![[R로 하는] 머신러닝을 위한 통계학 기초강의 썸네일](https://cdn.inflearn.com/public/courses/325155/course_cover/d8120723-26f7-4fcc-a25c-a99eef4ea0f6/machine-learning-statistics-r-eng.png?w=420)
[R로 하는] 머신러닝을 위한 통계학 기초
코코
머신러닝을 공부하고 싶지만 통계학적 지식이 부족한 사람들 위한 강의 입니다.
초급
머신러닝, 통계, R
Q-learning부터 Deep Q-learning에 대해 배우고, 강화학습을 R로 구현해 보는 시간을 가집니다. Deep Q-network을 넘어서 Self-imitation learning과 Random Netowrk Distillation 까지 전체적인 강화학습 내용을 다룹니다.

강화학습이론
Q-learning부터 Deep Reinforcement Learning까지
Exploration을 위한 여러 강화학습 기법들
🙆🏻♀ Q-learning과 Deep Q-learning을 넘어서 RND까지🙆🏻♂
알파고로 시작된 강화학습의 붐, 강화학습은 알파고가 나오기 오래전부터 존재했던 알고리즘이라는 사실 알고 계셨나요?

강화학습은 일반적으로 공부를 하기에 진입장벽이 높은 분야로 알려져 있습니다. 알파고가 나오면서부터 많은 사람들이 관심을 가지기 시작했지만, 내용이 쉽지 않아 공부하기가 어렵습니다. 강화학습을 공부하고 싶었지만 어려워서 시작도 못하신 분을 위해 중요한 부분만 골라 요약해서 알려드립니다. Q-learning부터 DQN 그리고 DQN을 넘어서 강화학습의 주된 문제인 sparse reward problem과 이를 해결 하기 위한 여러 아이디어들을 소개합니다. 짧은 시간안에 강화학습을 전체적으로 공부할 수 있는 좋은 강의가 될 것 입니다.
강화학습이 대체 무엇인지, 강화학습엔 어떠한 요소가 있고 어떻게 학습이 진행이 되는지 예를들어 차근차근 설명합니다.
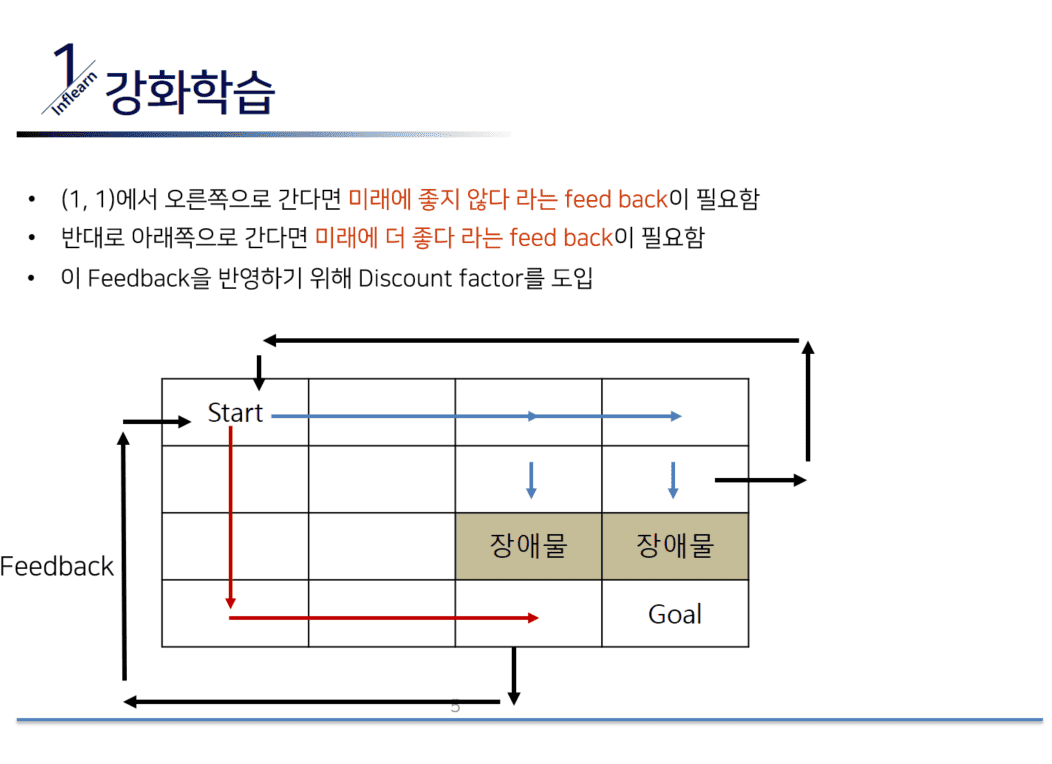
말로만 설명해서는 이해가 잘 되지 않아요. 손으로 직접 Q-learing을 풀어보면서 강화학습에 대한 개념을 제대로 이해해 봅시다.

Deep reinforcement learning의 기본이는 Deep Q-network (DQN)부터 PerDQN을 포함한 여러 DQN변형들, actorcritic, Self-Imitation learing 까지 중요한 내용을 핵심적으로 요약합니다.
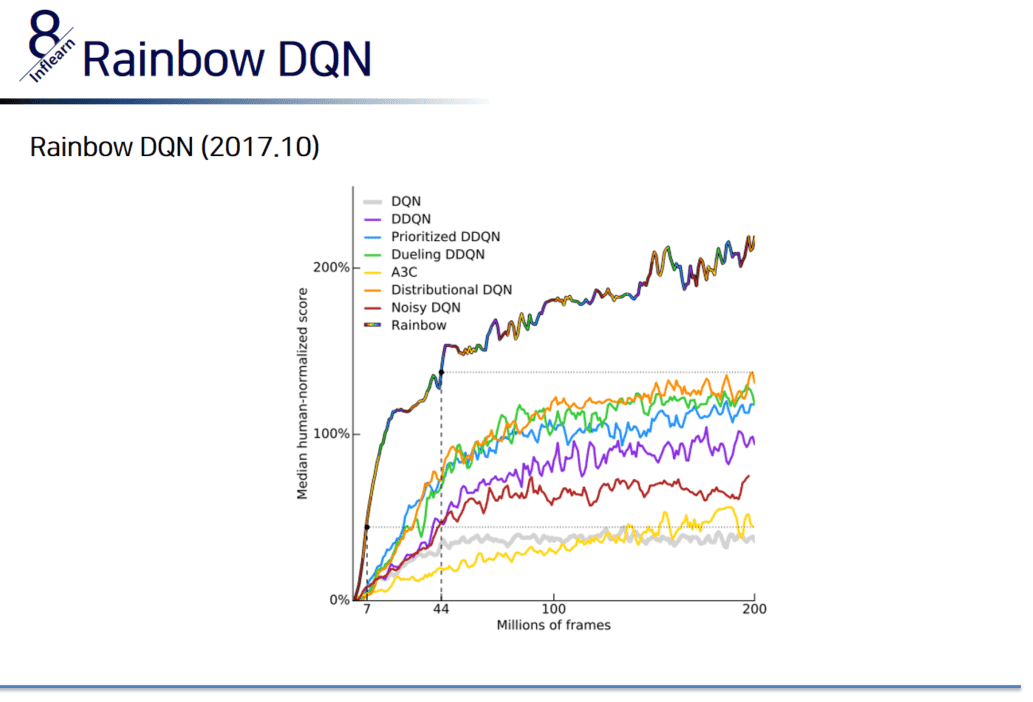
강화 학습의 주된 문제인 sparse reward problem에 대해서 이야기 하고 이를 해결하기 위한 여러 기법들에 대해 이야기합니다.
우리는 주로 'curiosity' 또는 'prediction error'에 대해서 이야기 하고 이들을 활용한 여러 알고리즘에 대해 소개합니다.
(SIL, Random Network Distillation 등)

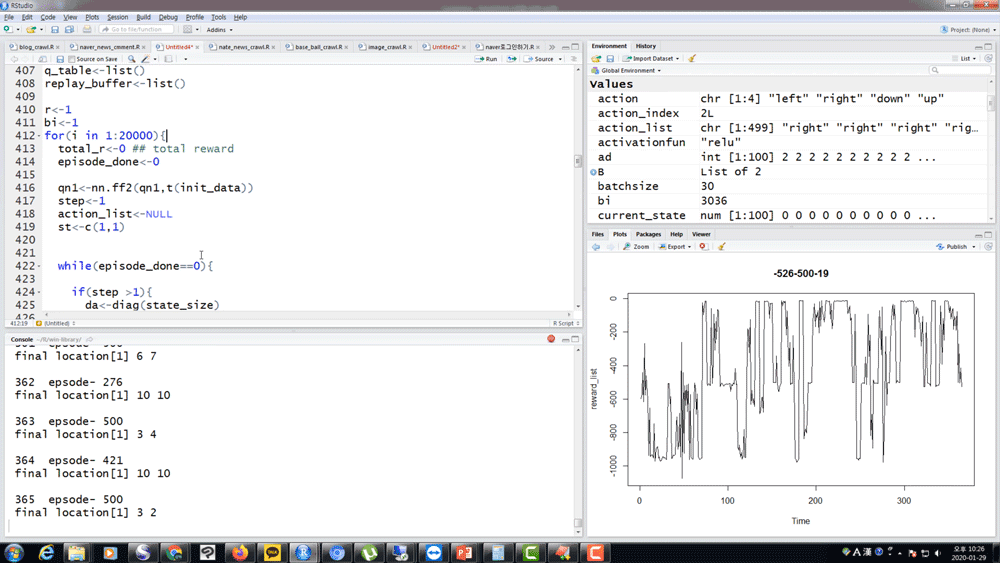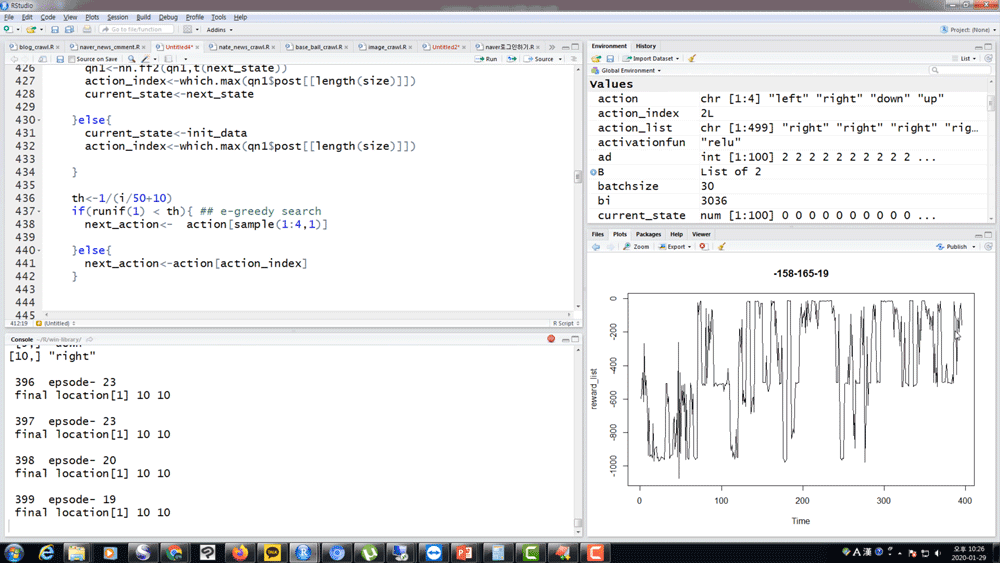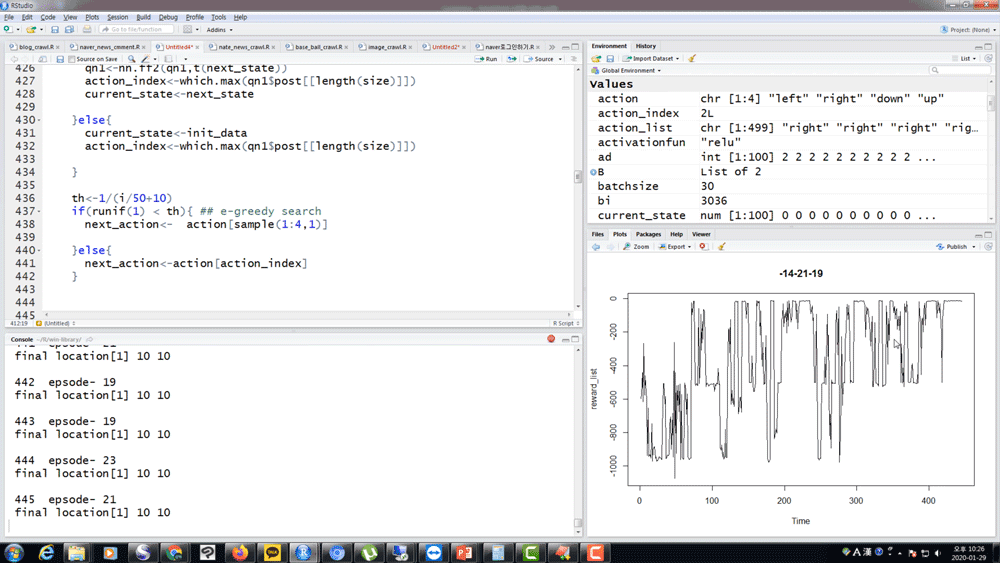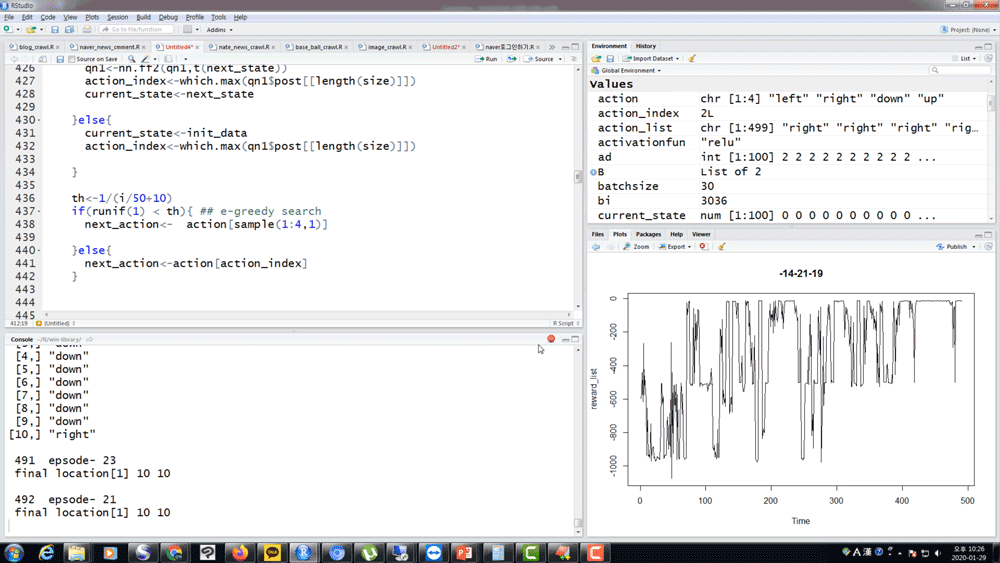
직접 코드로 구현해보지 않으면 절반만 알고 있는 거겠죠 ? 가장 중요한 모델들에 대해 R로 직접 강화학습 알고리즘을 짜보고 결과를 같이 확인해 봅니다.
그리고 Exploration 을 위한 RND가 정말 효과가 있는지도 함께 확인해 보시죠.
Q. 선수 지식이 있나요?
A. 머신러닝, NN에 대한 기본적인 개념이 있으신게 좋습니다.
Q. Python으로 실습을 하지는 않나요?
A. 현재는 R로 실습 코드를 구현해서 강의를 업로드 했고, 추후에 python으로 실습하는 코드를 업로드 할 예정입니다.(타 강의로 여는게 아니라 본 강의에 추가적으로 업로드할 예정입니다)
학습 대상은
누구일까요?
강화학습 쉽게 배우고 싶으신분
짧은 시간안에 전체적인 강화학습을 배우고 싶으신분
선수 지식,
필요할까요?
R프로그래밍 중급 실력
Neural network에 대한 기본적인 이해
머신러닝에 대한 기본적인 지식
8,208
명
수강생
489
개
수강평
136
개
답변
4.4
점
강의 평점
20
개
강의
학부에서는 통계학을 전공하고 산업공학(인공지능) 박사를 받고 여전히 공부중인 백수입니다.
수상
ㆍ 제6회 빅콘테스트 게임유저이탈 알고리즘 개발 / 엔씨소프트상(2018)
ㆍ 제5회 빅콘테스트 대출 연체자 예측 알고리즘개발 / 한국정보통신진흥협회장상(2017)
ㆍ 2016 날씨 빅데이터 콘테스트/ 기상산업 진흥원장상(2016)
ㆍ 제4회 빅콘테스트 보험사기 예측 알고리즘 개발 / 본선진출(2016)
ㆍ 제3회 빅콘테스트 야구 경기 예측 알고리즘 개발 / 미래창조과학부 장관상(2015)
* blog : https://bluediary8.tistory.com
주로 연구하는 분야는 데이터 사이언스, 강화학습, 딥러닝 입니다.
크롤링과 텍스트마이닝은 현재는 취미로 하고있습니다 :)
크롤링을 이용해서 인기있는 커뮤니티 글만 수집해서 보여주는 마롱이라는 앱을 개발하였고
전국의 맛집리스트와 블로그를 수집해서 맛집 추천 앱도 만들었었죠 :) (시원하게 말아먹..)
지금은 인공지능을 연구하는 박사과정생입니다.
전체
20개 ∙ (4시간 31분)
해당 강의에서 제공:
전체
3개
₩55,000




![[PyTorch] 쉽고 빠르게 배우는 NLP강의 썸네일](https://cdn.inflearn.com/public/courses/325056/course_cover/b66025dd-43f5-4a96-8627-202b9ba9e038/pytorch-nlp-eng.png?w=420)
![[R] KOSPI/KOSDAQ 전 종목 데이터 수집 및 관리강의 썸네일](https://cdn.inflearn.com/public/courses/324972/course_cover/36468a43-de3b-461b-af55-f3c7b0e51637/kospi-kosdaq-data-eng-1.png?w=420)
![[PyTorch] 쉽고 빠르게 배우는 GAN강의 썸네일](https://cdn.inflearn.com/public/courses/324945/course_cover/9794a376-0e54-4745-8a1d-3c6fe72b8fe6/pytorch-gan-eng.png?w=420)
![[PyTorch] 쉽고 빠르게 배우는 딥러닝강의 썸네일](https://cdn.inflearn.com/public/courses/324742/course_cover/96781b94-7bae-47f8-ab6f-42821f26f042/coco-pytorch.png?w=420)


















![[텐서플로2] 파이썬 머신러닝 완전정복 - 마라톤 기록예측 프로젝트강의 썸네일](https://cdn.inflearn.com/public/courses/324207/course_cover/1a79c7dc-1624-4d3a-95ff-79ba1e9c4025/python_machine_learning.png?w=420)





