인프런 커뮤니티 질문&답변
작성한 질문수

크롤링, db g마켓 실습 질문
작성
·
403
0
안녕하세요. 좋은 강의 감사합니다.
g마켓 크롤링, db 실습을 하다 궁금한 점이 생겨 질문드립니다.
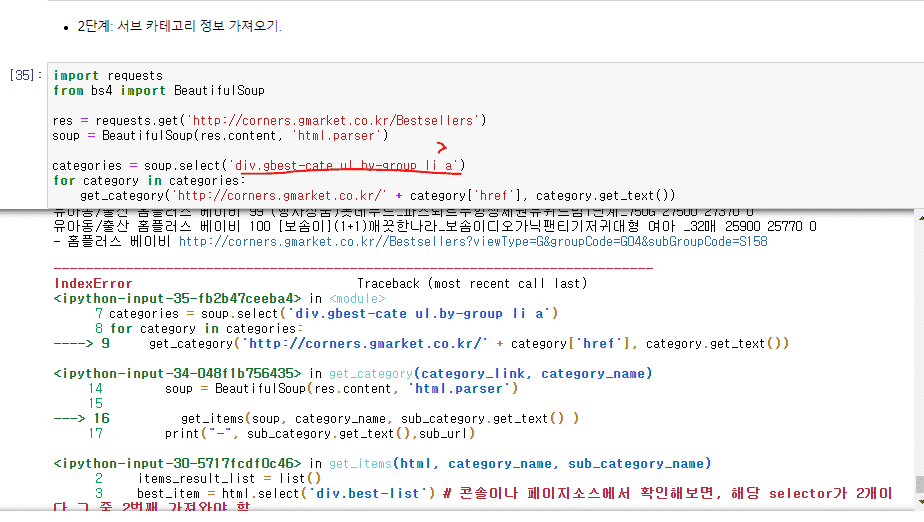
크롤링에서 밑 캡처 이미지처럼 에러가 생겼을 때, li 바로 밑 'a'만 가져오기 위해 >를 써야한다고 하셨습니다. 일부 카테고리 중에서 li밑에 우리가 가져오지 말아야 할 다른 a도 있는 이슈가 있어서라고 설명해주셨는데요. 그런데, 여기서 에러가 나서 이 부분을 고쳐야하는지는 어떻게 아시나요? 처음 에러라고 뜨는 부분이 저 부분이기 때문에, g마켓 들어가서 저 부분만을 하나하나 뜯어 살펴서 에러를 고쳐나가는 건가요?
= 실전 실무에 어떻게 적용되는지 알려주시는 파트라, 실전에서 누가 저에게 에러가 나는 부분과 크롤링 or db 이슈를 알려주지는 않기 때문에 제가 실전에서 에러를 찾아가는 과정이 궁금해서 여쭤봤습니다. 이러한 크롤링 or db 에러가 나타났을 때 딱 에러가 난 부분을 찾기 위해서는 노가다를 해서 하나하나 다 살펴봐야하는지, 혹은 팁이 있는지 등이요. 감사합니다.
답변 2
0
0
안녕하세요.
꼼꼼하시네요. 좋은 질문같아요 ㅎㅎ
일단, 꼭 이코드뿐만 아니라 큰 그림으로 말씀을 드리면, 만약에 css selector 가 잘못 지칭된 부분이 있거나 할 경우,
예를 들어,
category = soup.select('div') 와 같은 코드가 있다고 한다면요.
category 는 None 이 될꺼예요. 그러면 for item in category: 이런 구문은 아무 동작을 안할 것이고요.
category = soup.select_one('div') 와 같은 코드가 있다고 한다면요.
category.get_text() 는 에러가 날 꺼예요. category 가 None 이기 때문에, 여기에 get_text() 를 하면 문제가 생기겠죠.
그래서, 이런 에러가 나면, 하도 많이 나니까요. 딱 태그가 문제구나 이렇게 이해하고, css selector 를 바꿔보거나, 웹소스를 뜯어보고요.
코드가 매우 복잡하면, 이렇게 select 등을 해서 얻어진 변수(객체) 바로 밑의 코드에서
특정 페이지에서 이슈가 되는 부분을 잡아내기 위해, print() 구문이나 assert 구문을 쓰기도 합니다.
이 때는 어느 페이지에서 이슈가 되는지를 찾아내기 위해, 각 페이지에 대한 정보와 함께 출력을 해봐서, 문제가 있을 경우, 해당 페이지부터 볼 수 있도록 일종의 로그 코드를 넣기도 합니다.
좀 복잡하고 설명이 완벽히 깔끔하지는 않네요. 추후에 한번 유투브든 따로 해서, 이런 부분들을 예제를 만들어서 찍어보든지 해보는 것도 좋겠다는 생각이 드네요. 어쨌든 도움이 되셨으면 좋겠습니다. ... --;
감사합니다.