인프런 커뮤니티 질문&답변
작성한 질문수

Partition by 컬럼 2개 설정에 대한 질문입니다.
작성
·
845
0
안녕하세요 강사님
너무 재밌게 강의를 듣고 있는 수강자 입니다.
이번 집계 Anlaystic SQL 를 실습하다가 한가지 궁금한게 있어서요.
with절을 사용하지 않고, 한번에 조회를 해보고 싶어서 해봤는데.. 뜻대로 잘 안되네요 ㅠㅠ
[퀴리문]
-- 직원별 개별 상품 매출액, 직원별 가장 높은 상품 매출액을 구하고, 직원별로 가장 높은 매출을 올리는 상품의 매출 금액 대비 개별 상품 매출 비율 구하기
select o.employee_id as eId,p.product_id, p.product_name, sum(oi.amount)over(partition by o.employee_id, p.product_id)
from nw.orders o
join nw.order_items oi on o.order_id = oi.order_id
join nw.products p on oi.product_id = p.product_id
order by 1;
이렇게 partition by 에 컬럼을 2개 이상으로 하면, 제 생각에는 2개가 group by 처럼 진행 되는 걸로 생각했는데 안되더라고요 ㅠㅠ
[결과 값]
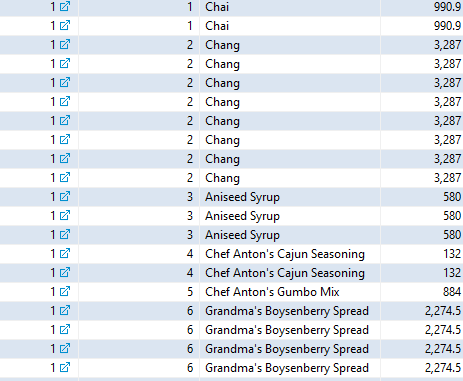
이런 결과 값이 중복으로 나오는데.. 혹시 이러한 이유를 알려주실 수 있나용 ㅠ_ㅠ
답변 1
0
안녕하십니까,
작성하신 SQL을 적용하면 중복으로 값이 나옵니다. 왜냐하면 조인을 orders와 order_items를 order_id로 하여서 최종 조인 집합레벨은 order_items이 됩니다. (order_id로 orders가 1, order_items는 m)
그리고 이 최종 조인 집합은 employee_id와 product로 중복 되어 있습니다. order가 employee로 m이고, order_item가 product_id로 m이기 때문에 employee_id와 product로 중복 되어 있습니다.
아래 쿼리로 확인하실 수 있습니다.
select o.employee_id as eId,p.product_id, count(*) as cnt
from nw.orders o
join nw.order_items oi on o.order_id = oi.order_id
join nw.products p on oi.product_id = p.product_id
group by o.employee_id, p.product_id
having count(*) > 1;
하지만 analytic SQL은 집합의 레벨을 group by 처럼 변경하지 않습니다. employee_id와 product_id 레벨로 sum analytic을 사용하여 원하는 값을 추출할 수는 있지만, 중복된 값은 나올 수 밖에 없습니다.
아래와 같이 실습 코드의 결과 값과 동일한 sum_amount는 추출할 수는 있지만, 레코드가 중복됩니다.
select o.employee_id as eId,p.product_id, p.product_name,
sum(oi.amount) over (partition by o.employee_id, p.product_id) as sum_amount
from nw.orders o
join nw.order_items oi on o.order_id = oi.order_id
join nw.products p on oi.product_id = p.product_id
order by eId, sum_amount desc;
감사합니다.