인프런 커뮤니티 질문&답변
작성한 질문수

sync/async fetcher 크롤링 전체가 안됩니다.
작성
·
247
답변 1
0
안녕하세요 구자웅님.
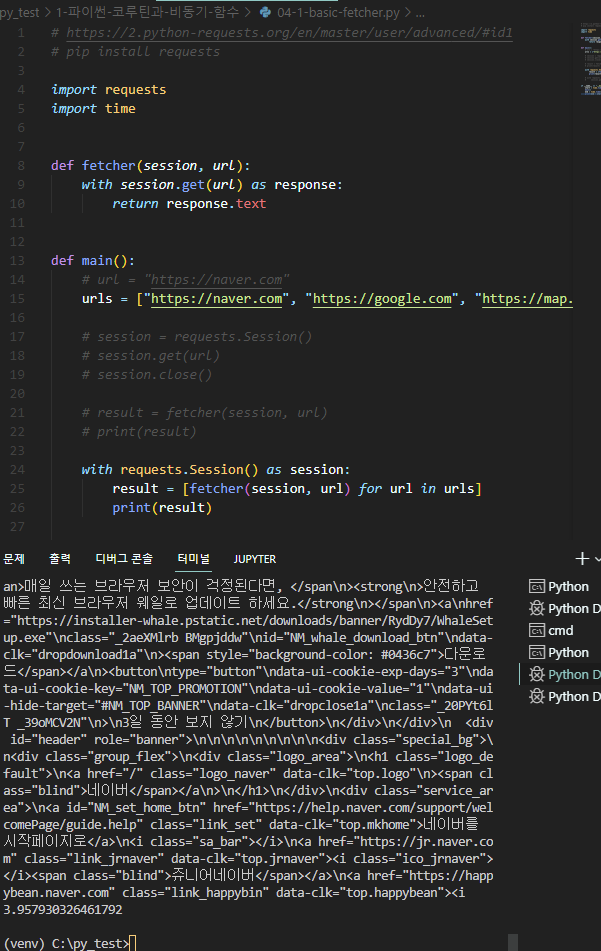
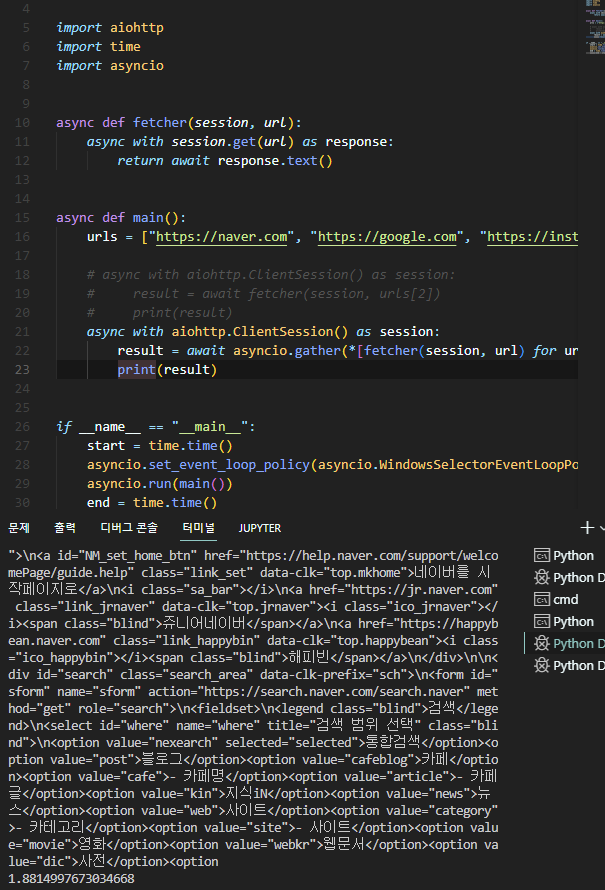
질문해주신 첫번째 코드를 아래와 같이 실행해본 결과 네이버와 구글의 모든 소스코드가 크롤링 된 것을 확인했습니다.
import requests
import time
def fetcher(session, url):
with session.get(url) as res:
return res.text
def main():
urls = ["https://www.naver.com", "https://www.google.com"]
with requests.Session() as session:
result = [fetcher(session, url) for url in urls]
print(result)
if __name__ == "__main__":
main()질문을 조금 더 자세하게 작성해주시면, 답변하기 조금 더 수월할 것 같습니다.
더불어 코드는 인프런의 에디터에 포함되어 있는 [코드 입력기]로 전체 코드를 복사 붙여넣기 해주시면 감사하겠습니다.
자세한 질문 내용 새로운 게시글로 작성해주시면, 곧바로 답변해드리겠습니다.
감사합니다 :)