인프런 커뮤니티 질문&답변
작성한 질문수

안녕하세요 선생님!! 장고 엑셀다운로드 로딩에 대하여 질문드립니다
작성
·
491
0
안녕하세요!! 선생님!!! ㅎㅎㅎ 장고 다운로드 로딩에 대하여 질문드리려 합니다!!
(웹은 장고로만 개발하였습니다!!)
제가 구현한 내용은 단순히 모델을 불러와서 가공후 csv 파일로 response하는 view를 만들었습니다!
그래서 다운로드 버튼을 클릭하면 모델에 있는 데이터가 다운이 되는 그러한 로직입니다!
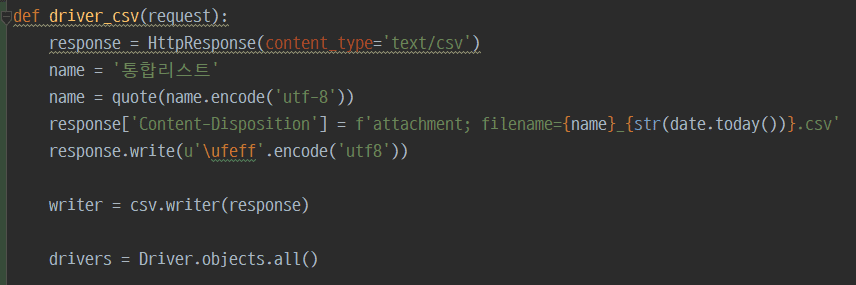
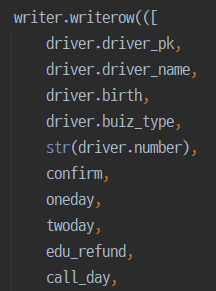

위와 같이 그냥 요청이 오면 모델을 불러와서 응답해주는?? 단순한 view입니다!ㅎ
다만 join이 많이 걸려있고 데이터가 좀 많다보니 시간이 상당히 많이 소요가 되는데요..
문제가 다운로드버튼(위에 설명한 view와 연결한버튼)을 클릭 한 후 서버가 이를 처리를 하는데
서버자체가 이 작업을 끝날때 까지 먹통이되는? (제 3자가 웹에 접속했을때도 이 처리 때문에 위 처리가 끝날때 까지 아무런 요청을 할 수 없습니다) 문제가 발생합니다..
제가 사용한 서버는 AWS EC2를 활용해 도커 compose파일로 nginx, gunicorn, mariadb를 연결해서 하나의 서비스로 만들어 배포하였습니다. 또한 로드밸런서 세팅도 되있습니다.
로컬에서 개발서버로 테스트 할때는 그냥 다운로드 버튼을 클릭을 해도 바로 종료가 가능하고 다른 브라우저로 접근해도 독립적으로 작동했는데 배포를 하니깐 위와 같은 현상이 발생하네요!
서버 성능의 문제인가 해서 인스턴스 유형도 좀더 올려보고 했지만 역시 위문제는 해결되지 않았습니다..ㅠ
그래서 뭔가 비동기적으로 처리하기위해서 celery를 이용해 볼까 했는데 잘못된 접근인건지 잘모르겠지만 피라미터를 어떻게 설정해야할지 몰라서 구현에 실패를 했습니다 ㅠ
서버의 문제라면 어떻게 접근을 해야하는지,,,,, 아니면 장고로 위와 같은 문제가 해결이 가능하다면 어떻게 코드를 작성하면 좋을지
부족한게 많다보니 며칠째 해결이 안되네요 ㅠㅠ
부족한 설명이지만 잘 부탁드리겠습니다!!
너무 감사합니다 선생님!!
답변 1
1
안녕하세요.
queryset을 통해 가져오는 데이터가 너무 크고 순회가 오래 걸려서, 서버의 CPU/MEMORY 자원이 부족한 것은 아닐까요? 그래서 다른 요청까지 처리에 대기가 걸리는 건 아닌가 싶습니다. 컨테이너 자원 메트릭을 확인해보시는 것이 필요해보입니다.
다음 포스팅을 참고하여 쿼리셋에 iterator를 써보시면 어떨까 싶구요.
http://raccoonyy.github.io/using-django-querysets-effectively-translate/
그리고 혹시 csv 데이터를 메모리에 모두 쌓은 뒤에 응답을 주시는 듯 한데요. 이런 방식은 서버에 너무 부담이 됩니다. 넷플릭스에서 영화 1편을 볼 때 넷플릭스 서버가 4GB의 영상파일을 모두 메모리에 올린 뒤에 응답을 준다고 생각해보세요. 4GB의 파일을 모두 메모리를 올리는 데에도 시간이 많이 걸리며, 유저 1명당 최소 4GB 이상의 메모리를 소모하게 되어 비효율적이 됩니다. 그렇게 하기보다, 지정단위(예: 4MB)로 파일을 읽자마자 유저에게 바로 스트리밍을 하는 거죠. 그리고 또 파일을 읽자마자 유저에게 스트리밍합니다. 이것이 스트리밍이죠. // 이는 파이썬 문법의 Generator에 대해서 살펴보시면 도움이 됩니다.
아래의 장고 공식 문서을 참고해보세요.
https://docs.djangoproject.com/en/4.0/howto/outputting-csv/#streaming-csv-files
그리고, View에서 너무 무거운 작업을 하시는 데요. 말씀하시는 대로 Celery와 같은 Task Queue를 통해 별도의 프로세스를 통해 처리하시는 것이 좋습니다. Celery Worker 수행에 필요한 최소한의 인자만 넘기고, 쿼리셋 로딩 등은 Celery Worker 내에서 모두 수행하시는 거죠. // 그리고 이는 다운로드로 처리하시기보다, Celery Worker 에서 모두 처리 후에 email로 발송토록 하는 것이 보다 간결하고 일반적인 프로세스일 수 있습니다. // Celery 처리와 함께 웹에서 다운로드를 하실려면, 웹프론트엔드 단에서 Worker 작업완료 체킹을 위해 Polling을 하시거나 websocket 처리가 필요할 수도 있습니다.
화이팅입니다. :-)