인프런 커뮤니티 질문&답변
작성한 질문수

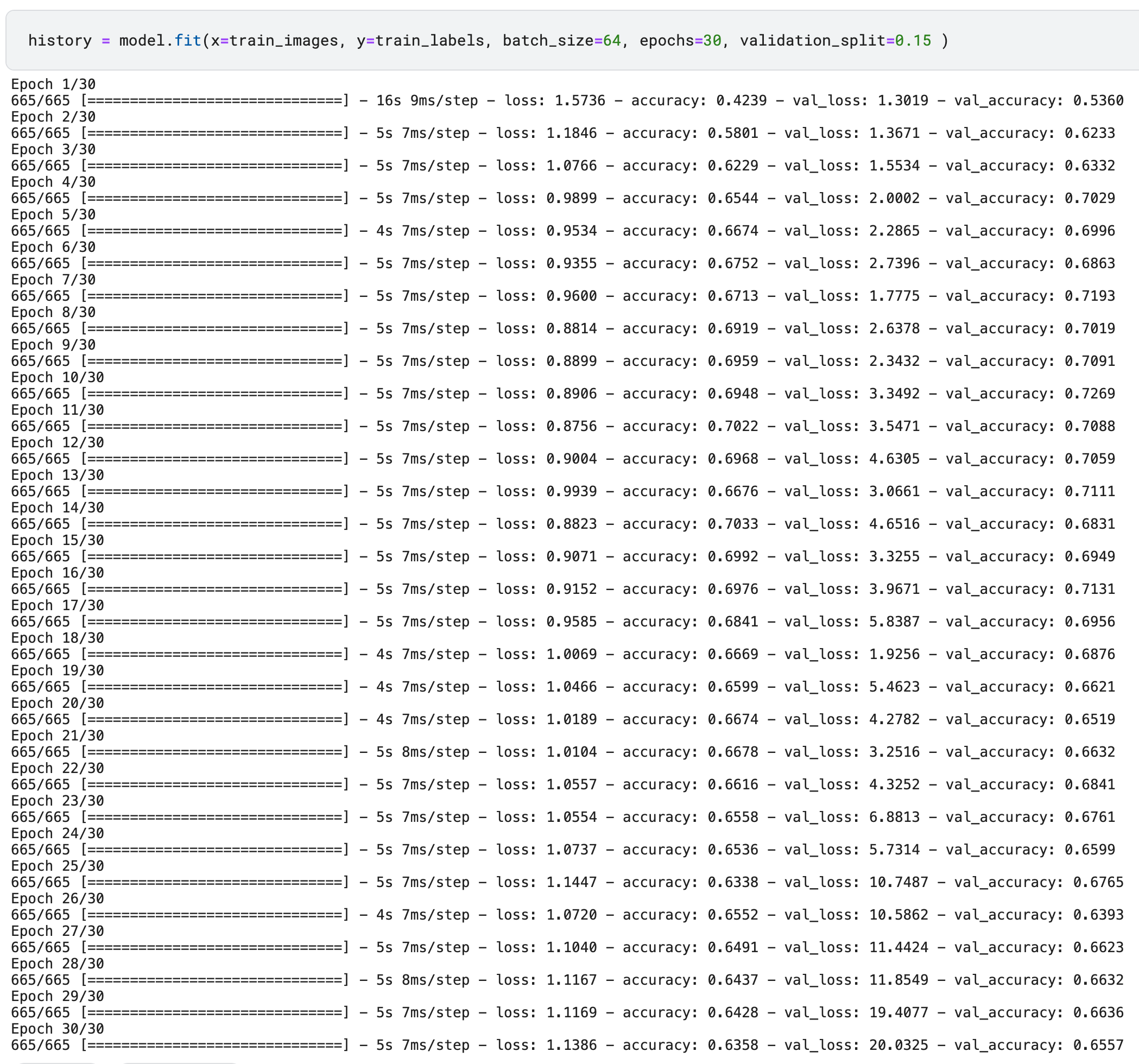
val_loss값이 계속 커지는 현상이 왜 나오나요?
작성
·
571
답변 2
0
권 철민
지식공유자
안녕하십니까,
저도 테스트를 해보는데, 현재 Tensorflow version 2.12로 해보면, 강의를 만들었을 때와 다르게 검증 데이터에서 오락가락(?)하는 부분이 있군요. 이건 좀 더 테스트가 필요할 것 같습니다.
좀 더 테스트 해보고 답변 드리도록 하겠습니다.
kjyn0124 님도 답변 감사합니다.
0
y 값으로 one-hot encoding 된 label인 train_oh_labels를 넣으셔야 하는데 그냥 train_label을 넣으셔서 생긴 문제 같습니다. 그래서 val_loss 뿐만 아니라 loss 값도 커지고.... 제대로 학습이 이뤄지지 않고 있는 듯 합니다.
답변 감사합니다.
이번 코드는 원핫인코딩을 하지 않은 것이라 loss 함수로 sparse_categorical_crossentropy를 사용했습니다.
model.compile(optimizer=Adam(), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
강의 중에
원핫인코딩 → categorical_crossentropy
인코딩 안하면 → sparse_categorical_crossentropy
사용하라고 하셨는데, 둘 간의 성능 차이가 있나요?
먼저 현재 tensorflow 2.12에서는 강의 실습 화면과 다르게 모델의 검증 데이터 평가 지표가 오락 가락합니다.
일단 kaggle에서 tensorflow 버전을 아래와 같이 2.8로 downgrade 해서
!pip install tensorflow==2.8.0
이후 아래와 같이 버전이 2.8로 나오는지 확인해 주십시요.
from tensorflow as tf
print(tf.__version__)
2.8에서는 성능이 괜찮게 나오는데 2.12에서는 왜 그런지 아직 원인을 찾지 못했습니다. 여러가지로 테스트 중인데, 원인 파악에 시간이 좀 더 필요할 것 같습니다. 일단은 2.8로 강의 수강을 진행 부탁드립니다.