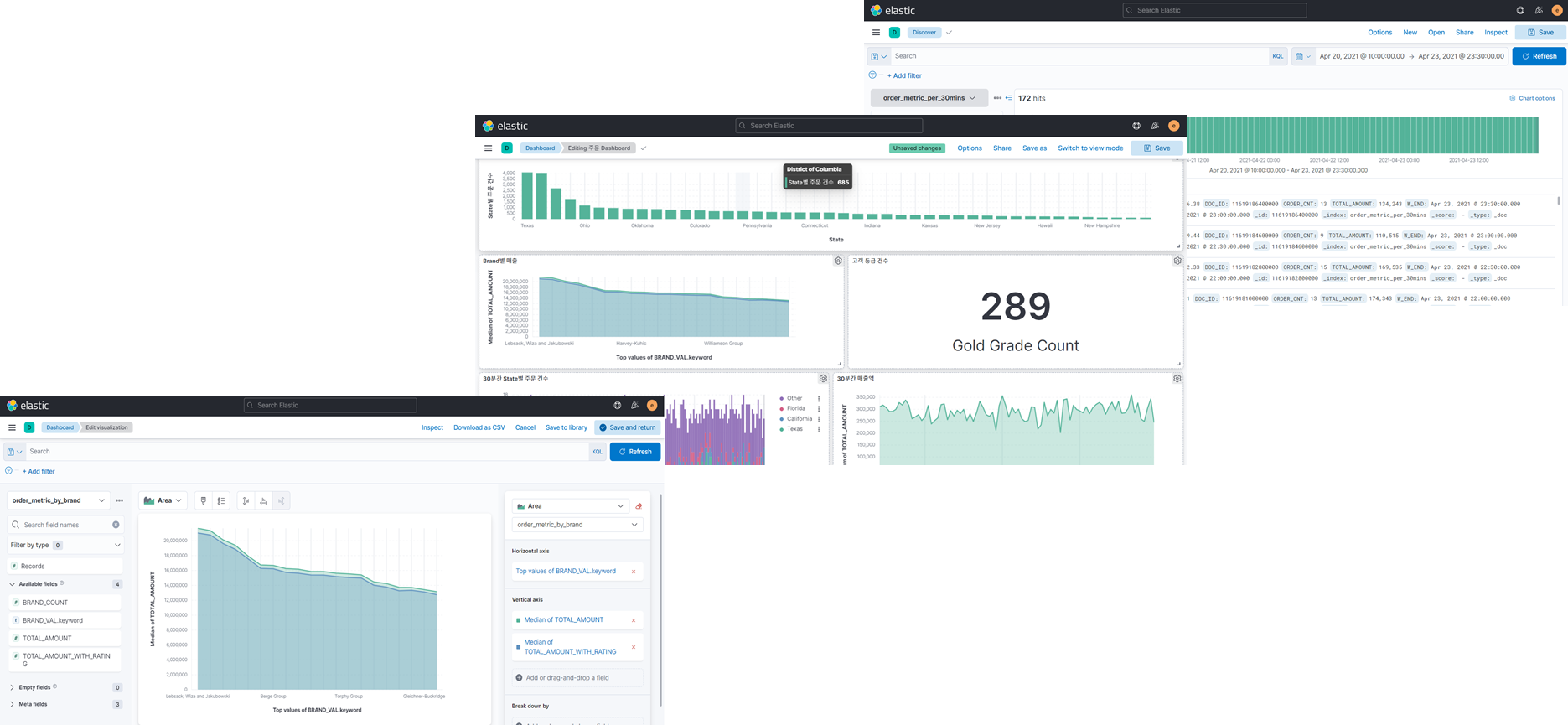
KSQLDB와 Elasticsearch 연동 및 Kibana를 통한 분석 결과 시각화
대용량 실시간 스트리밍 분석 시스템,
Kafka + ksqlDB로 쉽고 강력하게!
실시간 스트리밍 데이터 분석의
효율과 확장성을 잡고 싶다면?

Kafka(카프카)를 사용하고 있다면, 대용량의 실시간 스트리밍 분석 시스템을 구현하는 가장 쉽고 빠른 방법은 바로 ksqlDB를 이용하는 것입니다.
Kafka와 통합되어 설치 및 구동되는 ksqlDB는 복잡한 Streaming API를 사용하지 않고, 단 몇 줄의 SQL 코드만으로도 간단하게 실시간 스트리밍 데이터의 가공/변환/분석 작업을 수행할 수 있습니다.

 컨플루언트 공식 페이지에서 발췌 (링크)
컨플루언트 공식 페이지에서 발췌 (링크)
이미 국내외 유수 기업들이 과거와 비할 수 없을 정도로 대용량이면서 빠른 Latency를 가지는 스트리밍 데이터를 실시간으로 분석하고 즉각적으로 해당 결과를 반영하려는 요구사항에 직면하고 있으며, 이를 위해 ksqlDB를 적극적으로 도입하고 있습니다.
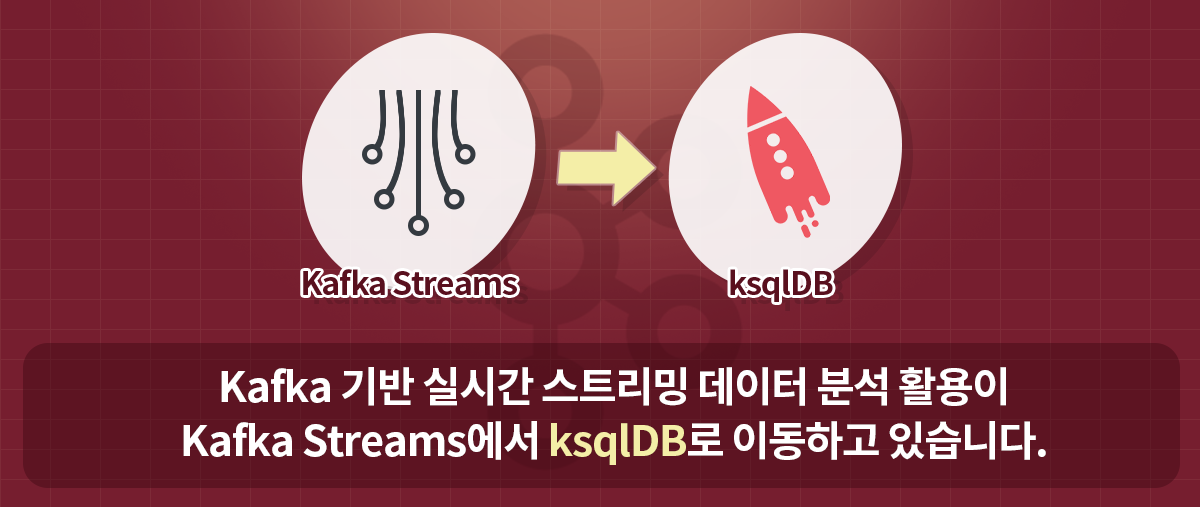
과거에는 Kafka 기반의 실시간 스트리밍 데이터 가공/변환/분석을 위해 복잡한 Kafka Streams API를 활용했지만, 지금은 간단한 쿼리만으로도 쉽고 빠르게 스트리밍 분석 시스템을 구축할 수 있는 ksqlDB가 실시간 스트리밍 데이터 분석 시스템 구축을 위한 대세가 되어 가고 있습니다.
빠르게 성장하는 ksqlDB, 그리고 부족한 전문가
ksqlDB는 SQL 기반의 쉽고 편리한 구현 등 여러 장점으로 인해 기존의 카프카 Streams API를 빠르게 대체하며 성장하고 있습니다.
하지만 ksqlDB를 실무에 활용할 정도의 실력을 갖춘 현업 인력을 찾기는 매우 어렵습니다. ksqlDB가 비교적 최근에 부각된 솔루션임과 동시에, ksqlDB를 다루는 대부분의 자료나 강의가 피상적인 개념 위주의 내용으로 구성되어 실무에서 필요로 하는 실력을 쌓기에는 부족함이 많았기 때문입니다.
실시간 대용량 스트리밍 데이터 처리 애플리케이션을 쉽고 빠르게.
‘카프카 완벽 가이드 - ksqlDB’는
본 강의는 여러분을 ksqlDB 전문가로 성장할 수 있도록 실전적인 내용으로 구성되어 있습니다. 우리의 목표는 이를 통해 기업이 원하는 ksqlDB 전문 인력으로 한층 더 발돋움할 수 있게 되는 것입니다.

✅ 번번이 ksqlDB의 높은 벽에 가로막히신 분
✅ ksqlDB의 핵심 메커니즘을 이해하고 싶으신 분
✅ 업무에 즉각적으로 ksqlDB를 활용하고 싶으신 분
이에 본 강의는 수강생 여러분들이 실무에서 바로 ksqlDB를 활용하기 위해서 반드시 체득해야 할 내용들로 채워져 있습니다.
이 강의만의 특징을
확인해보세요.
상세한 시각자료와 실습을 통해 ksqlDB 주요 구성요소들의 핵심 동작 메커니즘을 체득
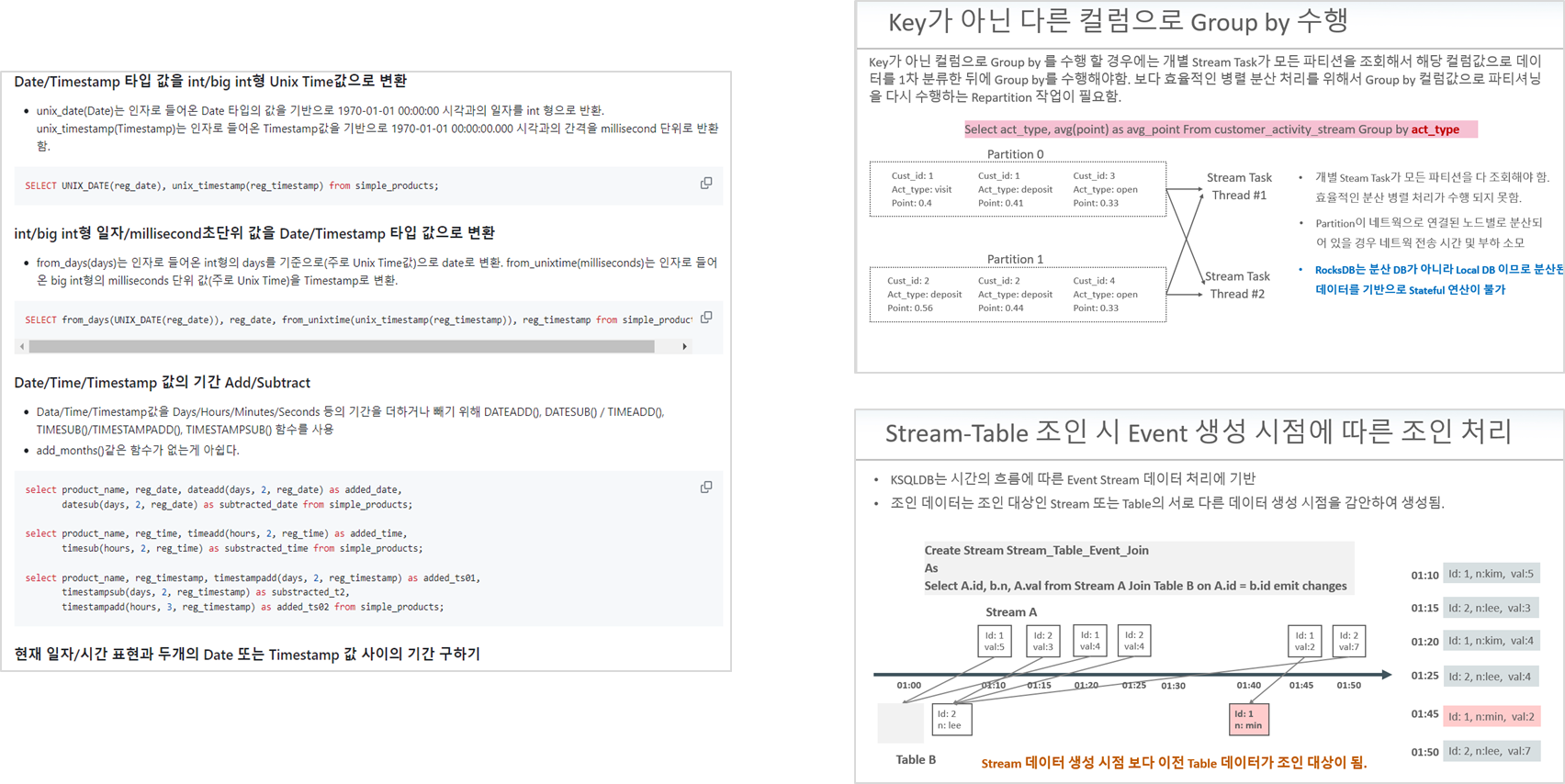
ksqlDB는 일반 RDBMS와 비슷한 부분도 있지만, 상당히 다른 부분이 많습니다. 때문에 ksqlDB를 잘 다루기 위해서는 주요 구성 요소인 Stream, Table, Query, Mview, RocksDB 등의 동작 메커니즘을 상세히 이해하고 있어야 합니다. 본 강의는 상세한 시각자료와 실습을 통해 ksqlDB의 핵심 메커니즘을 체득할 수 있도록 도와드릴 것입니다.

ksqlDB 고유의 다양한 함수, 조인, Group by, Window 활용 및 실무 활용을 위한 실전 실습까지
ksqlDB를 실무에서 잘 활용하려면 ksqlDB에서 제공하는 여러 함수들을 조인 및 Group by, 그리고 Window 사용 방법을 잘 알고 있어야 합니다. 특히 ksqlDB의 조인, Group by, Window는 SQL과는 다른 제약점들이 있으며, 이들을 이해하지 않고서는 ksqlDB를 제대로 활용 할 수 없습니다. 본 강의에서 이들 요소들을 많은 실습을 통해서 직접 수행해 보면서 그 차이를 명확하게 이해하실 수 있을 것입니다.
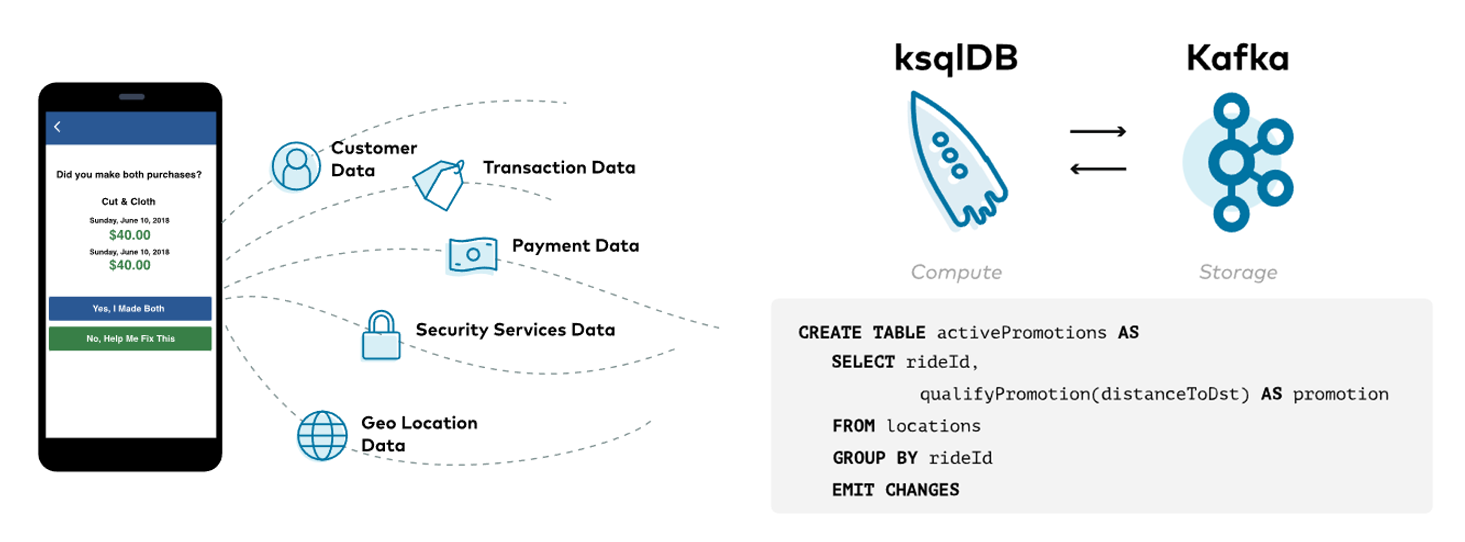
또한 별도로 마련된 '온라인 신발 Shop' 실전 실습 섹션을 통해, 여러분을 실무에서 ksqlDB에서 다양한 실시간 분석을 효율적으로 적용할 수 있는 수준으로 이끌어 드릴 것입니다.

ksqlDB에서 Connect 활용, 그리고 Elasticsearch 연동과 Kibana 시각화까지
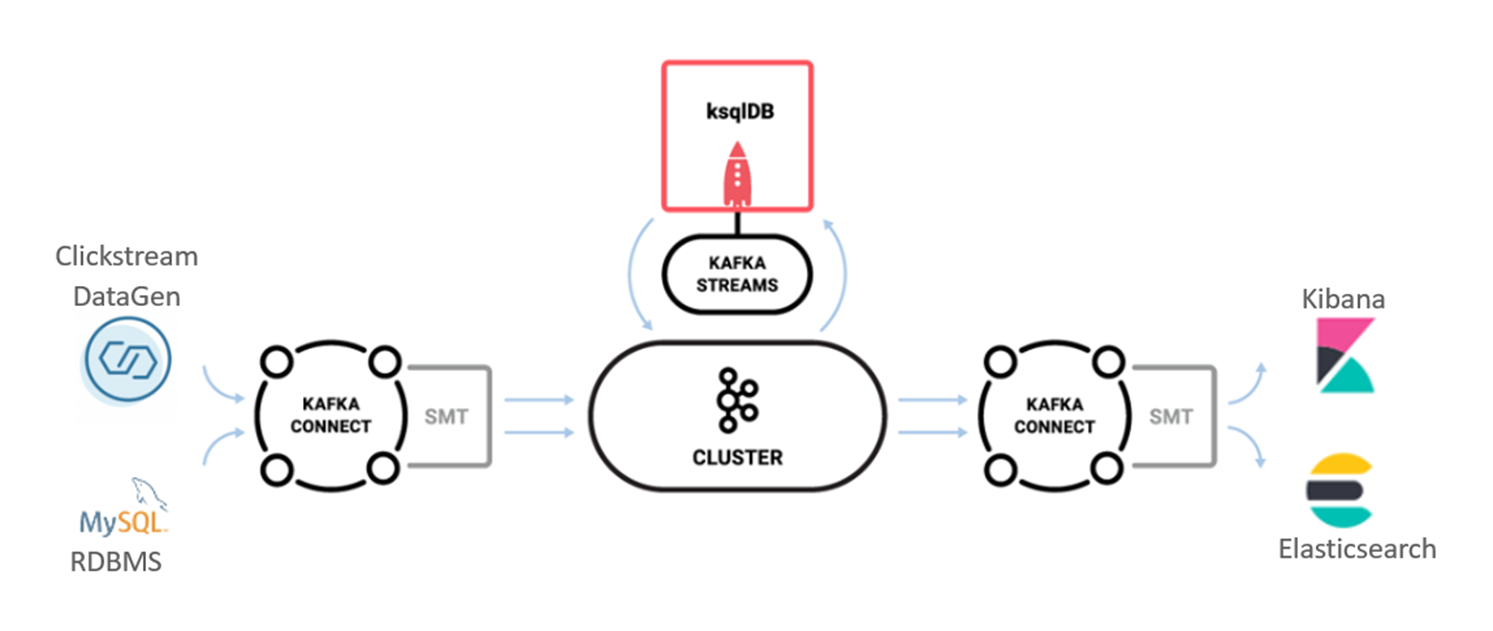
ksqlDB에서 Connect의 통합하고 활용하는 방법을 말씀드립니다. 또한 ksqlDB의 분석 결과를 Elasticsearch로 Connect를 통해서 저장하고 이를 Kibana를 통해 시각화하는 방법을 실습을 통해 익히실 수 있습니다.
ksqlDB 초보에서 전문가 수준으로 이끌어 드립니다.
⚙️
ksqlDB 주요 구성 요소들의 핵심 메커니즘
🔎
Stream과 Table의 차이 및 활용 방법, 주요 오브젝트들의 생성 및 관리
🧰
실습을 통한 ksqlDB의 다양한 쿼리 구문과 주요 함수의 이해
📊
ksqlDB 고유의 Group by, MView, Join 이해와 활용, RDBMS와의 차이 및 제약 사항
🔐
여러 가지 유형의 Window에 대한 이해 및 Time 기반 Window Aggregation, Window 조인의 동작 메커니즘 실습
💾
Connect와의 연동 및 Elasticsearch와 Kibana를 통한 분석 결과의 수집 및 시각화
ksqlDB 겉핥기가 아닌, 지금까지의 어떤 강의나 인터넷 자료에서도 찾아볼 수 없었던 핵심적인 내용과 활용법을 담아내기 위해 많은 노력을 기울였습니다. 또한 실습을 통해 이론을 보다 자연스럽게 익힐 수 있도록 다양한 실습 수업으로 커리큘럼을 가득 채웠습니다.
본 강의를 마치신 뒤에는, 누구와 견주어도 손색없는 ksqlDB 전문가로 성장해 있는 자신을 발견하실 수 있을 것입니다.
 상세한 설명, 다양한 실습으로 내용을 충분히 이해할 수 있도록 구성했습니다.
상세한 설명, 다양한 실습으로 내용을 충분히 이해할 수 있도록 구성했습니다.
(수강생 분들께는 100페이지 이상의 강의 교재 PDF를 제공합니다.)
💡 수강 전 참고해주세요!
- 본 강의에서는 ksqlDB만 다루며, Kafka Streams는 다루지 않습니다.
- Macbook M1/M2 모델 PC에서는 Virtualbox VM 호환 실습이 어려울 수 있습니다.
실습 환경
서버 OS

카프카 서버 OS로 오라클(Oracle) VirtualBox VM 기반에서 Ubuntu Linux(우분투 리눅스) 20.04를 이용합니다. 리눅스를 이용하지만 가상 머신 기반으로 구동되므로 Windows/macOS 환경 모두에서 구성할 수 있습니다.
VirtualBox는 Windows/macOS 환경에서 거의 대부분 설치 가능합니다. 다만 Mac의 경우 최신 M1 모델에서 VirtualBox가 설치되지 않으므로 UTM등의 가상환경을 이용하여 Ubuntu를 설치하셔야 합니다. M1 모델의 경우 반드시 가상환경에서 Ubuntu가 설치되는지 확인 후 강의를 선택해 주시기 바랍니다.
컨플루언트 카프카
커뮤니티 에디션
![]()
카프카는 아파치 카프카(Apache Kafka)가 아닌 컨플루언트 카프카(Confluent Kafka) Community Edition 버전 7.1.2를 사용합니다.
컨플루언트는 카프카를 만든 핵심 인력이 주축이 되어 세운 회사로, 기업 고객을 위해 성능 및 편의성 측면에서 보다 향상된 기업용 카프카를 제공하고 있습니다. 아파치 카프카와 100% 호환되면서도 보다 다양한 카프카 모듈 및 일체화된 Binary를 이용할 수 있습니다. 컨플루언트로 강력한 분산형 시스템 카프카를 더욱 탄력적으로 확장 가능한 형태로 사용해 보세요. 인프라 구축 및 유지 관리 부담을 줄이고, 더 빠른 개발을 할 수 있도록 도움을 줄 것입니다.
권장 PC 사양
![]()
전체 실습 환경 구성으로 20~30GB의 스토리지 용량, 4GB 이상의 RAM을 갖춘 PC 환경이 요구될 수 있습니다.
Q&A를 확인해보세요 💬
Q. 이전 강의인 카프카 완벽 가이드 - 코어편이나 커넥트편을 들어야 하나요?
본 강의 중 2개 섹션은 ksqlDB와 Connect의 연동을 다루고 있습니다. 카프카 완벽 가이드 - 커넥트편을 수강하지 않으셨더라도 기본적인 Connect에 대한 이해와 실습 경험은 있으셔야 해당 섹션 실습을 이해하실 수 있을 것 같습니다.
카프카 코어에 대한 이해는 필수적으로 필요합니다. 이전 강의인 카프카 완벽 가이드 - 코어편을 수강하시면 좋습니다. 다만 수강하지 않으셨더라도 카프카의 기본인 Broker, Producer, Consumer의 활용 경험이 있고 핵심 개념이 잘 잡혀 있으시다면 충분히 본 강의를 들으실 수 있습니다.
Q. 강의 수강을 위해 RDBMS SQL경험이 있어야 하나요?
본 강의의 많은 실습이 쿼리를 기반으로 하고 있습니다. 때문에 기본적인 RDBMS SQL 구문 및 Group by와 Join에 대한 활용 경험이 있으셔야 합니다.
이런 분들께
추천드려요!
학습 대상은
누구일까요?
KSQLDB의 주요 구성 요소들을 쉽고 깊이 있게 이해하기 원하는 모든 분들
Kafka 기반에서 대량의 실시간 Streaming 데이터 가공/변환 분석 시스템을 빠르고 효과적으로 구축하고자 하는 데이터 엔지니어
실시간 Streaming 데이터 분석 활용이 필요한 분석가와 데이터 사이언티스트
기존 Producer/Consumer기반 또는 Kafka Streams 기반에서 KSQLDB 기반으로 Application을 Migration하려는 개발자
선수 지식,
필요할까요?
(카프카 완벽 가이드 - 코어편을 수강하셨다면 가장 좋지만, 그렇지 않을 경우) 토픽/프로듀서/컨슈머에 대한 확실한 기본 지식이 필요합니다
카프카 Connect에 대한 기반 지식
많은 실습이 쿼리 기반으로 진행됩니다. 조인과 Group By를 이해하는 기본 SQL 지식이 필요합니다
안녕하세요
권 철민입니다.
(전) 엔코아 컨설팅
(전) 한국 오라클
AI 프리랜서 컨설턴트
파이썬 머신러닝 완벽 가이드 저자
커리큘럼
전체
139개 ∙ 21시간 31분
수업 자료
가 제공되는 강의입니다.
강의 소개
06:34
강의 교재 및 실습 자료 소개
02:01
실습 환경 구축 개요
03:10
오라클 VirtualBox 설치하기
10:09
카프카(Kafka) 설치
08:23
ksqlDB 소개
11:40
Kafka Streams API 이해
13:18
RocksDB 소개
06:30
Stream 개요
09:40
Stream과 Table의 차이
10:28
Stream의 메타 정보 확인 하기
07:30
Key를 가지는 Stream의 생성
08:22
Pull 쿼리와 Push 쿼리의 이해
09:30
Query 오브젝트의 이해
15:50
Rowtime 필드 이해
05:55
마지막 업데이트일: 2023년 10월 12일