인프런 커뮤니티 질문&답변
작성한 질문수

3회 기출유형(작업형2)_ csv 파일 생성 오류 등
해결된 질문
작성
·
296
·
수정됨
0
안녕하세요.
강의 잘 듣고 있습니다. 항상 어의없을 질문에도 친절하게 답해주셔서 정말 감사드립니다.
3회 기출유형(작업형 2)에서 관련해서 문의드립니다.
1. 문제를 보고 회귀인지 분류인지 구분이 잘 안될 땐 모델링을 회귀도 해보고 분류도 해봐서 가장 성능이 좋은 걸 사용하면 되겠죠?
2. 확률을 예측할 때
분류모델이면 proba를 써야하는데
predict=model.predict_proba(x_val)회귀모델일 경우에는 proba를 사용 안 해도 되나요?
predict=model.predict(x_val)
3. Unnamed: 0 변수를 의미없는 값이라고 생각하여 데이터 전처리 과정 중에
train, test 데이터에서 모두 drop을 했습니다.
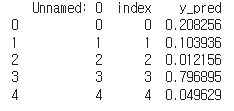
근데.... 왜 csv 파일 생성할 때, 다시 나타난 걸까요...ㅠㅠ
<출력된 csv 파일..>
<코드>
# 라이브러리 및 데이터 불러오기
import pandas as pd
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
# EDA
pd.set_option('display.max_columns',None)
print(train.head()) # target: TravelInsurance 포함되어 있음
print(test.head())
print(train.shape, test.shape)
print(train.info())
print(train.describe())
print(train.describe(include= 'object')) # Employment Type GraduateOrNot FrequentFlyer EverTravelledAbroad
print(train.isnull().sum())
print(train.value_counts('TravelInsurance')) # 0 965, 1 525
# 데이터 전처리(결측치: 없음, 의미 없는 칼럼 삭제, ID 처리: 없음) # Unnamed: 0 삭제
train = train.drop('Unnamed: 0', axis = 1)
test =test.drop('Unnamed: 0', axis = 1)
print(train.shape, test.shape)
print(train.head())
print(test.head())
# 피처엔지니어링(범주형)
from sklearn.preprocessing import LabelEncoder
cols = ['Employment Type', 'GraduateOrNot', 'FrequentFlyer', 'EverTravelledAbroad']
for col in cols:
la = LabelEncoder()
train[col] = la.fit_transform(train[col])
test[col] = la.transform(test[col])
# 데이터 분할
from sklearn.model_selection import train_test_split
x_tr, x_val, y_tr, y_val = train_test_split(train.drop('TravelInsurance', axis =1), train['TravelInsurance'], test_size = 0.2, random_state = 2023)
print(x_tr.shape, x_val.shape, y_tr.shape, y_val.shape) # (1192, 8) (298, 8) (1192,) (298,)
# 모델링(회귀)
# import sklearn
# print(sklearn.__all__)
# print(sklearn.linear_model.__all__)
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(x_tr, y_tr)
predict=model.predict(x_val)
print(predict)
# 성능평가(roc_auc_score)
from sklearn.metrics import roc_auc_score
r = roc_auc_score(y_val, predict)
print(r) #베이스: 0.7544863861386139
# 예측
predict=model.predict(test)
# 데이터 내보내기
submit = pd.DataFrame(
{
'y_pred' : predict
}
).reset_index().to_csv("1111.csv")
df1 = pd.read_csv("1111.csv")
print(df1.head())
답변 1
0
퇴근후딴짓
지식공유자
종류(카테고리)가 구분 된다면 분류, 가격/수요량 등 연속형 숫자면 회귀 입니다
분류도 proba는 확률값을 물을 때(roc auc로 평가할 때)만 입니다
predict도 사용해요! (F1, 정확도 등 평가)
회귀는 확률값이란게 없어 proba가 없어요
to_csv 괄호안 옵션으로 index=False가 필요합니다
화이팅👏👏👏