인프런 커뮤니티 질문&답변
작성한 질문수

규제 적용시 cross_val_score NaN반환
작성
·
566
0
- 학습 관련 질문을 남겨주세요. 상세히 작성하면 더 좋아요!
- 먼저 유사한 질문이 있었는지 검색해보세요.
- 강의 내용을 질문할 경우 몇분 몇초의 내용에 대한 것인지 반드시 기재 부탁드립니다.
- 서로 예의를 지키며 존중하는 문화를 만들어가요.
- 잠깐! 인프런 서비스 운영 관련 문의는 1:1 문의하기를 이용해주세요.
안녕하세요.
규제 부분 코드 실습 중 규제 클래스에 관해서 cross_val_score적용 시 NaN값이 반환되는 것이 확인되어 질문드립니다. 싸이킷런 버전의 경우 1.0.2버전인데
구글링을 했을 때는, 데이터 내에 NaN값이 있어서 그럴 것이라는데 제가 확인해봤을 때는 NaN값이 없었습니다.
혹시 버전과 관련된 문제일까요...?
동일 코드에 Ridge클래스대신 LinearRegression클래스로 대체시 정상적으로 코드가 동작하는 것을 확인하여 우선 Ridge클래스에 대한 문제로 간주하고 있습니다...ㅠ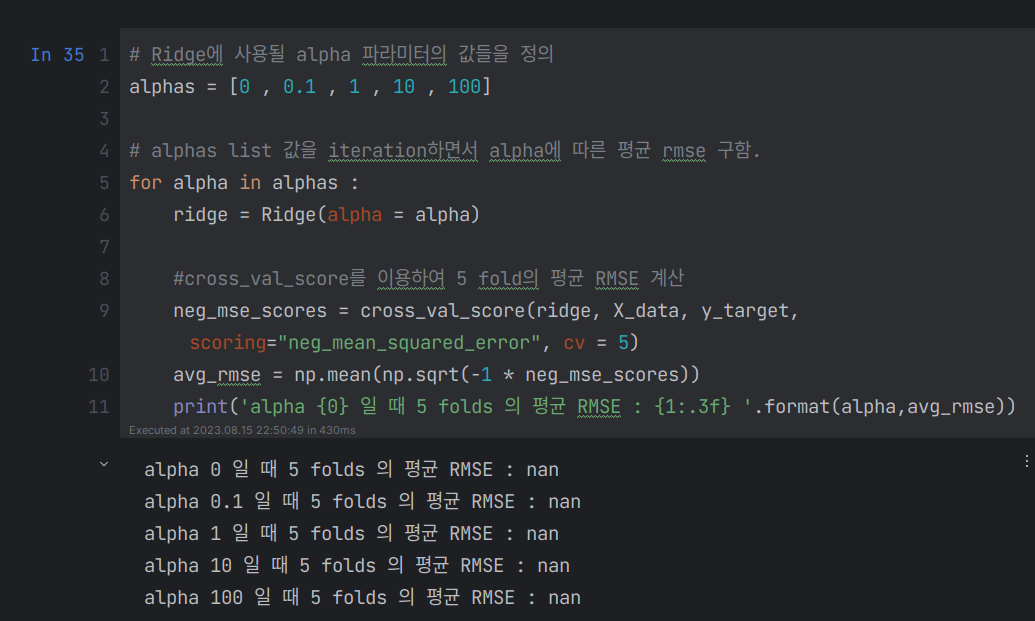
답변 3
0
저도 동일한 문제가 발생했는데, 제 경우
cross_val_score 호출 시 내부적으로 linalg.solve 를 호출하는데 sym_pos 파라메터가 deprecated(https://docs.scipy.org/doc//scipy-1.10.1/reference/generated/scipy.linalg.solve.html) 되서 발생하는 것으로 확인 되었습니다.
임시 방편으로 문제가 발생하지 않는 최상위 버전으로 변경 후 해결 하였습니다.
(pip install scipy==1.10.1 )
참고 하세요^^
0
저도 nan이 출력되었는데 해결했습니다.
bostonDF.info() 해보시면 category 타입의 컬럼이 있는데 이들을 drop 시키면 되더라구요
아니면 다른 처리를 하셔야할 것 같습니다.
0
안녕하십니까,
저는 사이킷런 1.0.2에서 아무런 오류가 발생하지 않는군요.
coss_val_score만 nan이 나오나요? 아님 아예 Ridge 회귀 자체가 문제 인지요?
제 생각엔 먼저 jupyter notebook 커널을 재 기동 부탁드리고, 혹시 여전히 안되면 아래 코드를 수행하시고 결과 부탁드립니다.
# 앞의 LinearRegression예제에서 분할한 feature 데이터 셋인 X_data과 Target 데이터 셋인 Y_target 데이터셋을 그대로 이용
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
# boston 데이타셋 로드
boston = load_boston()
# boston 데이타셋 DataFrame 변환
bostonDF = pd.DataFrame(boston.data , columns = boston.feature_names)
# boston dataset의 target array는 주택 가격임. 이를 PRICE 컬럼으로 DataFrame에 추가함.
bostonDF['PRICE'] = boston.target
y_target = bostonDF['PRICE']
X_data = bostonDF.drop(['PRICE'],axis=1,inplace=False)
ridge = Ridge(alpha = 10)
neg_mse_scores = cross_val_score(ridge, X_data, y_target, scoring="neg_mean_squared_error", cv = 5)
rmse_scores = np.sqrt(-1 * neg_mse_scores)
avg_rmse = np.mean(rmse_scores)
print(' 5 folds 의 개별 Negative MSE scores: ', np.round(neg_mse_scores, 3))
print(' 5 folds 의 개별 RMSE scores : ', np.round(rmse_scores,3))
print(' 5 folds 의 평균 RMSE : {0:.3f} '.format(avg_rmse))
저는 여전히 별 문제가 없습니다.
제가 colab url을 공유하니, 여기서 다시 한번 돌려 보시지요.
https://colab.research.google.com/drive/1UeUg0fmcH48Rb2Gy15ZF4zzPZG7K3O0D?usp=sharing
제 생각엔 작업하신 데이터 세트가 뭔가 다르게 수정된것 같습니다.
아니면, 새로운 주피터 노트북 커널을 열고, 아래 코드를 실행해 보십시요.
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_boston
import pandas as pd
import numpy as np
# boston 데이타셋 로드
boston = load_boston()
# boston 데이타셋 DataFrame 변환
bostonDF = pd.DataFrame(boston.data , columns = boston.feature_names)
# boston dataset의 target array는 주택 가격임. 이를 PRICE 컬럼으로 DataFrame에 추가함.
bostonDF['PRICE'] = boston.target
y_target = bostonDF['PRICE']
X_data = bostonDF.drop(['PRICE'],axis=1,inplace=False)
ridge = Ridge(alpha = 10)
neg_mse_scores = cross_val_score(ridge, X_data, y_target, scoring="neg_mean_squared_error", cv = 5)
rmse_scores = np.sqrt(-1 * neg_mse_scores)
avg_rmse = np.mean(rmse_scores)
print(' 5 folds 의 개별 Negative MSE scores: ', np.round(neg_mse_scores, 3))
print(' 5 folds 의 개별 RMSE scores : ', np.round(rmse_scores,3))
print(' 5 folds 의 평균 RMSE : {0:.3f} '.format(avg_rmse))
공유 주신 코드를 복사 붙여넣고 테스트해봤는데 NaN이 출력됩니다.
제가 생각하기에는 Ridge 클래스 자체 문제인것 같습니다.
cross_val_score에 선형회귀 클래스를 대입했을 때는 정상적으로 값이 출력됩니다!
심지어 Lasso, ElasticNet도 정상적으로 값이 출력됩니다.