인프런 커뮤니티 질문&답변
작성한 질문수

네이버 view탭 검색 결과 크롤링 2, 3 질문
작성
·
698
·
수정됨
1
안녕하세요 강사님. 질문이 있어서 남기게 되었습니다.
첫 번째 질문: 네이버 view탭 검색 결과 크롤링 2를 완료한 이후 아래 코드 실행 후 손흥민을 검색했는데 검색결과가 30개가 아닌 7개가 출력되었습니다. 이러한 이슈 때문인지 네이버 view탭 검색 결과 크롤링 3 강의가 정상적으로 진행되지 않습니다.
import requests
from bs4 import BeautifulSoup # beautiful soup 라이브러리 import
base_url = "https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query="
keyword = input("검색어를 입력하세요 : ")
url = base_url + keyword
print(url)
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36"
} # dictionary
req = requests.get(url, headers = headers) # GET 방식으로 naver에 요청
html = req.text # 요청을 하여 html을 받아옴
soup = BeautifulSoup(html, "html.parser") # html을 html.parser로 분석(클래스를 통한 객체 생성)
total_area = soup.select(".total_area")
timeline_area = soup.select(".timeline_area")
if total_area:
areas = total_area
elif timeline_area:
areas = timeline_area
else:
print("class 확인 요망")
for area in areas:
title = area.select_one(".api_txt_lines.total_tit")
name = area.select_one(".sub_txt.sub_name")
print(name.text)
print(title.text)
print(title["href"])
print()
print(len(areas))
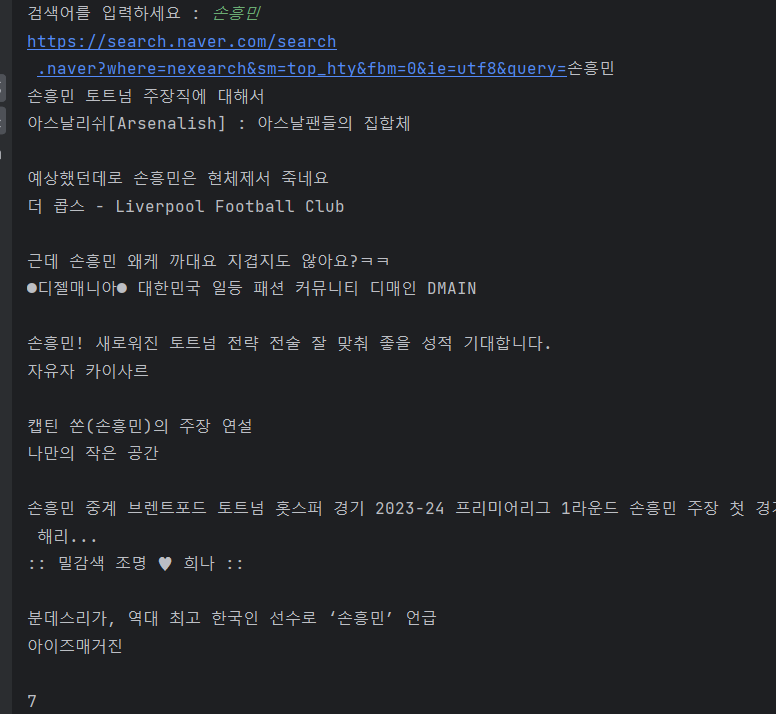
두 번째 질문: 네이버 view탭 검색 결과 크롤링 3을 진행하면서 아래 코드처럼 작성하고 손흥민을 검색했을 때 NoneType 오류가 발생합니다. 첫 번째 질문의 이슈로 인해 그런 것인가요? .total_wrap.api_ani_send 클래스가 브라우저 상에서는 30개가 잘 나오는데 제대로 안 받아와진 것 같은 느낌이 듭니다. 도와주시면 감사하겠습니다 ㅠㅠ
Traceback (most recent call last): File "C:\python_web_crawling\01_4_naver.py", line 30, in <module>
print(title.text)
^^^^^^^^^^
AttributeError: 'NoneType' object has no attribute 'text'
아래는 코드입니다.
import requests
from bs4 import BeautifulSoup # beautiful soup 라이브러리 import
base_url = "https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query="
keyword = input("검색어를 입력하세요 : ")
url = base_url + keyword
print(url)
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36"
} # dictionary
req = requests.get(url, headers = headers) # GET 방식으로 naver에 요청
html = req.text # 요청을 하여 html을 받아옴
soup = BeautifulSoup(html, "html.parser") # html을 html.parser로 분석(클래스를 통한 객체 생성)
items = soup.select(".total_wrap.api_ani_send")
for area in items:
# ad = area.select_one(".link_ad")
# if ad:
# print("광고입니다.")
# continue
title = area.select_one(".api_txt_lines.total_tit")
name = area.select_one(".sub_txt.sub_name")
print(title.text)
print(name.text)
# print(title["href"])
print()
#print(len(items))답변 1
1
김플
지식공유자
base_url에 문제가 있습니다.
BBangJun님이 사용하신 base_url을 사용해서 손흥민을 검색하면 아래와 같은 url입니다.
https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query=손흥민
접속해 보면 view탭이 아닌 걸 확인하실 수 있습니다.
감사합니다. 김플님! 사소한 실수 하나가 굉장히 크게 다가오네요... 덕분에 완강할 수 있었습니다 ㅎㅎ 조만간 좋은 후기로 뵙겠습니다!!