
![[R로 하는] 머신러닝을 위한 통계학 기초강의 썸네일](https://cdn.inflearn.com/public/courses/325155/course_cover/d8120723-26f7-4fcc-a25c-a99eef4ea0f6/machine-learning-statistics-r-eng.png?w=420)
[R로 하는] 머신러닝을 위한 통계학 기초
코코
머신러닝을 공부하고 싶지만 통계학적 지식이 부족한 사람들 위한 강의 입니다.
초급
머신러닝, 통계, R
이론과 실전은 다릅니다. 머신러닝의 기본 개념을 파악하고, 꼭 알아야 할 여러 모델들의 핵심 개념과 이론을 소개합니다. 그리고, 다양한 데이터를 다루어 보면서 실전에 도움되는 여러 기법들과 노하우를 공유합니다.

머신러닝과 인공지능에 대한 기본 개념
선형 회귀 분석
알아야할 머신 러닝 모델들의 핵심 개념
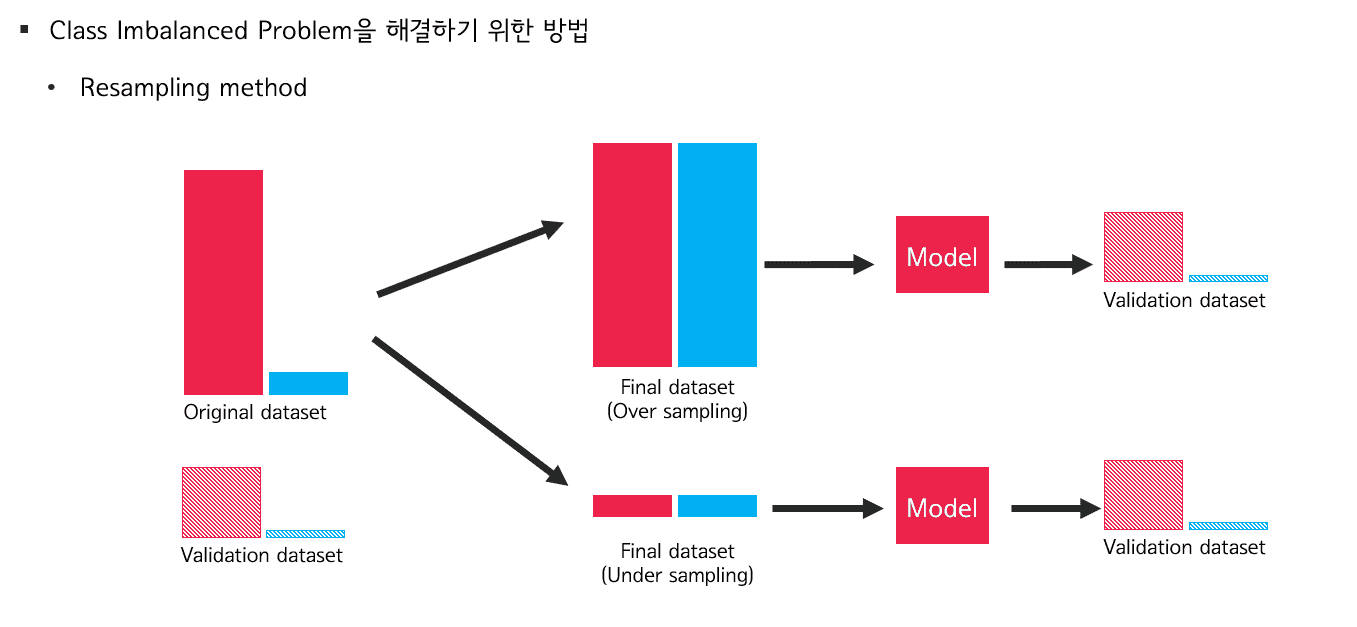
클래스 불균형 문제를 해결 하는 기법들
군집 분석에 대한 개념과 이론
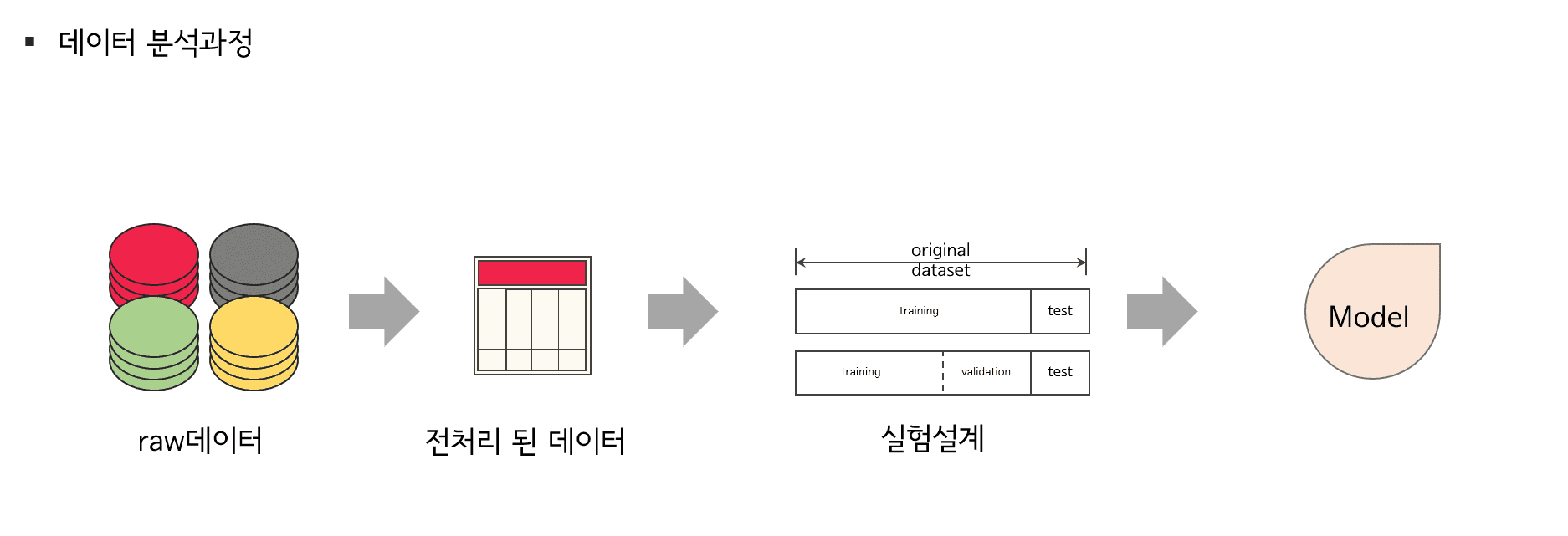
데이터를 제대로 분석하는 방법
초보 데이터 사이언티스트를 위한 첫 걸음!
머신러닝 및 인공지능에 대한 기본 핵심 개념을 학습하고 싶으신가요? 이 강의에서는 데이터 사이언티스트가 되기 위해 꼭 필요한 핵심 개념과 이론, 그리고 실전에 필요한 여러 가지 기법을 소개합니다.
 이론과 실전은 다릅니다. 이론으로 배우는 내용이 실전에서는 먹히지 않는 경우가 많습니다.
이론과 실전은 다릅니다. 이론으로 배우는 내용이 실전에서는 먹히지 않는 경우가 많습니다. 
그래서 이 강의에서는 수학적인 설명보다는 핵심 위주의 개념 설명으로 초보자 분들도 쉽게 이해할 수 있도록 하였습니다. 뿐만 아니라, 실전에서 데이터를 다룰 때 마주치는 문제점들과 그 문제점들을 해결하기 위한 여러 방법들과 노하우들도 함께 공유합니다.

머신러닝 모델들의
핵심 개념과 이론을
알고 싶으신 분

데이터 사이언티스트로
빠르게 성장하고
싶으신 분

실전에서 필요한
머신러닝 기법과 노하우를
익히고 싶으신 분
내용을 모두 학습하고 나면 최소한 데이터 사이언티스트로서 데이터를 제대로 분석할 수 있게끔 강의를 구성하였습니다. 뿐만 아니라, 데이터 도메인에 맞는 적절한 실험 설계를 하고 모델 성능을 높이기 위한 변수 선택 및 모델링까지 하실 수 있게 될 것입니다.
Q. 강의를 듣기 위해 수학적 지식이 많이 필요한가요?
학부 수준의 통계학을 필요로 하지만, 관련 지식이 없으셔도 무방합니다.
Q. R을 다룰 줄 알아야 하나요?
네, R 또는 Python을 어느 정도 할 줄 안다는 전제하에 수업을 진행합니다. 아래 <R프로그래밍 기초 다지기> 수업을 들으시길 권장드립니다.

R프로그래밍 기초 다지기
데이터 분석, R프로그래밍이 처음이라면?무료 강의

경험에서 나온
핵심 노하우
전달

생생하게
배우는
라이브 코딩

다양한
데이터로
실전 감각 Up
단순히 머신러닝 이론들을 강의하고 데이터에 적합을 시켜보는 단순한 실습에서 그치지 않습니다. 7회 참여한 빅데이터 대회(7회 본선 진출, 5회 수상)와 다양한 프로젝트를 통해 얻은 경험으로부터 데이터 분석을 잘하기 위한 노하우를 최대로 전달해드리고자 합니다.
실제로 제가 데이터 분석을 하는 과정을 보여드리기 위해 대부분은 실습은 라이브 코딩으로 진행됩니다. 코딩하는 과정 중에 모르는 게 생겼을 때 어떻게 검색을 하고 어떻게 적용을 하는 것까지 세세하게 보여드리고, 데이터를 다루면서 겪는 문제점과 이를 해결하기 위해 사용하는 방법들도 함께 공유합니다.
다양한 데이터를 다루어봅니다. 예제로 많이 사용되는 Boston House 집값 예측 데이터를 포함하여, 다중공선성이 매우 강한 시뮬레이션 데이터, 영화 리뷰 긍/부정 예측(한국어) 데이터, 서울의 빌라 전세값 예측 데이터, Kaggle의 otto 데이터 등 다양한 데이터를 다루어 실전 감각을 익히도록 합니다.
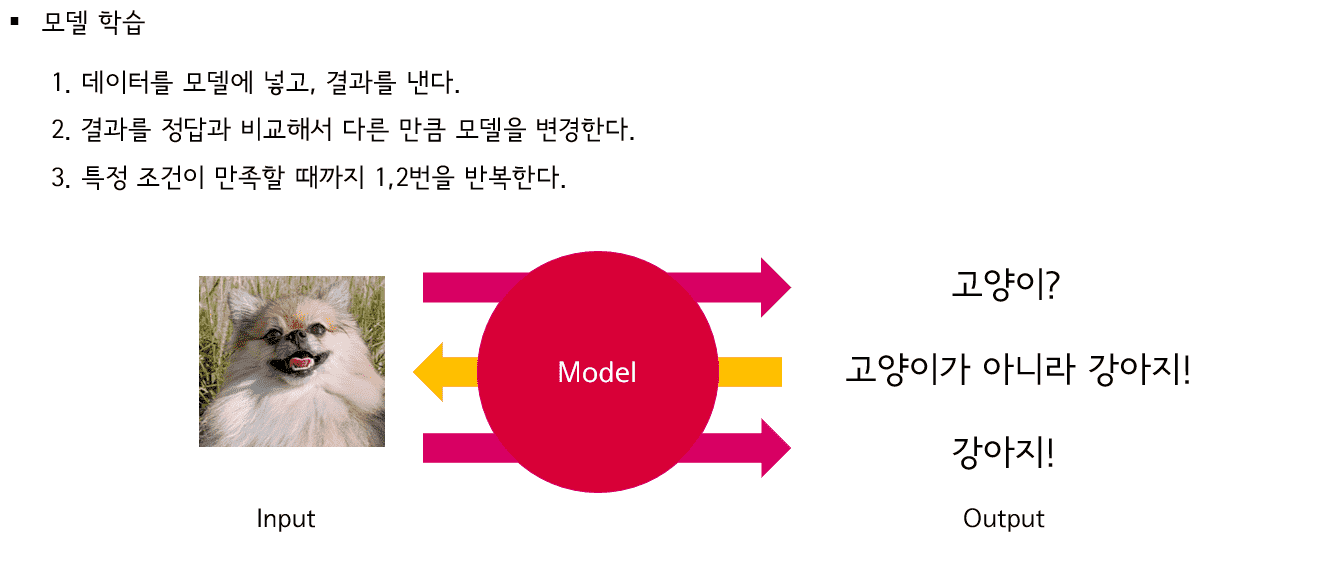
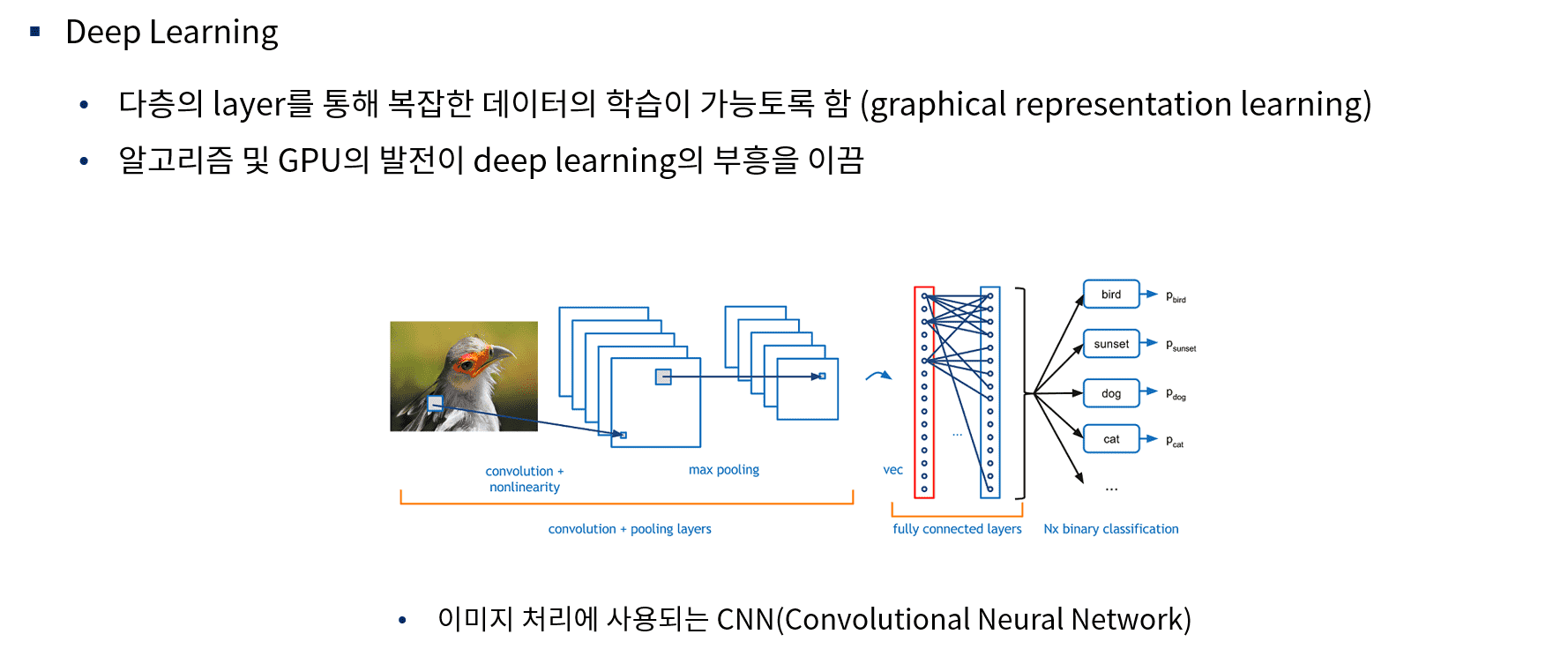
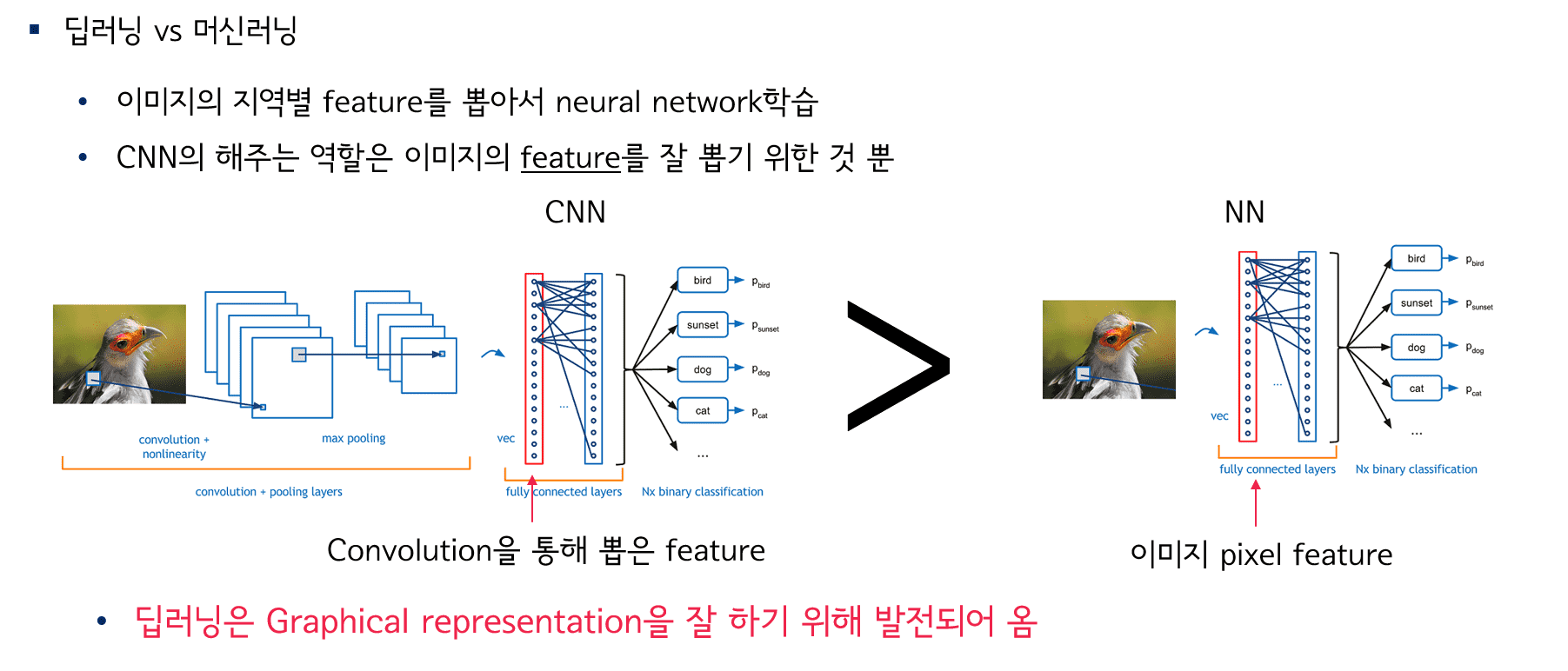
머신러닝이란 무엇이고, 머신러닝으로 무엇을 할 수 있는지에 대해 다루어 봅니다. 또한, 머신러닝과 딥러닝의 차이점이 무엇이고, 다양한 머신러닝 모델들과 딥러닝 모델들에 대해 간략하게 소개합니다. 더불어 머신러닝과 딥러닝 분야에서 공통적으로 발생하는 과적합 현상에 대해 다루어봅니다.
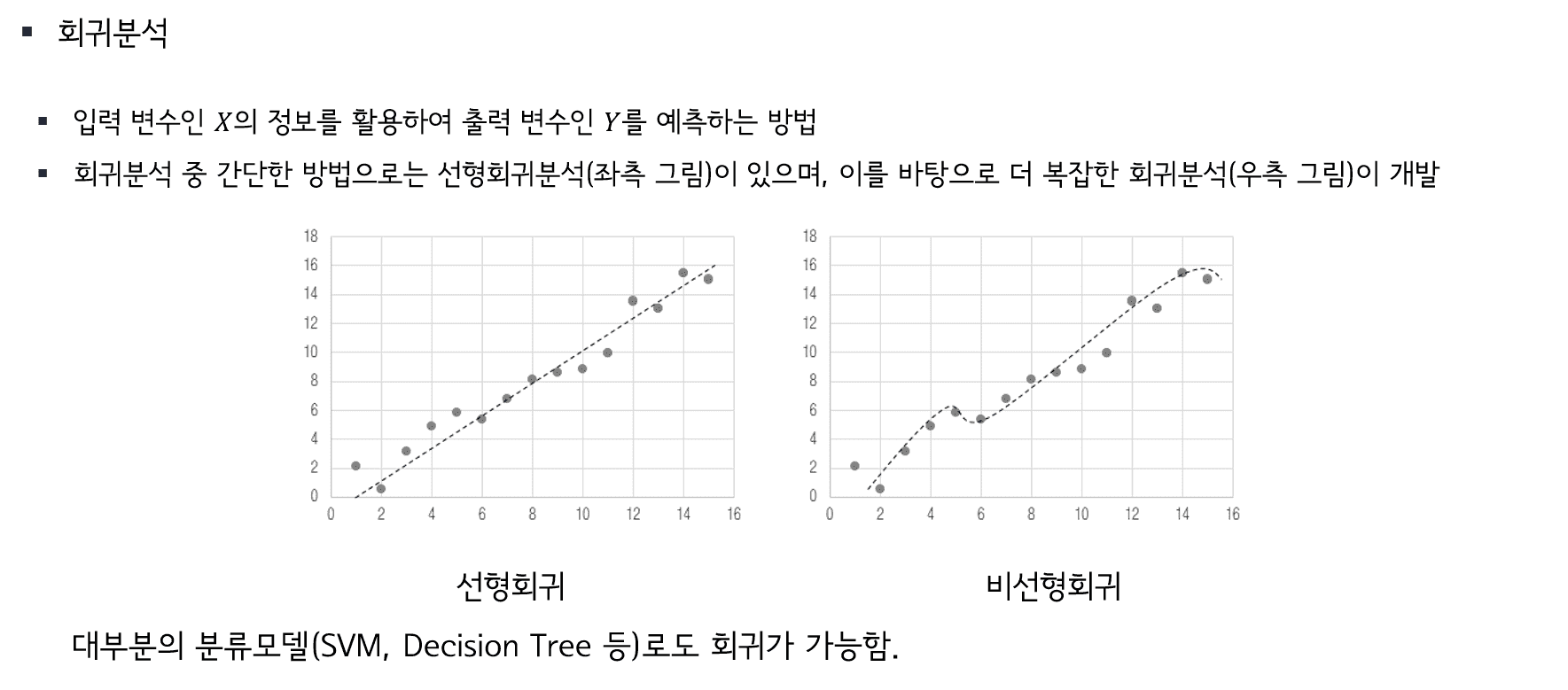
머신러닝을 배울 때 항상 처음 배우는 모델이 선형 회귀 모델입니다. 그만큼 쉽고 간단한 모델이지만, 성능이 좋지 않다는 많이 쓰이지 않는 경향이 있습니다. 하지만 선형 회귀 모델은 현업에서 많이 사용되고, 선형 회귀 문제에서는 강력한 도구입니다. 가장 기본이되는 이론과 개념을 집중적으로 다루어 봅니다.
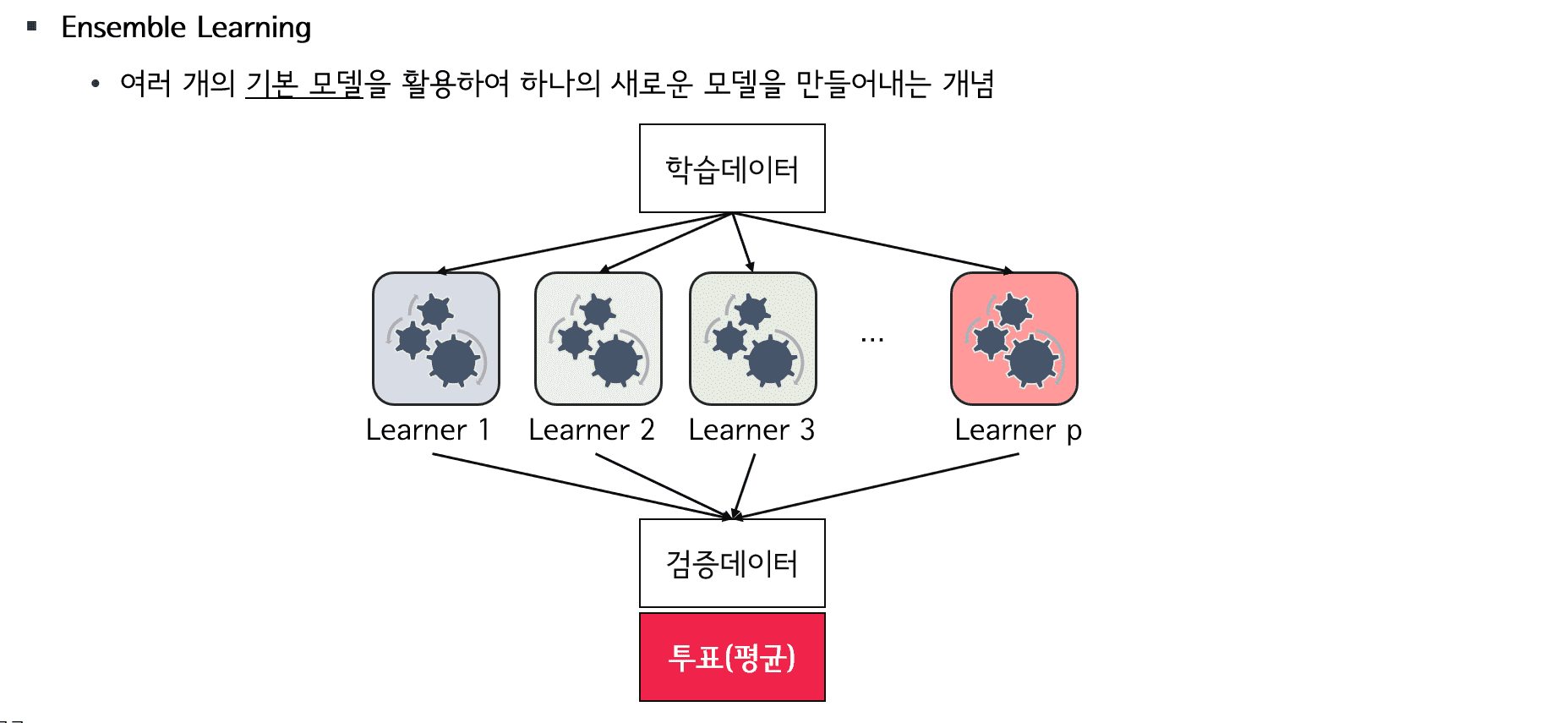
필수적으로 알아야 할 머신러닝 모델들에 대해 다루어봅니다. 수학적인 내용보다는 이해하기 쉽도록 개념 위주로 강의를 진행합니다. 많이 쓰이지는 않는 모델인 Decision Tree, kNN등과 같은 모델들은 단일 모델로서는 잘 쓰이지는 않지만 다른 분야 또는 모델에서 다양하게 활용됩니다. 그러므로 등한시 해서는 절대 안 됩니다. 다양한 모델들의 개념들과 활용법을 익히고, eXplainable AI로 각광받고 있는 ShapValue에 대해서도 소개합니다.
클래스 불균형 문제는 생각보다 다양한 분야에서 빈번하게 발생하고, 다양한 문제를 야기시킵니다. 대표적으로 다수의 클래스 편향적으로 모델이 학습하여 예측 성능이 저하된다는 점을 들 수 있습니다. 이러한 문제점을 해결하기 위한 다양한 기법(Resampling method)들에 대해 소개합니다.
데이터를 분석하는 것은 단순히 데이터를 읽고 모델을 적합하는 과정으로 끝나지 않습니다. 기본적은 데이터 전처리를 거치고 Y값을 예측하기 위해 주요 파생 변수를 생성시키고, 적절한 실험 설계를 필수적으로 진행해야 합니다. 다양한 상황에 맞는 실험 설계와 데이터 사이언티스트로서 알아야 할 필수적인 지식을 전달해 드립니다.

"머신러닝의 이론과 실전에는 상당한 차이가 존재합니다. 세상에는 다양한 도메인과 데이터가 있고, 데이터를 분석하기 위해서는 단순히 모델을 학습시키는 것에서 그쳐서는 안됩니다. 도메인에 맞는 적절한 실험 설계와 모델의 성능을 높이기 위한 파생변수 생성과 분석 목적에 따른 모델 선택이 필수적으로 뒷받침 되어야 합니다.
이 강의에서는 데이터 사이언스와 인공지능의 개념과 핵심을 최대한 쉽게 설명하고, 실전에서 쓸 수 있는 다양한 팁들과 노하우를 제공합니다. 이 강의를 통해 데이터 분석의 실전 감각을 높이도록 실력을 향상시킬 수 있기를 바랍니다."
학습 대상은
누구일까요?
머신러닝 모델들의 핵심 개념과 이론을 알고 싶으신 분
데이터 사이언티스트로서 빠르게 성장하고 싶으신 분
선수 지식,
필요할까요?
학부수준의 통계학
R프로그래밍 기초
8,208
명
수강생
489
개
수강평
136
개
답변
4.4
점
강의 평점
20
개
강의
학부에서는 통계학을 전공하고 산업공학(인공지능) 박사를 받고 여전히 공부중인 백수입니다.
수상
ㆍ 제6회 빅콘테스트 게임유저이탈 알고리즘 개발 / 엔씨소프트상(2018)
ㆍ 제5회 빅콘테스트 대출 연체자 예측 알고리즘개발 / 한국정보통신진흥협회장상(2017)
ㆍ 2016 날씨 빅데이터 콘테스트/ 기상산업 진흥원장상(2016)
ㆍ 제4회 빅콘테스트 보험사기 예측 알고리즘 개발 / 본선진출(2016)
ㆍ 제3회 빅콘테스트 야구 경기 예측 알고리즘 개발 / 미래창조과학부 장관상(2015)
* blog : https://bluediary8.tistory.com
주로 연구하는 분야는 데이터 사이언스, 강화학습, 딥러닝 입니다.
크롤링과 텍스트마이닝은 현재는 취미로 하고있습니다 :)
크롤링을 이용해서 인기있는 커뮤니티 글만 수집해서 보여주는 마롱이라는 앱을 개발하였고
전국의 맛집리스트와 블로그를 수집해서 맛집 추천 앱도 만들었었죠 :) (시원하게 말아먹..)
지금은 인공지능을 연구하는 박사과정생입니다.
전체
71개 ∙ (14시간 31분)
해당 강의에서 제공:
1. 오리엔테이션
10:28
2. 머신러닝의 개념
13:09
3. 머신러닝의 구분
06:35
4. 머신러닝의 종류
25:17
5. 딥러닝이란?
10:22
6. 딥러닝의 여러 분야
19:04
7. 모형의 적합성 평가
22:25
8. 모형의 성능 지표
15:06
9. 회귀분석이란
08:15
10. 회귀 계수의 추정
13:32
11. 회귀 계수의 의미
15:10
12. 다중 회귀 분석
09:32
13. 모델검정과 다중공선성
11:26
14. 다중공선성 진단 방법
17:36
15. 회귀 모델의 성능 지표
04:57
17. 교호작용
04:11
18. 회귀 모델의 진단
06:28
19. 다항 회귀 분석
04:15
20. 로지스틱 회귀 분석
08:53
22. 회귀 계수 축소법
08:08
지식공유자님의 다른 강의를 만나보세요!
같은 분야의 다른 강의를 만나보세요!
월 ₩17,160
5개월 할부 시
₩85,800



![[PyTorch] 쉽고 빠르게 배우는 NLP강의 썸네일](https://cdn.inflearn.com/public/courses/325056/course_cover/b66025dd-43f5-4a96-8627-202b9ba9e038/pytorch-nlp-eng.png?w=420)
![[R] KOSPI/KOSDAQ 전 종목 데이터 수집 및 관리강의 썸네일](https://cdn.inflearn.com/public/courses/324972/course_cover/36468a43-de3b-461b-af55-f3c7b0e51637/kospi-kosdaq-data-eng-1.png?w=420)
![[PyTorch] 쉽고 빠르게 배우는 GAN강의 썸네일](https://cdn.inflearn.com/public/courses/324945/course_cover/9794a376-0e54-4745-8a1d-3c6fe72b8fe6/pytorch-gan-eng.png?w=420)
![[PyTorch] 쉽고 빠르게 배우는 딥러닝강의 썸네일](https://cdn.inflearn.com/public/courses/324742/course_cover/96781b94-7bae-47f8-ab6f-42821f26f042/coco-pytorch.png?w=420)


















![[텐서플로2] 파이썬 머신러닝 완전정복 - 마라톤 기록예측 프로젝트강의 썸네일](https://cdn.inflearn.com/public/courses/324207/course_cover/1a79c7dc-1624-4d3a-95ff-79ba1e9c4025/python_machine_learning.png?w=420)





