인프런 커뮤니티 질문&답변
작성자 없음
작성자 정보가 삭제된 글입니다.

질문 드립니다. Quiz 답안의 실행시 에러 발생원인을 알고 싶습니다.
해결된 질문
작성
·
419
0
답변 4
0
0
좋은 강의 재차 감사드립니다.
머신러닝을 경청하면서 질문이 있어 올렸습니다.
회귀모형에서의 평가지표가 R-제곱, RMSE, RAE, MSE로 평가하지 않는지요?
문제에서, 새로운 값에 예측값의 문제가 나온다면 대응방법 부탁드립니다.
ML_bigineer2까지 평가 척도가 Confusion matix의 분류정확도로 답안이 작성되는 것 같아
궁금하여 질문을 드립니다.
정말 좋은 강의 감사합니다.
코드를 숙지하는 것이 좋을지요.. 이해보다는 며칠 남지 않아서
일단 외울려고 합니다. 작업형 유형 1이 상당히 Bottleneck입니다
맞습니다.
저도 계속해서 새로운 언어나 라이브러리 등을 익히려면
너무 낯설고 어려워 이걸 내가 쓸 수나 있을까 싶습니다.
하지만 해야하니 한다라는 마음으로, 일주일 동안 꾸준히 하면 어느정도 눈에 들어오고,
이삼 주 정도 되면 어느새 익숙하게 써내려가는 자신을 보게 됩니다.
하나하나 이해하며 익히기 어려운 분들의 위해
이 강의를 통해 시험범위를 대부분 커버(시험범위 전부 및 이후 예측범위까지)했으나,
이를 단순하게 외우는 것은 쉽지 않습니다.
(물론 문제와 답을 매칭시켜서 풀 수도 있게 만들어놓긴 했습니다)
제가 가장 추천드리는 것은 강의를 수강하신 이후,
노션 강의 교재 상의 코드와 텍스트를 위주로 빠르게 3회 이상 돌려보시는 것을 추천드리며
같은 문제를 오늘, 내일, 모레까지 반복해서 풀어보시다보면 어느새 익숙해져있으실 겁니다.
또한 충분히 남은 시간 내 어느정도 익숙해지셔서 풀 수 있을만한 시간이라고 생각합니다.
자신감을 가지시고, Keep Going하시는 것을 추천드립니다.
감사합니다!
0
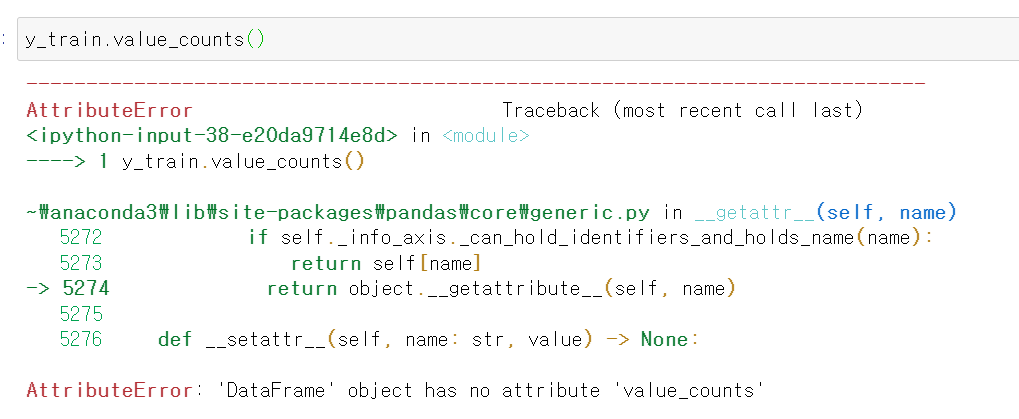
안녕하세요, Jongdeok Heo님!
아마도 pandas beginner #1에서 위와 같은 문제가 발생한 것으로 보입니다.
위 출력 결과는 해당 데이터 프레임이 비어있음을 의미합니다.
아무래도 데이터 프레임을 불러오신 것이 아니라, 직접 칼럼과 데이터를 입력으로 주고 사용한 것이 아닌가 싶습니다.
때문에 colab의 해당 데이터를 다음과 같이 클릭해 다운로드하고, 불러와 사용하시면
보다 편하게 학습하실 수 있을 것 같습니다!
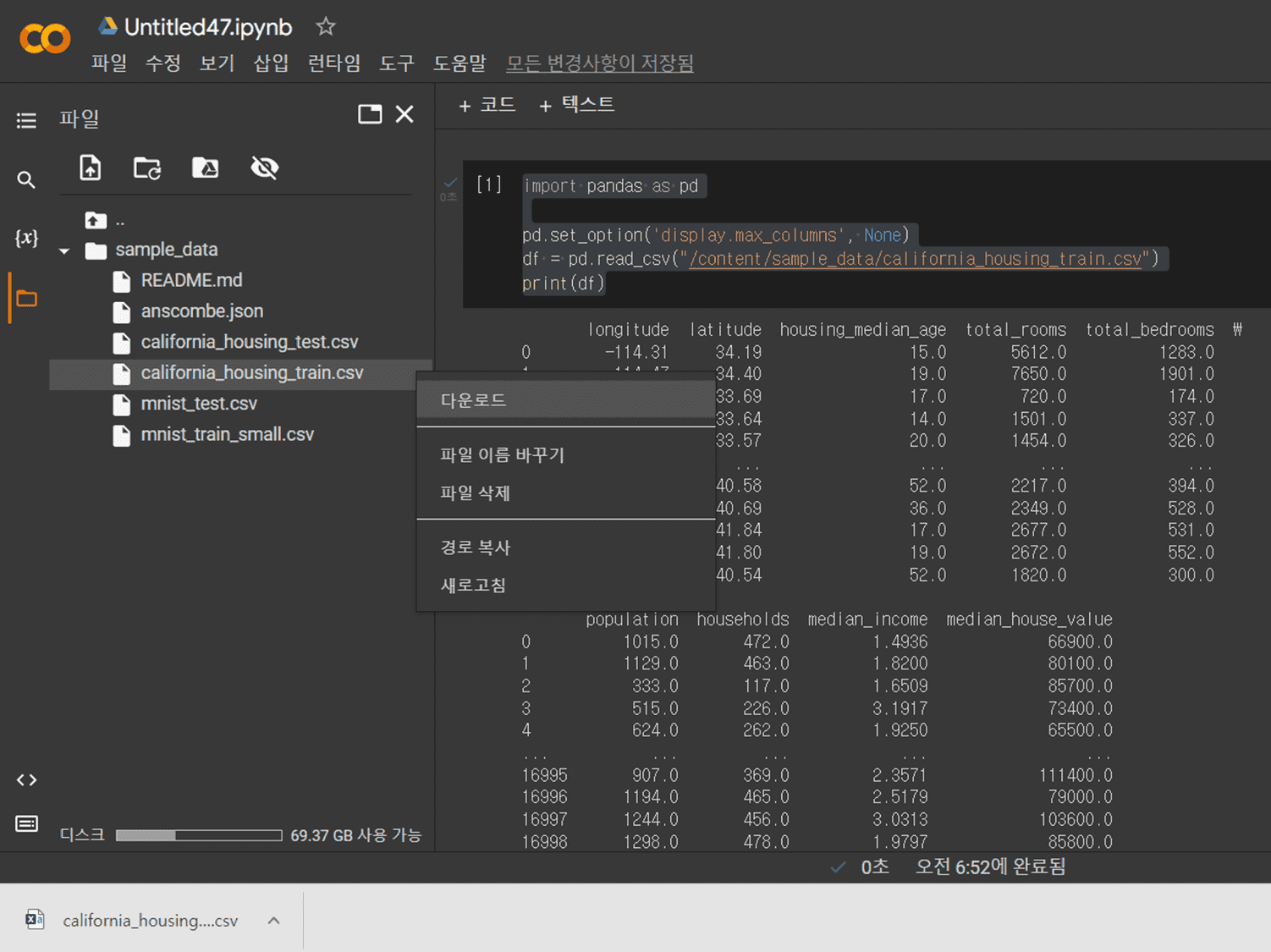
위 이미지처럼 우선 코랩에 연결한 후,
왼쪽의 작업 폴더를 열어, sample data 폴더 안의 우리가 학습용으로 사용하는 데이터를 다운로드 해주시면 됩니다.
그 이후에는 작업하는 파이썬 코드와 같은 폴더 안에 넣은 뒤 다음과 같이 불러와 사용하시면 됩니다.
만약 위 답이 질문에 대한 적절한 답이 되지 못했다면 댓글이나 추가 질문으로 남겨주시면,
다시 답변드리도록 하겠습니다.
이른 아침부터 공부하고 질문을 남기시다니 아주 멋지시네요!
감사합니다.
raw data는 kaggle에서 다운받아서 실습했습니다. 코랩의 raw data를 다운 받아 사용할 수 없을지요.? 저는 visual studio code로 실습하고 있습니다.
선생님, 좋은 강의 감사드립니다.
실습화일을 kaggle에서 *.csv화일을 다운 받아 본인의 작업 경로에 연결하여 실습을 하고 있습니다. 코랩에 접속 동영상을 얼핏 들었는 것 같은데, 실습화일을 깃튜브로 다운 받을 수 있을지요 ? 자주 질문을 드려 송구스럽게 생각합니다.
답변을 드리기에 앞서 특별히 로컬 환경에서 비주얼 스튜디오를 사용하는 이유가 따로 있으실까요? 정확히는 코랩을 쓰지 않는 이유에 가깝습니다.
만약 해당 데이터를 원하시면 제가 위에서 설명한 직접 다운받는 것 외에 깃허브를 찾아봤으나 아쉽게도 따로 깃허브를 통해 가져오기는 어려운 것 같습니다. 제가 임의로 다운받아서 깃허브에 올려놓기엔 윤리적인 문제가 있을듯 하구요.
만일 코랩을 쓰기 어렵고, 데이터를 캐글 등에서 일일히 가져오시는게 번거로우시다면 sklearn 라이브러리의 dataset 모듈을 통해 데이터를 불러오는 방식을 알려드리는 게 나으실까요?
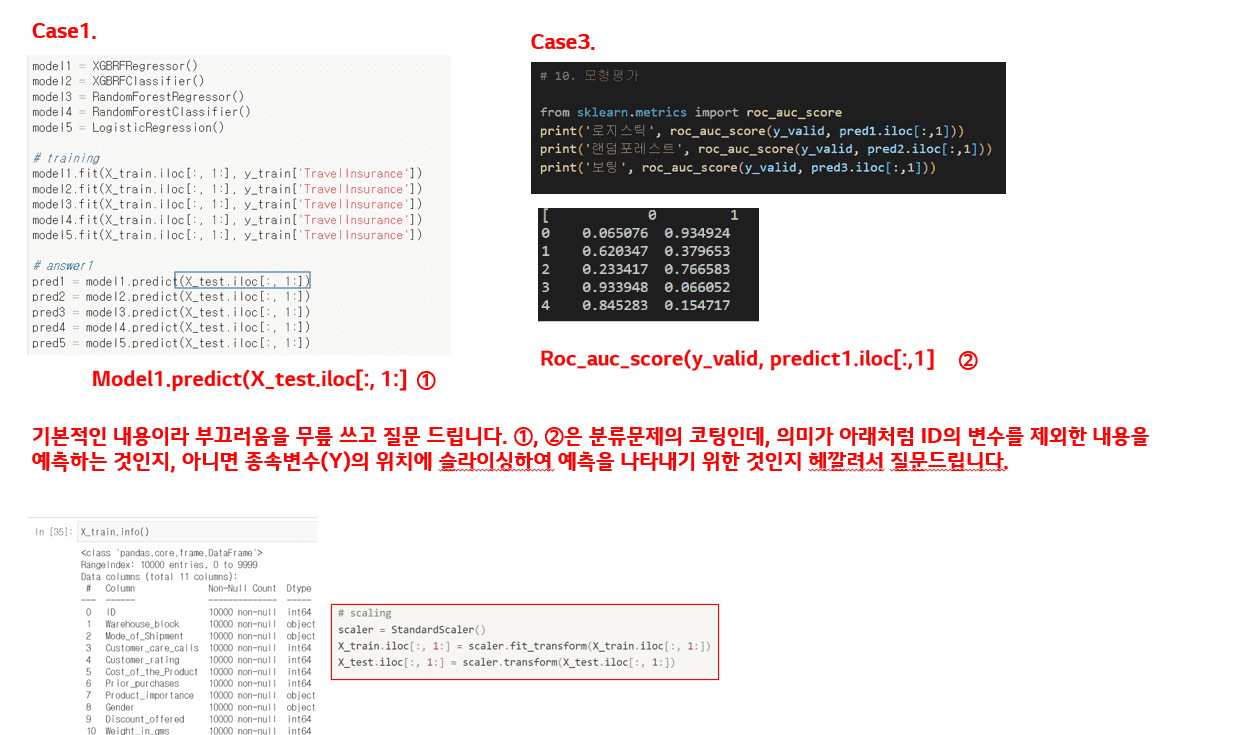
안녕하세요, 제가 프로젝트가 진행 중이라 바빠 답변이 느렸던 점 사과드립니다.
우선 질문해주신 내용 중 슬라이싱의 종류에는 크게 세 가지가 있습니다.
첫 번째는 Scaling을 위한 슬라이싱입니다.
이때에는 굳이 Scaling을 적용할 필요가 없는 칼럼(예를 들어, ID값이라거나 단순 Index값)을 제외하고 슬라이싱하는 경우입니다.
만약 Scaling을 하고자 하는 칼럼이 첫 번째 칼럼인 ID값을 제외한 전부라면 iloc를 이용해, df.iloc[:, 1:]와 같이 적용할 수 있습니다. 이 외에도 특정 칼럼명을 정확하게 지정하고 싶다면, 칼럼명을 리스트 형태로 따로 지정한 뒤 이를 사용하는 방법도 있습니다.
두 번째는 회귀 모델을 통한 예측을 위한 슬라이싱입니다.
이때에는 굳이 말하자면 슬라이싱이 필요하지 않습니다.
0 혹은 1을 맞추는 이진 분류 문제를 예를 들면, 회귀모형의 경우 각 칼럼의 영향력을 계산해 0과 1 사이의 값을 추론하게 됩니다. 이때 confusion matrix 상의 지표를 이용해 평가를 하기 위해선 정수형으로 맞춰야 하기 때문에 일반적으로 0.5 이상인 값을 1로 두거나, 데이터 분석을 통해 특정한 값을 지정해서 변환하기도 합니다.
때문에 이때에는 1) 모델을 통해 예측하고, 2) 특정 기준(0.5 등)에 의거해 정수화하는 과정만이 필요합니다.
마지막으로는 분류 모델을 통한 예측을 위한 슬라이싱입니다.
분류 모델의 경우, predict를 하면 가장 확률이 높은 레이블을 출력하고, predict_proba를 하면 각 클래스별 확률을 출력하게 됩니다.
유명한 예제인 MNIST(0~9까지의 숫자를 분류하는 손글씨 이미지 문제 및 데이터)와 같은 데이터셋을 사용했고, 그 데이터셋의 규모가 만 개라면 predict를 했을 때는 10000개의 예측값을 가진 리스트가 반환되고, predict_proba를 했을 경우엔 10000 x 10(0~9까지 아홉 개 숫자 예측)의 매트릭스가 반환되게 됩니다.
즉, 임의로 6이라는 숫자를 적어서 추론하게 하면 predict를 통해선 그냥 6이라고만 결과가 나오고, predict_proba의 경우엔 이 손글씨가 [0일 확률, 1일 확률, 2일 확률, 3일 확률, ... , 9일 확률]을 각각 표시하는 것입니다.
때문에 이러한 분류 문제를 이진분류 문제에 적용하고, 회귀적인 확률로 표현하고 싶을 땐 predict_proba(X_train)[:,1]을 함으로써 [0일 확률, 1일 확률]로 n개(전체 row 수)만큼 출력된 결과물 중에서 [1일 확률]만을 뽑아내는 것입니다.
정리하면, 다음과 같습니다.
[이진 분류 문제라 가정했을 때...]
1. predict를 했을 때, 회귀모델은 0에서 1 사이의 실수값을(ex. 0.1, 0.58, 0.777888...), 분류 모델은 0 또는 1을 출력한다.
2. 분류 모델의 경우, predict_proba를 통해 각각의 레이블에 대한 확률을 출력할 수 있으며, [:, 1]와 같은 슬라이싱을 통해 [1일 확률]만을 가져올 수 있다.
3. 스케일링은 스케일링이 유의미한 칼럼에만 하면 충분하다. 굳이 인덱스, ID값 등에 할 필요 없으며, 원핫 인코딩으로 임베딩한 칼럼 또한 할 필요 없다.
혹시 추가적인 의문이나 이해 안가는 부분 있으시면 질문 남겨주시면 감사하겠습니다.
참고로 이전 질문에 댓글 형태로 질문을 올리셨을 경우, 왜인지 이메일로 알람은 오나 실제 글이 몇 시간 동안 확인되지 않는 문제가 있는 것 같아 새로운 질문으로 올려주셔도 됩니다.
감사합니다.
정말 친절한 답변 감사드립니다.
선생님, Label encoding을 할 경우, column명의 문자간 간격이 있으면 에러가 발생하는데,
한꺼번에 해결방법이 없는지요?
import pandas as pd
train = pd.read_csv('https://raw.githubusercontent.com/Datamanim/datarepo/main/airline/x_train.csv')
test = pd.read_csv('https://raw.githubusercontent.com/Datamanim/datarepo/main/airline/x_test.csv')
display(train.head(2))
===============================================================
label = ['Gender', 'Customer Type', 'Type of Travel', 'Class']
from sklearn.preprocessing import LabelEncoder
X_train[label] = X_train[label].apply(LabelEncoder().fit_transform)
X_test[label] = X_test[label].apply(LabelEncoder().fit_transform)
================================================================
에러 메시지
KeyError Traceback (most recent call last) <ipython-input-44-e25735fb8911> in <module> 1 label = ['Gender', 'Customer Type', 'Type of Travel', 'Class'] 2 from sklearn.preprocessing import LabelEncoder ----> 3 X_train[label] = X_train[label].apply(LabelEncoder().fit_transform) C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\frame.py in __getitem__(self, key) 2804 if is_iterator(key): 2805 key = list(key) -> 2806 indexer = self.loc._get_listlike_indexer(key, axis=1, raise_missing=True)[1] 2807 2808 # take() does not accept boolean indexers C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\indexing.py in _get_listlike_indexer(self, key, axis, raise_missing) 1550 1551 self._validate_read_indexer( -> 1552 keyarr, indexer, o._get_axis_number(axis), raise_missing=raise_missing 1553 ) 1554 return keyarr, indexer C:\ProgramData\Anaconda3\lib\site-packages\pandas\core\indexing.py in _validate_read_indexer(self, key, indexer, axis, raise_missing) 1637 if missing == len(indexer): 1638 axis_name = self.obj._get_axis_name(axis) -> 1639 raise KeyError(f"None of [{key}] are in the [{axis_name}]") 1640 1641 # We (temporarily) allow for some missing keys with .loc, except in KeyError: "None of [Index(['Gender', 'Customer Type', 'Type of Travel', 'Class'], dtype='object')] are in the [columns]"
=======================================================================================
Customer Type와 Type of Travel는 문자간의 간격이 있어 실행이 안되는 것 같습니다. 잘못 이해했는지 모르겠습니다만 에러 메시지가 열이름을 인식 못한다는 의미가 아닌지요>위의 오류는 X_train에 해당 이름의 칼럼명이 없음을 의미합니다.
아무래도 연습 중에 위 문제는 train, test로만 불러오시고,
이전에 작업하셨던 X_train을 대상으로 불러와 작업해 해당 데이터 프레임에는 해당 칼럼이 없음을 의미하는 에러 출력으로 보입니다.
X_train과 X_test를 불러오신 변수명인 train과 test로 사용하시면 정상적으로 작동이 가능합니다.
또한 One Hot Encoding을 위한 방법 중 하나인 sklearn의 LabelEncoder의 경우, 한 번에 하나의 칼럼만 작업할 수 있게 되어있고, 이를 여러 칼럼에 적용하기 위해 리스트 컴프리헨션이나 반복문, 사용하신 apply 등을 통해 작업하실 수 있으나, 위와 같은 코드로 진행하셨을 경우 만일 train과 test 데이터셋의 변환하고자 하는 칼럼의 값의 종류가 다르거나 할 경우 서로 다른 값으로 임베딩 될 수 있음을 유의하시길 바랍니다.
정리하면 다음과 같습니다.
1. 복수의 칼럼명을 지정해서 사용하시는 방법은 위에서 이미 사용하신 방법이 맞습니다.
2. 단지 데이터 프레임의 변수명이 달라서 생긴 문제로 확인됩니다.
3. 위와 같은 방법으로 원핫인코딩을 진행했을 경우, 각 칼럼의 값의 종류가 다를 경우 다르게 임베딩이 진행되며, 이를 굳이 LabelEncoder를 사용하기 위해 함수 정의, 리스트 컴프리헨션 등을 적용하기보다 수업에서 다룬 pandas의 get_dummies를 사용하시길 권장드립니다.
0
안녕하세요, Jongdeok Heo님!
질문해주셔서 감사합니다.
말씀하신대로 회귀모형은 분류모형과 다른 척도를 적용해야 합니다.
하지만 해당 강의는 회귀모형으로 결론을 출력하는 방법에 대해서는 다루지만
(ex. 회귀모형을 사용하는 법, 분류모형으로 회귀 모형처럼 추론하는 법 등),
대부분 분류형 문제를 풀게 되는데요.
그 이유는 다음과 같습니다.
첫째, 말씀하신 오차를 기반으로 한 성적의 경우,
공모전 등에서 아주 미세한 차이만으로도 서열을 나누는 것은 괜찮지만,
시험의 경우에는 이를 단순히 적용하기 어렵기 때문입니다.
하나의 분류 문제를 틀린 것과 제곱오차 0.001 차이로 점수가 나뉘는 것은 다른 문제이니까요.
때문에 이런 시험의 성격상, 회귀 모형을 사용해야 하더라도 결국은 분류 문제로 나올 수밖에 없다는
제 나름의 분석이 가미된 결과입니다.
둘째, 저는 이번 시험의 실기를 합격하기 위해 머신러닝에 대해
그렇게 자세히 알 필요는 없다고 판단하고 있습니다.
그 이유는 아마 제가 강의에서 수차례 설명드린대로, 시험에 응시하는 환경적 한계로 인해
문제는 간단할 수밖에 없고, 그 간단한 문제를 맞추기 위해선 제가 소개하는 인공지능 모델들과
방법론으로 충분하며 그 내부의 원리를 이해하는 것은 지난하기 때문입니다.
그 방법론을 하나하나 이해하고 파악하는 것도 재밌고, 유익한 시간일 수 있으나
이 강의는 소개된 바와 같이 최단 시간 내에 최소한의 노력만으로 확실하게 시험을 합격하게 만들기 위한 것입니다.
이러한 이유로 말씀하신 회귀적 모형에 대한 평가지표는 우선 순위에서 어느정도 배제했으며, 만약의 경우를 대비해 회귀적으로 추론하는 방법에 대해서도 다뤘음을 말씀드리며 답변 마치겠습니다.
감사합니다.