인프런 커뮤니티 질문&답변
작성한 질문수

작업형2 모의문제 2 질문있습니다!
해결된 질문
작성
·
357
0
안녕하세요!
작업형 2 모의문제 2의 마지막에 csv파일을 제출할 때 에러가 발생하는데, 어떤 이유인지 찾아봐도 안보여 질문드립니다.
그리고 작업형 2유형의 train과 test데이터 파일만 주어진 경우, 어떤 문제는 n_train, c_train, n_test, c_test로 나누는 문제가 있고 그렇지 않은 문제들이 있어서 헷갈립니다ㅠ 그래서 문제를 읽고 데이터를 분리해야하는 상황이 궁금합니다!
import pandas as pd
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
# print(train.head())
# print(test.head())
# print(train.info()) 1. 불필요한 컬럼제거 2. 결측치 대치 3. 인코딩 4. 스케일링
# print(test.info())
train = train.drop(columns ='id')
test_id = test.pop('id')
# print(test_id)
cols = ['host_id','neighbourhood_group','neighbourhood','name', 'host_name', 'last_review']
# print(train.shape)
train = train.drop(cols, axis =1)
test = test.drop(cols, axis =1)
# print(train.shape)
# train = train.drop(columns ='host_id')
# test = test.drop(columns ='host_id')
# train = train.drop(columns ='neighbourhood_group')
# test = test.drop(columns ='neighbourhood_group')
# train = train.drop(columns ='neighbourhood')
# test = test.drop(columns ='neighbourhood')
# train = train.drop(columns ='name')
# test = test.drop(columns ='name')
# train = train.drop(columns ='host_name')
# test = test.drop(columns ='host_name')
# train = train.drop(columns ='last_review')
# test = test.drop(columns ='last_review')
# print(train.info())
# print(test.info())
# print(train.isnull().sum())
# print(test.isnull().sum())
train['reviews_per_month'] = train['reviews_per_month'].fillna(0)
test['reviews_per_month'] = test['reviews_per_month'].fillna(0)
# print(train.isnull().sum())
# print(test.isnull().sum())
#라벨 인코딩
from sklearn.preprocessing import LabelEncoder
cols =train.select_dtypes(include = 'object').columns
for col in cols:
encoder = LabelEncoder()
train[col] = encoder.fit_transform(train[col])
test[col] = encoder.transform(test[col])
# print(train.info())
# print(test.info())
# print(train.describe())
# print(test.describe())
# 스케일링
from sklearn.preprocessing import minmax_scale
cols2 = train.select_dtypes(exclude = 'object').columns
for col in cols2:
train[col] = minmax_scale(train[col])
cols2 = test.select_dtypes(exclude = 'object').columns
for col in cols2:
test[col] = minmax_scale(test[col])
# print(train.describe())
# print(test.describe())
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(train.drop('price', axis=1), train['price'], test_size=0.2, random_state=20)
# print(X_train.head())
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor()
rf.fit(X_train, y_train)
pred = rf.predict(X_val)
# print(pred)
#id,price
sumit = pd.DataFrame({'id': test_id, 'price' : pred})
submit.to_csv('10004.csv', index=False)
답변 1
0
퇴근후딴짓
지식공유자
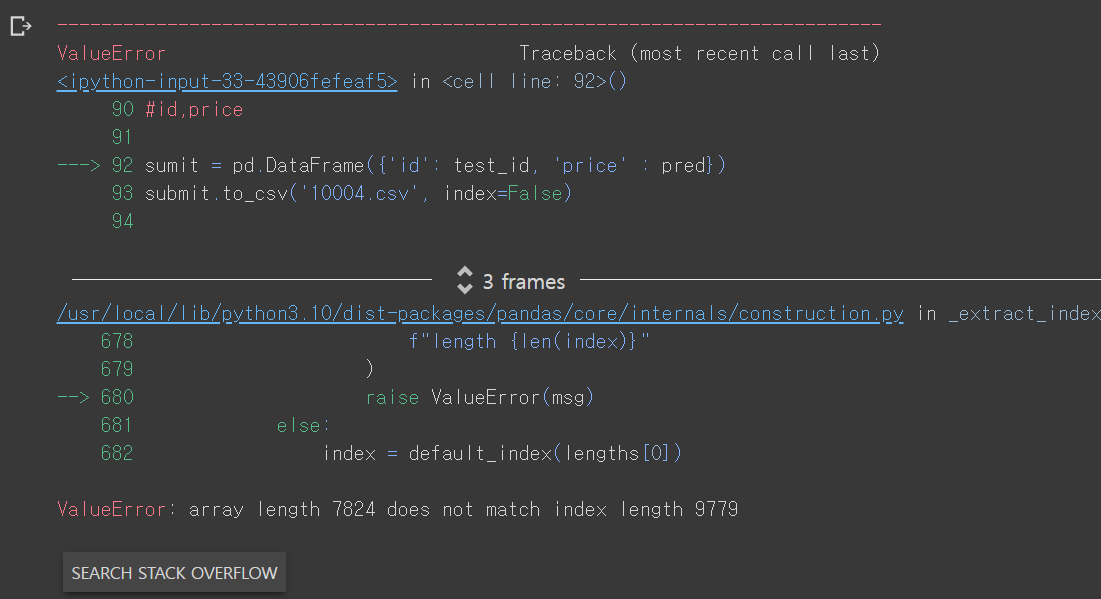
92번에 표시가 되어 있고 value에러가 발생했네요
내용을 읽어 보니 데이터의 길이가 맞지 않는 상황입니다.
92번을 살펴보니 test_id가 있고 pred가 있네요
둘 중 하나는 7824개고 나머지 하나는 9779로 예상되네요
왜 길이가 안맞을까요?
test_id는 그대로 복사한거니 큰 이슈가 없을 것 같고
pred를 의심해봐야겠네요
pred로 대입한 문장으로 따라 올라가보겠습니다.
코드를 살펴보니 예측한 결과 값은 맞는데 validation(검증)데이터 였네요!!
에러가 없으려면 test 데이터를 예측해야 합니다.
pred = rf.predict(X_val)이렇게만 하면 validation을 나눈 의미가 없습니다.
검증데이터는 평가해보기 위해 분할한거에요~
2 전처리 방식의 차이 입니다
나누는 방식을 활용해도 되고, 컬럼을 선택하는 방식을 활용해도 됩니다. 다양한 방법이 있음을 보여드렸습니다.