

TensorFlow 2.0으로 배우는 딥러닝 입문
AISchool
딥러닝 핵심이론과 최신 TensorFlow 2.0을 이용한 딥러닝 코드 구현을 한번에 배울 수 있는 강의입니다.
초급
Tensorflow, 딥러닝, 머신러닝
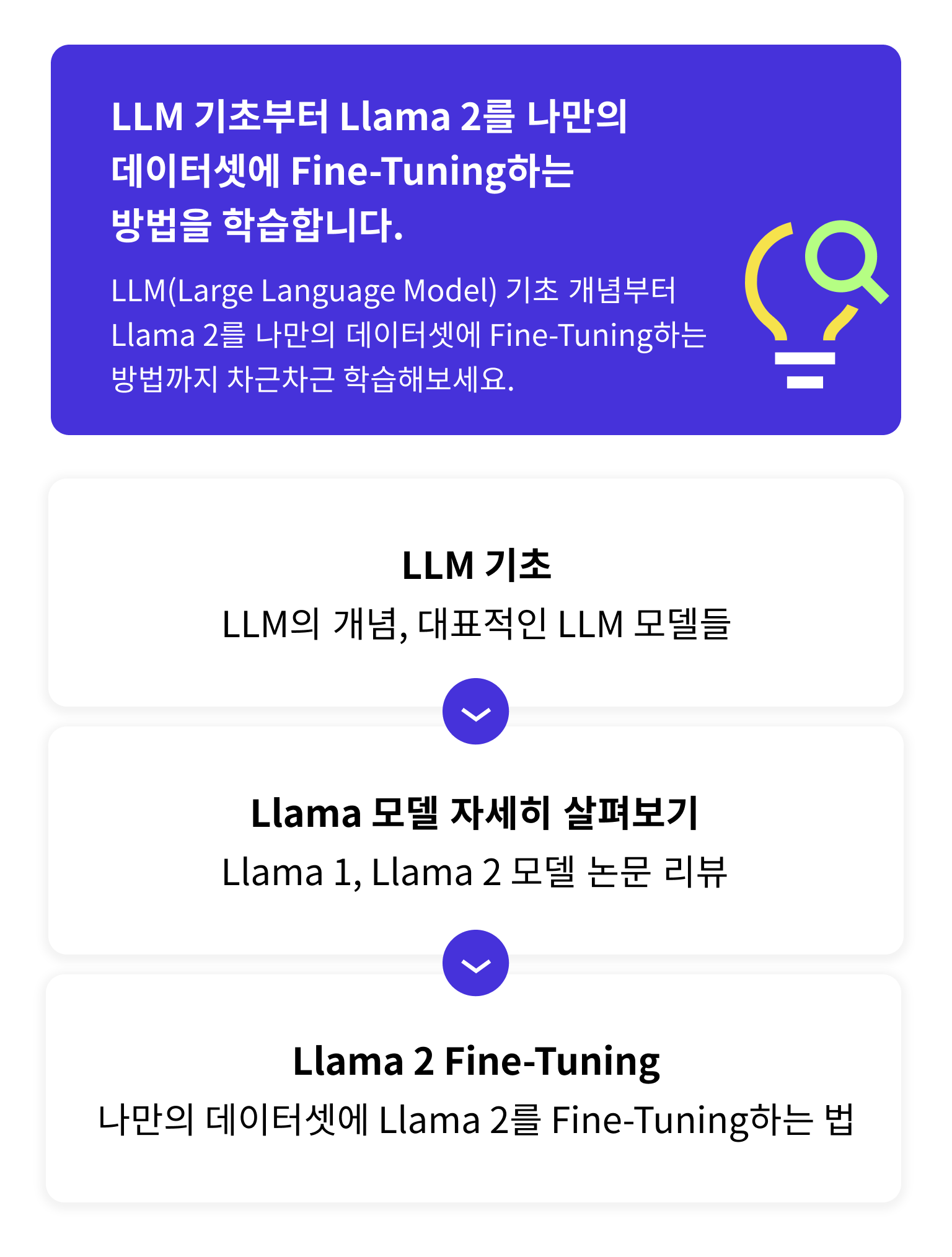
LLM(Large Language Model)의 기초 개념
고성능 LLM인 Llama 2 모델을 내가 원하는 데이터셋에 Fine-Tuning하는 방법
OpenAI API를 이용해서 GPT를 나만의 데이터셋에 Fine-Tuning하는 방법
다양한 Parameter-Efficient Fine-Tuning (PEFT) 기법들
LLM의 성능을 최대한 이끌어내기 위한 다양한 프롬프트 엔지니어링(Prompt Engineering) 기법들
최신 AI 기술 LLM, 개념부터 모델 튜닝까지!
Llama2와 OpenAI API를 제대로 활용하면, 특정 분야로 좁힌 영역에 한해 현존하는 최강의 LLM인 GPT-4보다도 강력한 LLM을 만들 수 있습니다!

최신 LLM 모델의
개념과 원리를
탄탄하게 학습하고
싶은 분

고성능 오픈소스
LLM Llama 2를
나만의 데이터셋에
Fine-Tuning하고
싶은 분

PEFT와 같은
최신 LLM 트렌드를
학습하고 싶은 분

OpenAI API를 이용한
GPT Fine-Tuning
방법을 학습하고
싶은 분
👋 본 강의는 Python, 딥러닝, 자연어처리(NLP)에 대한 선수지식이 필요한 강의입니다. 반드시 아래 강의를 먼저 수강하시거나 그에 준하는 지식을 갖춘 뒤 본 강의를 수강하세요.
Q. LLM(Large Language Model)이 무엇인가요?
LLM은 "Large Language Model"의 약자로, 대규모 데이터 세트에서 훈련된 인공지능 언어 모델을 의미합니다. 이러한 모델은 자연어 처리(NLP, Natural Language Processing) 작업에 널리 사용되며, 텍스트 생성, 분류, 번역, 질문 응답, 감정 분석 등 다양한 작업을 수행할 수 있습니다.
일반적으로 LLM은 수백만 개 이상의 매개변수(parameter)를 가지고 있으며, 이는 모델이 다양한 언어 패턴과 구조를 학습할 수 있게 해줍니다. 그 결과로, LLM은 상당히 정교하고 자연스러운 텍스트를 생성할 수 있습니다.
예를 들어 GPT (Generative Pre-trained Transformer) 시리즈와 같은 모델은 OpenAI에 의해 개발되었고, 이는 대표적인 LLM의 한 예입니다. 이러한 모델은 웹 페이지, 책, 논문, 기사 등의 큰 텍스트 데이터셋에서 훈련되며, 그 후에는 다양한 자연어 처리 작업에 적용될 수 있습니다.
LLM은 현재 많은 상업적 응용 프로그램에서 쓰이고 있으며 챗봇, 검색 엔진, 자동 번역 서비스, 컨텐츠 추천 등 다양한 분야에서 그 가치를 인정받고 있습니다. 하지만 이러한 모델은 여전히 고도의 전문성을 필요로 하는 작업에는 한계가 있을 수 있으며, 잘못된 정보 생성, 편향성, 이해 부족 등의 문제도 있을 수 있습니다.
Q. 선수 지식이 필요한가요?
본 [모두를 위한 대규모 언어 모델 LLM(Large Language Model) Part 1 - Llama 2 Fine-Tuning 해보기] 강의는 최신 LLM 모델의 상세한 설명과 사용법을 다루고 있습니다. 따라서 딥러닝과 자연어처리에 대한 기초지식을 가지고 있다는 가정하에 강의가 진행됩니다. 딥러닝과 자연어처리에 대한 기초 지식이 부족하다면 선행 강의인 [예제로 배우는 딥러닝 자연어 처리 입문 NLP with TensorFlow - RNN부터 BERT까지] 강의를 먼저 수강하시길 바랍니다.
📢 수강 전 확인해주세요
학습 대상은
누구일까요?
대규모 언어 모델 LLM(Large Language Model)의 개념과 활용법을 학습하고 싶은 분
나만의 데이터셋에 최신 LLM을 Fine-Tuning 해보고 싶은 분
딥러닝 연구 관련 직종으로 취업을 원하시는 분
인공지능/딥러닝 관련 연구를 진행하고 싶은 분
인공지능(AI) 대학원을 준비 중이신 분
선수 지식,
필요할까요?
Python 사용 경험
선수강의 [예제로 배우는 딥러닝 자연어 처리 입문 NLP with TensorFlow - RNN부터 BERT까지] 수강경험
8,292
명
수강생
577
개
수강평
345
개
답변
4.6
점
강의 평점
28
개
강의
전체
112개 ∙ (26시간 5분)
해당 강의에서 제공:
전체
74개
4.7
74개의 수강평

















![[PyTorch] 쉽고 빠르게 배우는 NLP강의 썸네일](https://cdn.inflearn.com/public/courses/325056/course_cover/b66025dd-43f5-4a96-8627-202b9ba9e038/pytorch-nlp-eng.png?w=420)





