인프런 커뮤니티 질문&답변
작성한 질문수

답변 3
0
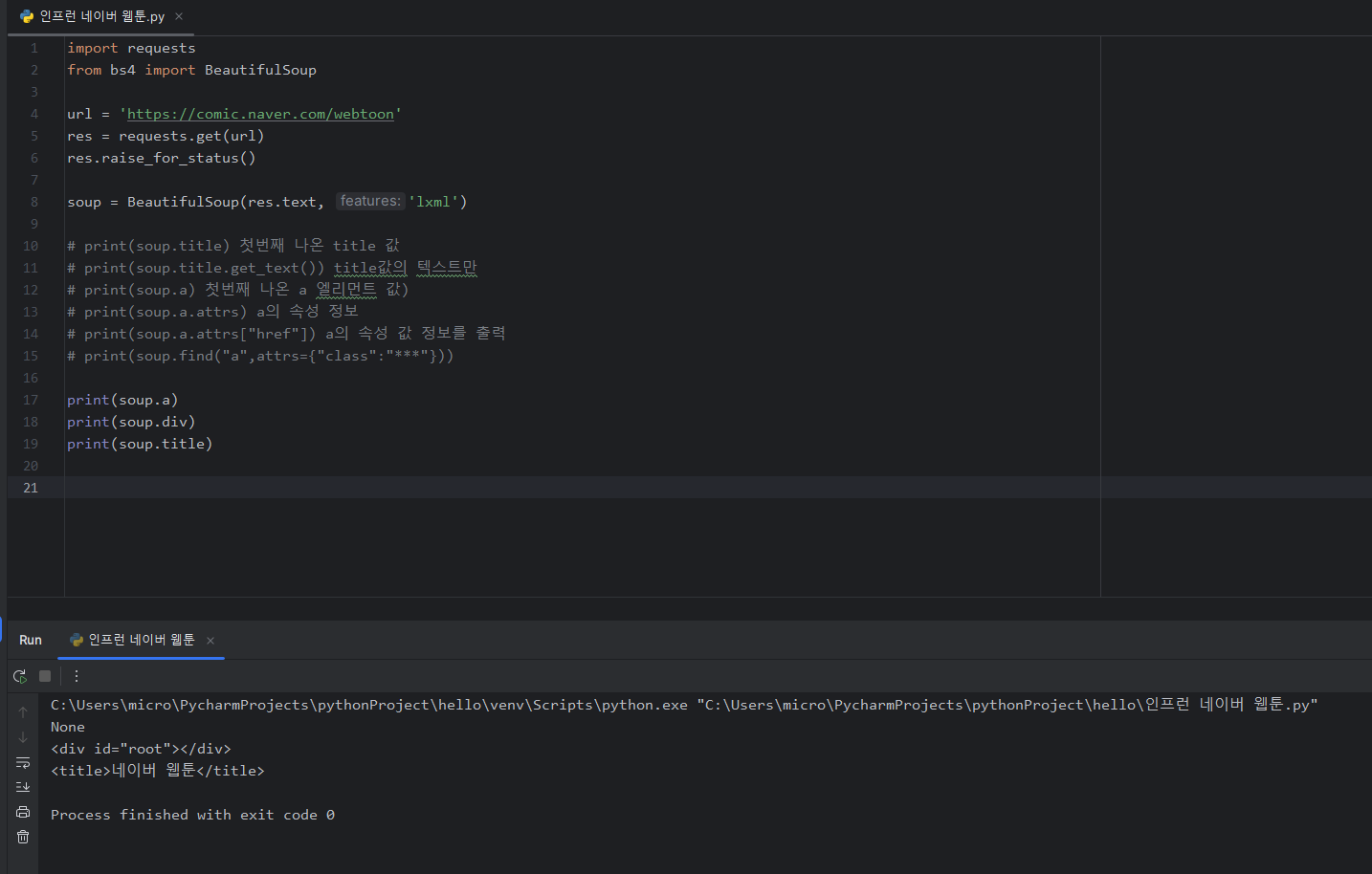
요약 - 네이버 웹툰에서 print(soup.a) 를 쓰면 Source - webtoon 만 스크래핑되어 None으로 반환되는 것 같습니다.
import requests
from bs4 import BeautifulSoup
url = "https://comic.naver.com/webtoon"
res = requests.get(url, headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
# print(soup.title)
# print(soup.title.get_text())
# print(soup.a)
print(soup.a)
with open("naverwebtoon.html", "w", encoding="utf8") as f:
f.write(res.text) 저도 같은 현상으로, 앞서 배웠던 코드를 활용하여
headers 코드를 작성해 보았으나, 동일한 현상이 발생(위의 코드에서는 삭제)
with open("naverwebtoon.html", "w", encoding="utf8") as f:
f.write(res.text)위 코드를 작성 후 실행 -> html 파일을 생성 후 해당 파일 내용 및 우클릭 - Open In Default Browser -> 해당 페이지와 네이버 웹툰 페이지와 비교 확인 시,
3. 네이버 웹툰 페이지의 Elements : div 밑에 a href가 확인
네이버 웹툰 페이지의 Sources - webtoon : 생성된 naverwebtoon.html의 내용과 동일하고 a 가 없음 때문에 a가 없는 관계로 None으로 나오는 듯 합니다.
때문에 a가 없는 관계로 None으로 나오는 듯 합니다.
위 목록을 보면 requests 라이브러리를 사용했을때, 처음 webtoon HTML만 가져오고, JavaScript에 의해 로드되는 아래 .js콘텐츠들은 가져오지 않는 것 같습니다.
저는 그래서 그냥 구글 페이지로 연습했네요ㅠ
혹시 위 내용이 틀렸거나, 해결 방법 찾으신 분들은 공유해주시면 감사하겠습니다🥹
0
0
안녕하세요, 인프런 AI 인턴이에요.
태그 관련 내용이 반환이 안 되는 이유는 다양할 수 있습니다.
가장 일반적인 이유는 웹 페이지에서 해당 태그가 존재하지 않거나, 코드에서 파싱하는 부분이 잘못되었을 가능성이 있습니다.
먼저, 웹 페이지에서 해당 태그가 존재하는지 확인해보세요.
웹 페이지의 HTML 코드를 확인하거나, 브라우저의 개발자 도구를 사용하여 해당 태그가 정확히 있는지 확인할 수 있습니다.
또한, 코드에서 해당 태그를 파싱하는 방법이 제대로 되었는지 확인해야 합니다.
BeautifulSoup과 같은 파싱 라이브러리를 사용하여 웹 페이지를 파싱하고 태그를 선택하는 로직이 정확한지 다시 확인해보세요.
태그 선택 시, 오타가 있는지 혹은 원하는 태그를 선택하는 로직이 잘못되지는 않았는지 다시 확인해보세요.
만약에 더 구체적인 코드나 웹 페이지에 대한 정보가 있다면, 좀 더 정확한 답변을 드릴 수도 있을 것 같아요.
답변을 드리기 어려울 경우, 지식공유자에게 문의하거나 구체적인 코드와 웹 페이지 정보를 함께 공유해주시면 좋을 것 같아요.
더 도움이 필요하시다면 언제든지 말씀해주세요! 좋은 결과 있으시길 바랄게요. 감사합니다.