인프런 커뮤니티 질문&답변
작성한 질문수

질문이 두가지 있습니다.
작성
·
346
0
CSS selector를 사용하여 크롤링을 하는 방법 강의에서 질문 있습니다.강의는 섹션 4에 3강이구요. 12분 15초부터 진행되는데 지금 강사님이 올려주신 깃허브 코드가 좀 바껴서 그런지 모르겠는데 li.course.paid라는 코드 자체가 없어요. 그래서 제가
(중급) - 자동으로 쿠팡파트너스 API 로 가져온 상품 정보, 네이버 블로그/트위터에 홍보하기 [412] 이 문장을 css selector로는 도저히 크롤링을 못하겠어서 find를 사용해서 크롤링을 시도해봤으나 코드가 안되네요.
제가 작성한 코드입니다.(find 함수 사용)
import requests
from bs4 import BeautifulSoup
res = requests.get('https://davelee-fun.github.io/blog/crawl_test')
soup = BeautifulSoup(res.content,'html.parser')
items = soup.find_all('a')
print(items)
먼저 코드를 이렇게 작성해 list형태로 나오는걸 확인 후
import requests
from bs4 import BeautifulSoup
res = requests.get('https://davelee-fun.github.io/blog/crawl_test')
soup = BeautifulSoup(res.content,'html.parser')
items = soup.find_all('a')
for title in items:
print(title[15].get_text())
이렇게 진행해보았는데 안됩니다... 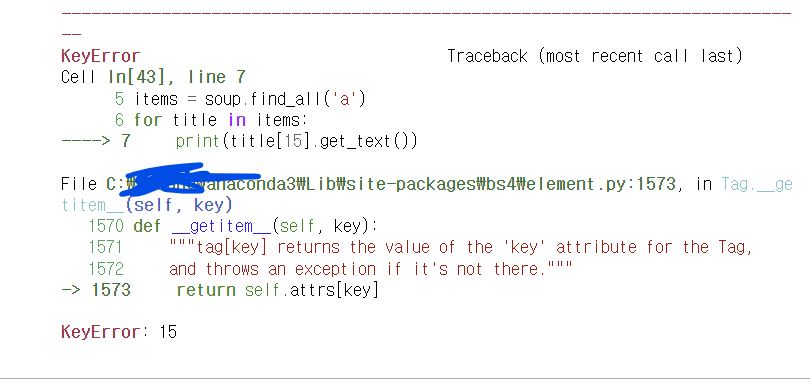
질문1, 제가 작성한 코드에 잘못된 점 있을까요?
질문2. 지금 올라와있는 깃허브코드에서
<a href="https://www.fun-coding.org">(중급) - 자동으로 쿠팡파트너스 API 로 가져온 상품 정보, 네이버 블로그/트위터에 홍보하기 [412]</a>
도저히 css selector로 해당 문장만 뽑아내는 방법이 생각이 안납니다.
이것도
import requests
from bs4 import BeautifulSoup
res = requests.get('https://davelee-fun.github.io/blog/crawl_test')
soup = BeautifulSoup(res.content,'html.parser')
items = soup.select('ul#dev_course_list>li.course')
for title in items:
print(title[8].get_text())
이렇게 해보니까 안되네요.
답변 2
0
find_all로는 이렇게
import requests
from bs4 import BeautifulSoup
res = requests.get('https://davelee-fun.github.io/blog/crawl_test')
soup = BeautifulSoup(res.content,'html.parser')
items = soup.find_all('a')
items[15].get_text()
css selector로는 import requests
from bs4 import BeautifulSoup
res = requests.get('https://davelee-fun.github.io/blog/crawl_test')
soup = BeautifulSoup(res.content,'html.parser')
items = soup.select('ul#dev_course_list>li.course')
items[8].get_text()
이런식으로 작성하니까 해결되네요;;
다해놓고 마지막 코드를 이상하게 작성하고 있었네요..
그럼 제가 이런식으로 코드를 짜는건 제대로 한게 맞겠죠?
0