
중급자를 위해 준비한
[데이터 엔지니어링, 데브옵스 · 인프라] 강의입니다.
이런 걸
배워요!
카프카 커넥트 주요 구성요소들의 핵심 메커니즘
CDC(Change Data Capture)의 이해와 실무 적용 기법
MySQL 데이터 복제와 CDC(Change Data Capture) 이해 및 실무 적용 방안
Debezium CDC Source 커넥터의 핵심 메커니즘과 특징
Debezium CDC 소스 커넥터를 이용한 RDBMS간 데이터 연동
Debizium 커넥트 기반의 연동 시스템 구축 노하우
JDBC 기반의 Source 커넥터와 Sink Connector 환경 설정 및 구동
메시지 변환을 위한 다양한 SMT 클래스들의 적용
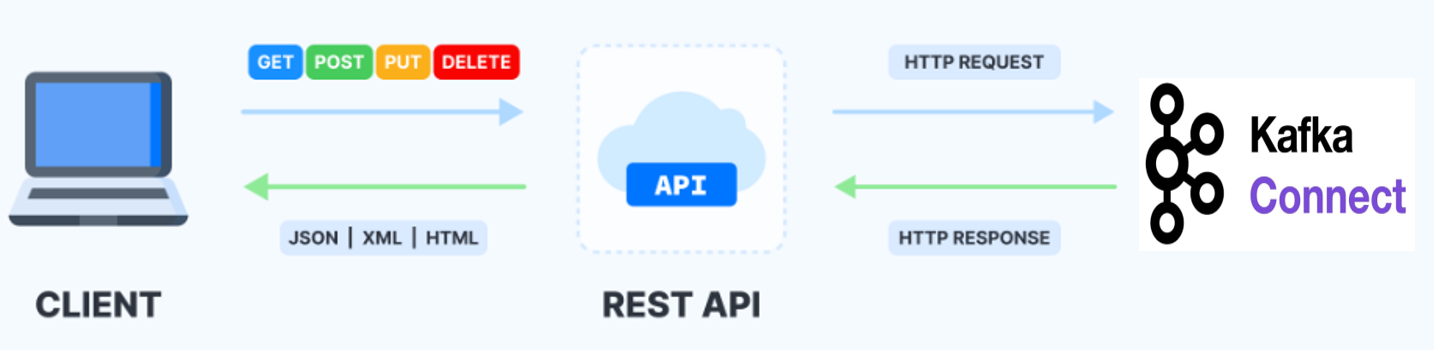
REST API를 이용한 커넥트 관리
스키마 레지스트리(Schema Registry)의 활용과 커넥트와의 통합
REST API를 이용한 스키마 레지스트리 관리
아파치 카프카 실무를 위한 커넥트,
원리부터 실무 응용까지 확실하게!
강력한 실시간 데이터 연동을 위한
카프카 커넥트(Kafka Connect).
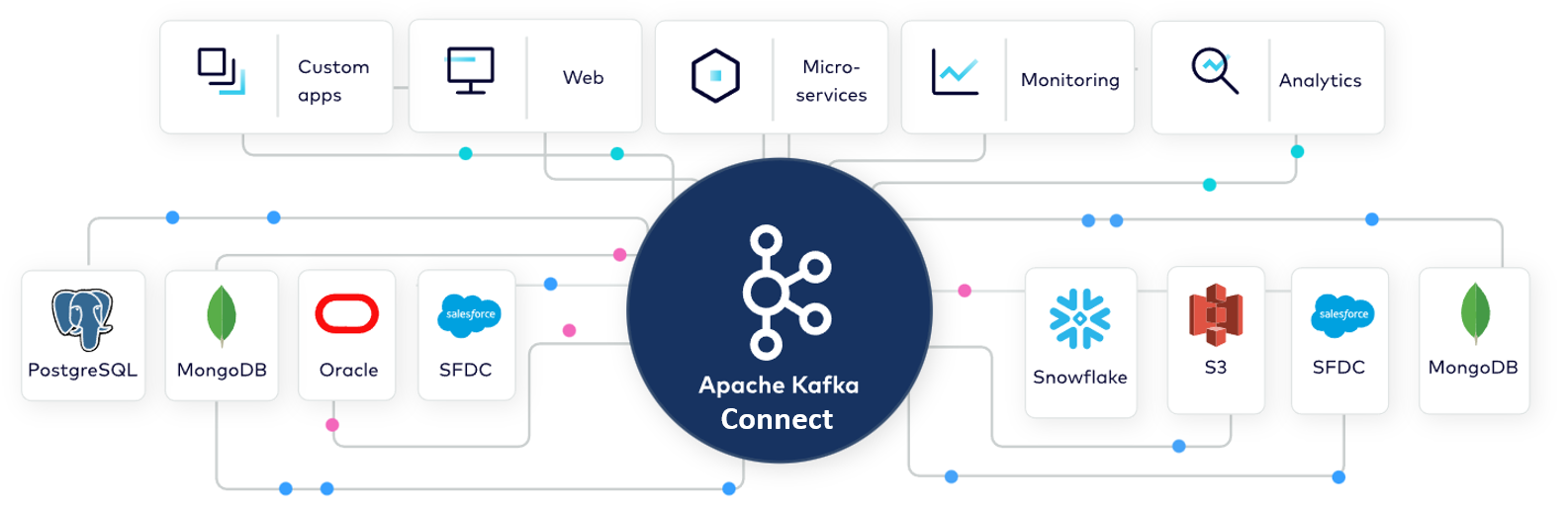
다양한 데이터 시스템 간의 실시간 연동을 위한 최고의 오픈소스 솔루션!
카프카 커넥트는 별도의 코딩 구현 없이 이미 만들어진 커넥터(Connector)들을 통해 다양한 시스템간의 실시간 데이터 연동을 쉽고 빠르며 안정적으로 구축할 수 있게 만들어 줍니다.
해외에서는 이미 많은 기업들이 카프카 커넥트를 도입하였고, 국내에서도 카프카 커넥트를 이기종 데이터 시스템 간의 통합 및 전사 데이터 파이프라인 구축에 활용하면서 카프카 및 카프카 커넥트에 대한 실무 역량을 갖춘 인재에 대한 수요가 늘고 있습니다. 하지만 아쉽게도 카프카 커넥트에 대한 학습 자료는 여전히 부족한 상황입니다. 기본적이고 피상적인 수준의 정보만 제공하는 책/자료/강의만 찾아볼 수 있기 때문에, 실무에서 원하는 정도의 실전 역량을 갖춘 인력을 양성하기 어렵습니다.
실무에서 원하는 카프카 커넥트 전문가로 성장할 수 있게 이끌어 드립니다.
상세한
메커니즘 설명
실무 수준의
다양한 예제
이슈 해결
방안까지 OK
본 강의는 지금껏 어떤 강의나 책에서도 접할 수 없었던, 상세하고 실전적인 수준으로 카프카 커넥트를 다루고 있습니다. 카프카 커넥트 핵심 구성 요소들의 상세한 메커니즘 설명, 그리고 커넥트를 활용한 다양한 데이터 연동과 운영 관리를 다뤄볼 수 있는 많은 실습 예제들을 통해 여러분을 현장에서 필요로 하는 카프카 커넥트 전문가로 성장시켜 드릴 것입니다.
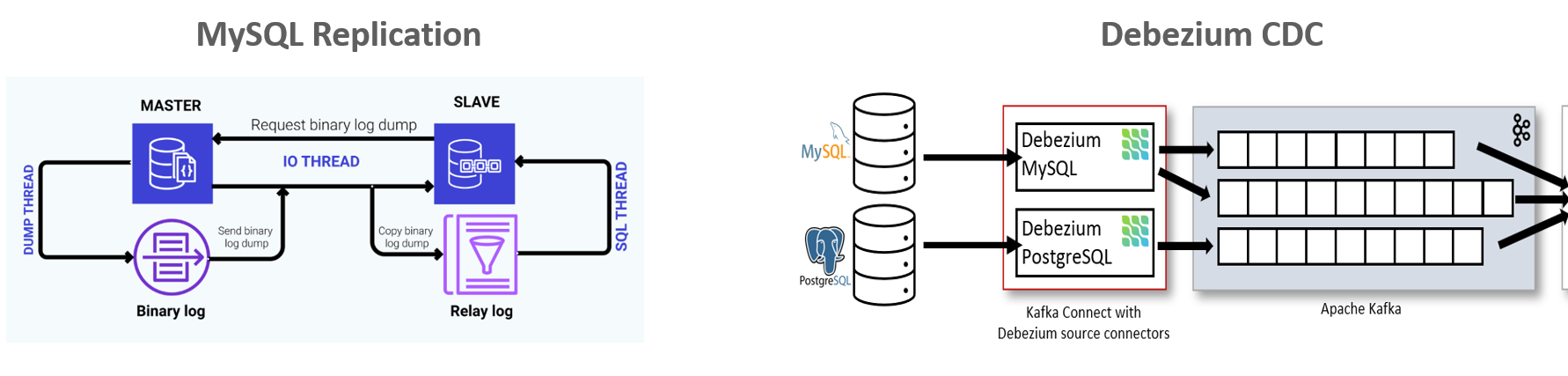
무엇보다, CDC 기반의 카프카 커넥트 데이터 연동을 확실하게 익히실 수 있습니다.

대부분 기업의 중요 데이터 시스템은 RDBMS입니다. 물리적으로 서로 떨어져 있는 데이터베이스의 실시간 연동은 CDC(Change Data Capture)가 대세입니다. CDC는 대용량의 데이터를 지연없이 실시간으로 연동하면서도 시스템의 부하는 최소화할 수 있는 훌륭한 데이터 연동 기법입니다. Debezium Connector는 카프카 커넥트를 이용하여 서로 다른 RDBMS간 데이터를 연동할 수 있게 해주는 가장 대표적인 CDC 솔루션입니다.
많은 기업에서 CDC 기반의 커넥트를 다룰 수 있는 인력을 요구하고 있습니다. 이에 본 강의에서는 CDC와 Debezium Connector의 메커니즘과 환경 설정 및 적용 방안, 그리고 Debezium을 현업에 적용할 때 발생할 수 있는 여러 이슈 사항 및 그에 따른 해결 방안들을 상세한 이론 설명과 실습을 통해 자세히 설명합니다.
이 강의만의 특징을
확인해보세요.
상세한 설명과 실습을 통한 카프카 커넥트 주요 구성 요소들의 이해
커넥트 클러스터, Connector, SMT(Single Message Transform), Converter 등에 대한 핵심 기반 지식을 상세한 설명과 실습을 통해 자유자재로 활용할 수 있는 수준으로 체득시켜 드립니다.
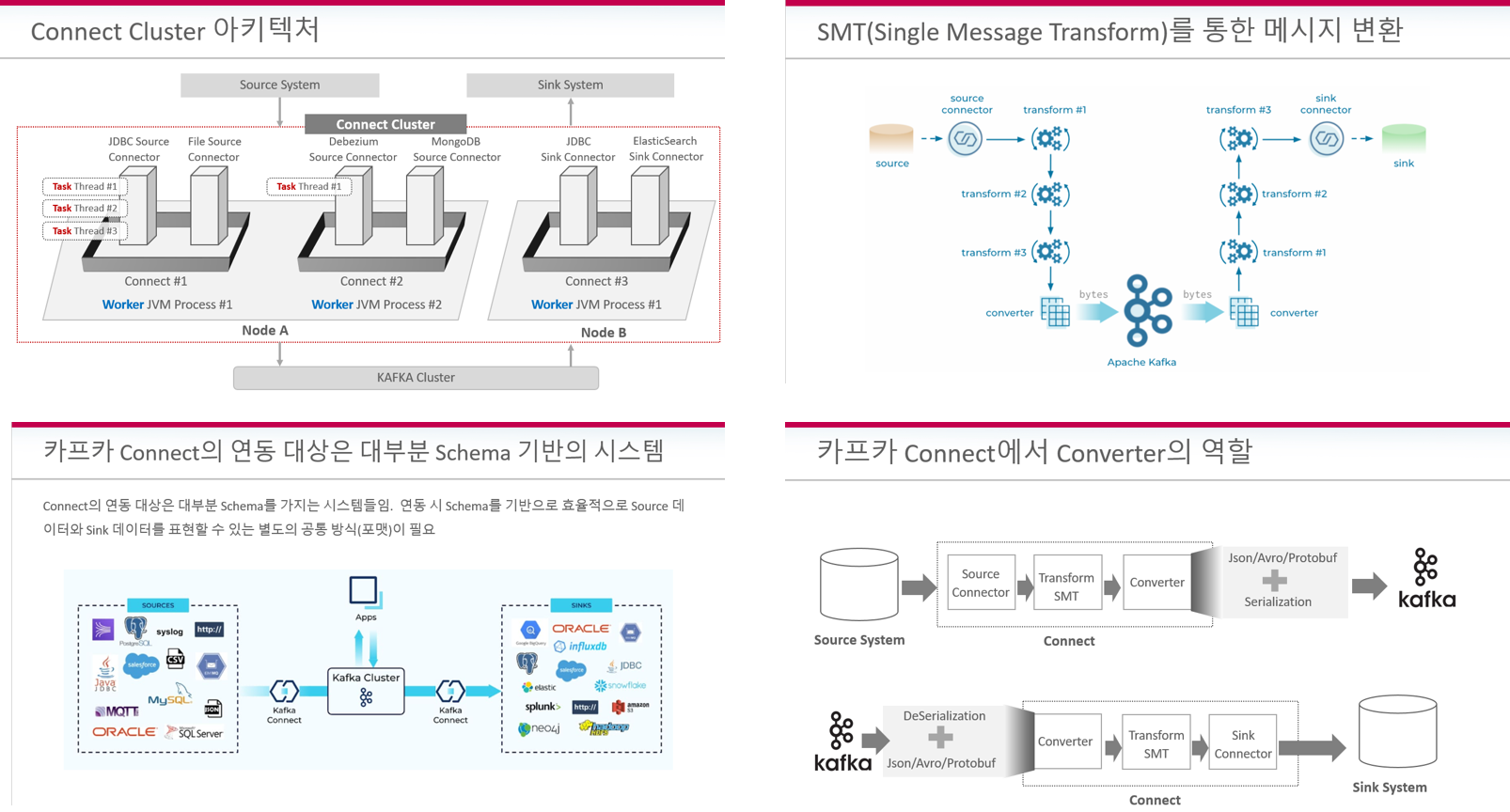
다양한 Connector들에 대한 환경 구성 및 구동 실습
SpoolDir Source, JDBC Source/Sink, Debezium Source Connector 등 RDBMS 운영 환경에 적용될 수 있는 다양한 Connector들의 환경 설정 파라미터와 내부 메커니즘, 그리고 다양한 적용 실습을 통해 카프카 기반의 실전 데이터 연동 시스템을 구축할 수 있도록 도와드립니다.

Debizium CDC 소스 Connector에 대한 상세한 메커니즘 설명, 다양한 실습 & 발생할 수 있는 이슈 사항 및 해결 방안까지!
Debezium CDC 소스 커넥터에 대해서 많은 내용을 담았습니다. RDBMS 운영 환경에서 Debezium CDC와 JDBC Sink Connector를 통해서 서로 떨어져 있는 RDBMS간 실시간 연동을 운영에 어떻게 구축해야 할지 자세한 가이드를 드립니다.
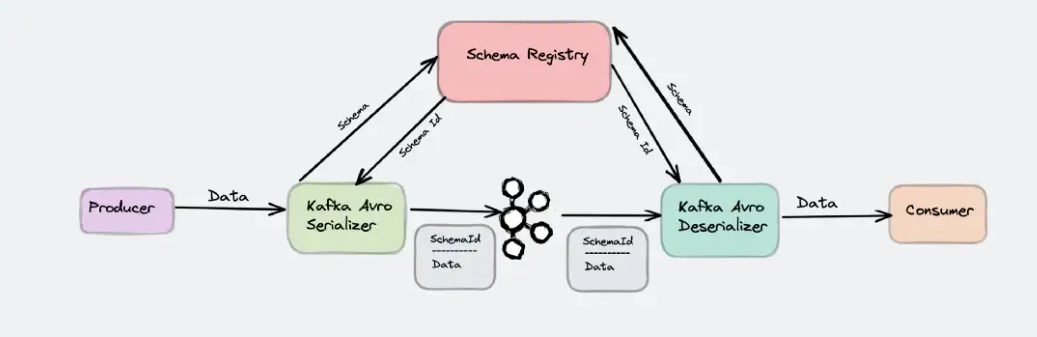
Avro 및 스키마 레지스트리(Schema Registry) 이해와 활용
커넥트 뿐만 아니라 Avro 및 스키마 레지스트리를 통한 스키마 데이터의 전송 및 중앙 관리, 특히 실무에서 중요하게 다뤄져야 하는 스키마 호환성에 대해서 상세하게 설명드립니다. 이를 통해 커넥트와 스키마 레지스트리를 연동하여 실무에서 필요로 하는 효율적인 전사 데이터 통합 및 데이터 파이프라인 구축 방안을 익히실 수 있습니다.
REST API를 통한 Connect와 Schema Registry의 관리 방안
Connect와 Schema Registry 주요 요소들을 다양한 REST API들을 통해서 생성/수정/삭제/관리할 수 있는 방법들을 배우게 됩니다.
Kafka Connect 마스터를 위한 Bonus!
약 200페이지 분량의 강의 교재를 수강생 여러분께 제공합니다. 카프카 커넥트를 익히는 데 도움이 되시길 바랍니다.

실습 환경 💾
서버 OS

카프카 서버 OS로 오라클(Oracle) VirtualBox VM 기반에서 Ubuntu Linux(우분투 리눅스) 20.04를 이용합니다. 리눅스를 이용하지만 가상 머신 기반으로 구동되므로 Windows/macOS 환경 모두에서 구성할 수 있습니다.
VirtualBox는 Windows/macOS 환경에서 거의 대부분 설치 가능합니다. 다만 Mac의 경우 최신 M1 모델에서 VirtualBox가 설치되지 않으므로 UTM등의 가상환경을 이용하여 Ubuntu를 설치하셔야 합니다. M1 모델의 경우 반드시 가상환경에서 Ubuntu가 설치되는지 확인 후 강의를 선택해 주시기 바랍니다.
컨플루언트 카프카
커뮤니티 에디션
![]()
카프카는 아파치 카프카(Apache Kafka)가 아닌 컨플루언트 카프카(Confluent Kafka) Community Edition 버전 7.1.2를 사용합니다.
컨플루언트는 카프카를 만든 핵심 인력이 주축이 되어 세운 회사로, 기업 고객을 위해 성능 및 편의성 측면에서 보다 향상된 기업용 카프카를 제공하고 있습니다. 아파치 카프카와 100% 호환되면서도 보다 다양한 카프카 모듈 및 일체화된 Binary를 이용할 수 있습니다. 컨플루언트로 강력한 분산형 시스템 카프카를 더욱 탄력적으로 확장 가능한 형태로 사용해 보세요. 인프라 구축 및 유지 관리 부담을 줄이고, 더 빠른 개발을 할 수 있도록 도움을 줄 것입니다.
RDBMS

Spooldir Source Connector와 같이 파일 데이터의 연동도 실습으로 제공하지만 대부분의 커넥트 실습 연동은 RDBMS간 데이터 연동을 주축으로 합니다.
특히 Source와 Sink가 모두 MySQL DB로 동일한 실습이 많으며 Source는 MySQL, Sink는 PostgreSQL 실습도 함께 수행합니다. 실습에 사용된 버전은 MySQL 8.0.31, PostgreSQL 12입니다.
권장 PC 사양
![]()
전체 실습 환경 구성으로 20~30GB의 스토리지 용량, 4GB 이상의 RAM을 갖춘 PC 환경이 요구될 수 있습니다.
Q&A를 확인해보세요 💬
Q. 왜 카프카 커넥트를 배워야 하나요?
카프카 커넥트는 카프카 기반의 데이터 연동을 위한 핵심 컴포넌트입니다. 이미 카프카를 도입한 많은 기업들이 카프카 커넥트를 효율적으로 활용하여 대규모 데이터 파이프라인을 손쉽게 구축하고 있습니다.
카프카 커넥트는 120여개의 다양한 Connector를 통해 Oracle, MySQL, PostgreSQL등의 대표적인 RDBMS뿐만 아니라 MongoDB, ElasticSearch와 같은 NoSQL, RedShift, SnowFlake, Vertica, Teradata등의 DW 시스템 등 서로 다른 이기종 데이터 시스템을 상호 연결하는 데 쓰이고 있습니다.
별도의 코딩 구현 없이도 카프카 커넥트를 통해 쉽게 이기종 데이터 시스템을 상호 연동/통합할 수 있으며, 특히 Community license를 통한 연동 S/W 비용의 절감과 CDC 기반으로 대용량 데이터의 지연 시간 없는 실시간 연동 등의 장점으로 여러 기업에서 그 쓰임새와 활용도가 커지고 있습니다.
본 강의를 통해 카프카 커넥트를 잘 익히시게 된다면 기업이 원하는 카프카 전문 인력으로 한층 더 발돋음 하실 수 있습니다.
Q. 이전 강의인 카프카 완벽 가이드 - 코어편을 들어야 하나요?
이전 강의인 카프카 완벽 가이드 - 코어편을 수강하시면 더 좋지만, 수강을 하지 않으셨더라도 카프카의 기본인 Broker, Producer, Consumer에 대한 개념이 잘 정립되어 있고, 카프카의 메시지 전송 및 읽기를 적용해 보신 경험이 있으신 분이라면 충분히 본 강의를 들으실 수 있습니다.
Q. 강의 수강을 위해 RDBMS 경험이 있어야 하나요?
아쉽지만, 본 강의는 3개월 이상의 RDBMS 경험을 필요로 합니다.
기본적으로 RDBMS 테이블과 컬럼 변경 생성 정도만 이해하셔도 대부분의 강의 실습이 가능하지만, CDC나 RDBMS 복제등은 강의에서 해당 내용을 자세히 설명을 드림에도 불구하고 RDBMS에 대한 어느 정도의 경험이 없으시다면 실습이 어렵게 느껴지실 수 있습니다.
이런 분들께
추천드려요!
학습 대상은
누구일까요?
카프카 커넥트의 내부 메커니즘을 확실히 이해하고 실무에 적용하기를 원하시는 모든 분
전사 데이터 파이프라인 구축과 CDC 기반의 데이터 아키텍처 이해를 원하는 데이터 엔지니어 또는 아키텍처
JDBC또는 Debezium CDC Connector의 운영이 필요한 DBA또는 시스템 운영자
운영 DB의 실시간 동기화를 통한 ETL및 DB 연동을 고민하는 DW개발자
마이크로 서비스 기반의 아키텍처 구성 시 CDC기반의 데이터 연동 방식을 고민하는 개발자 및 아키텍트
선수 지식,
필요할까요?
카프카 Broker, Producer, Consumer에 대한 기반 지식
3개월 이상의 RDBMS 개발 또는 운영 경험
안녕하세요
권 철민입니다.
(전) 엔코아 컨설팅
(전) 한국 오라클
AI 프리랜서 컨설턴트
파이썬 머신러닝 완벽 가이드 저자
커리큘럼
전체
147개 ∙ 24시간 35분
수업 자료
가 제공되는 강의입니다.
강의소개
07:11
강의 실습 코드와 교재 소개
02:22
실습 환경 구축 개요
02:40
오라클 VirtualBox 설치하기
05:43
카프카(Kafka) 설치
08:23
카프카 기동하기
11:10
카프카 서버 환경 설정
12:35
커넥트 기동하기
13:44
Converter의 이해
08:32
kafkacat 소개
03:34
kafkacat 사용법 실습
19:46
마지막 업데이트일: 2023년 04월 28일