인프런 커뮤니티 질문&답변
작성한 질문수

페이지 반복문 오류
해결된 질문
작성
·
318
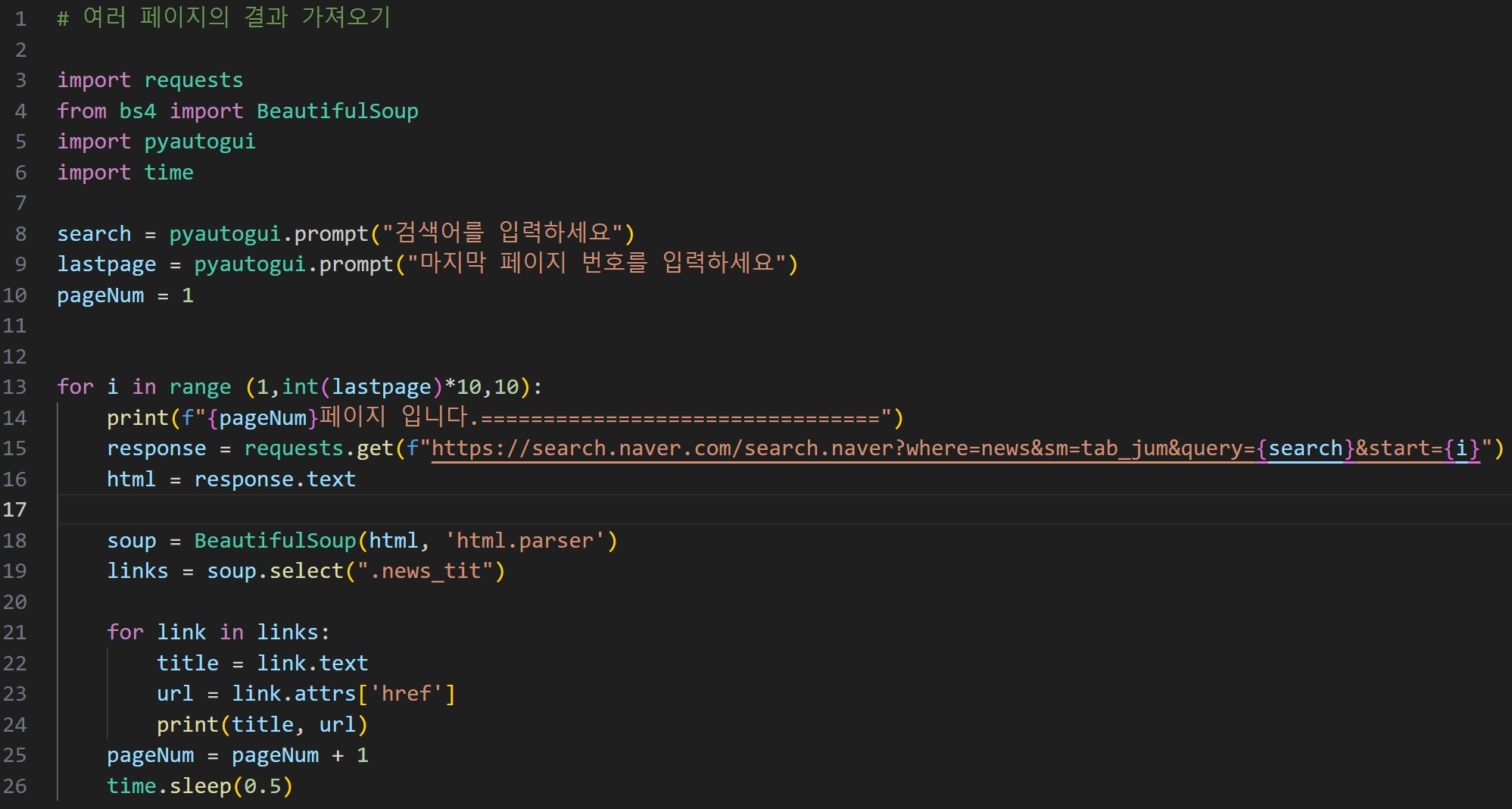 아래와 같이 1페이지까지는 제대로 출력이 되나 2페이지 이후로는 뉴스 제목과 링크가 가져와지지 않아요.왜 이런 오류가 발생하는 건가요.??
아래와 같이 1페이지까지는 제대로 출력이 되나 2페이지 이후로는 뉴스 제목과 링크가 가져와지지 않아요.왜 이런 오류가 발생하는 건가요.??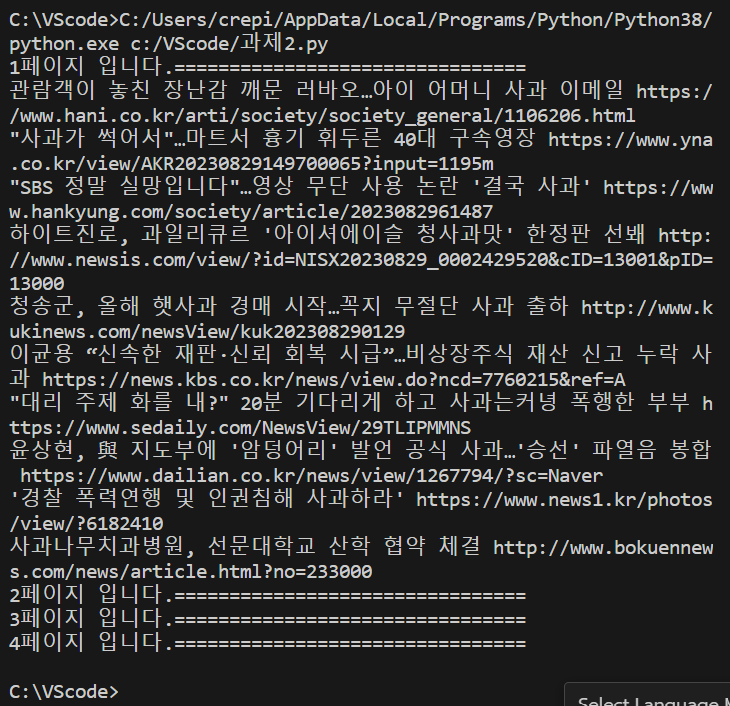
답변 1
0
스타트코딩
지식공유자
import requests
from bs4 import BeautifulSoup
import pyautogui
import time
keyword = pyautogui.prompt("검색어를 입력하세요")
lastpage = pyautogui.prompt("마지막 페이지번호를 입력하세요")
pageNum = 1
# 10페이지 까지 가져와보자
for i in range(1, int(lastpage)*10, 10):
print(f"{pageNum}번째 페이지 입니다=================")
response = requests.get(f"https://search.naver.com/search.naver?where=news&sm=tab_jum&query={keyword}&start={i}")
html = response.text
soup = BeautifulSoup(html, 'html.parser')
links = soup.select('.news_tit') # 결과는 리스트
for link in links:
title = link.text # 태그 안에 있는 모든 글자
url = link.attrs['href'] # href의 속성값
print(title, url)
pageNum = pageNum + 1
time.sleep(0.5)오타는 지금 특별히 안보이는데,
위 코드로 한번 테스트해보시겠어요?
정상 동작하는 코드입니다. (30페이지까지도 잘 가져와 집니다)