인프런 커뮤니티 질문&답변
작성한 질문수

@StepScope + JpaItemReader에서 EntityManager Null Pointer exception 발생 문제 도와주세요!
작성
·
1.2K
0
안녕하세요, 강사님. 항상 좋은 강의 제공해주셔서 감사합니다.
다름이 아니라 이번에 강사님 강의 보고 복습하던 도중에 문제가 발생해서 해결 방법이 있을까 해서 여쭤보려고 글을 작성했습니다.
파티셔닝 Step을 생성해서 처리하는 것을 따라해보고 있는데, 강사님께서는 ItemReader를 Jdbc 계열로 사용하셨는데, 저는 JPA를 선호해서 JPAItemReader를 사용했습니다.
먼저 단위 테스트를 위해 @StepScope 없이 JPAItemReader를 사용할 경우, 문제 없이 동작하는 것을 확인했습니다. 그런데 JpaItemReader에 @StepScope를 다는 순간 Null Pointer Exception이 발생하는 것을 확인했습니다.
처음에는 JpaItemReader가 Proxy Bean으로 주입이 안되는가? 라고 생각을 했었는데, 디버그 모드를 타고 가보니 다음과 같은 위치에서 문제가 있는 것을 확인했습니다.
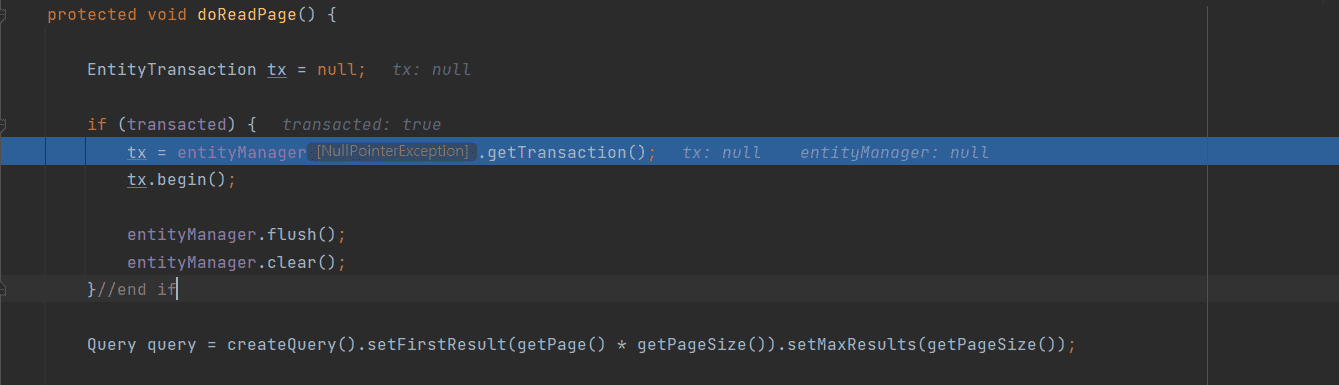
프록시 객체에 타겟 객체는 정상적으로 주입을 해주는데, 문제는 타겟 객체인 JpaItemReader에 entityManager가 null이기 때문에 Reader를 하는 과정에서 문제가 있다는 것을 알게 되었습니다.
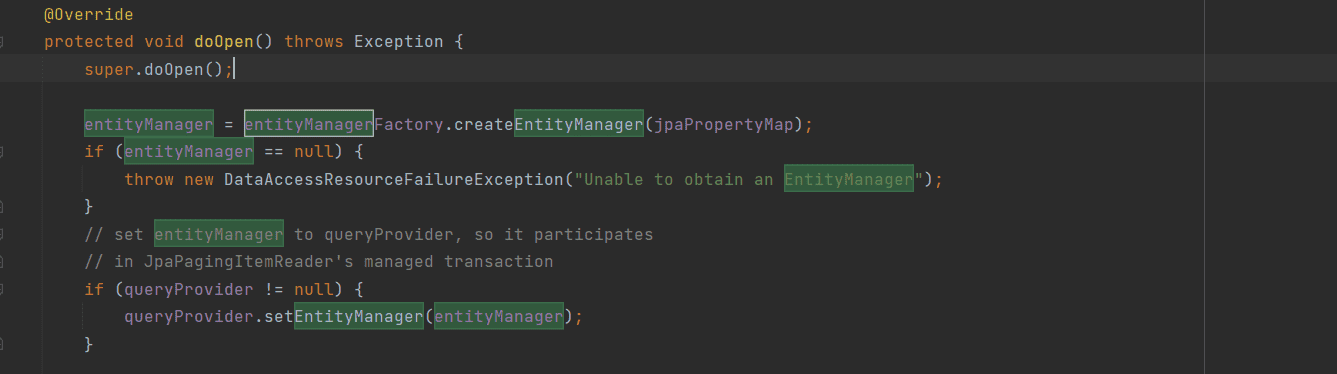
EntityManager는 위에서 볼 수 있듯이 doOpen() step에서 제공해주는 것으로 보이는데, doOpen() Step을 거치지 않아 문제가 있는 것 같습니다.
조금 더 확인해보니 AbstractStep의 Open 메서드에 전달되는 ItemStream의 Size가 0인 것을 보니... 이것에 대해 문제가 있는 것 같습니다.
혹시 이처럼 JpaItemReader에서 @StepScope로 사용 시, EntityManager가 주입되지 않는 경우는 어떻게 해결해야 할까요?
아래는 제가 PartitionStep을 구성하기 전에 각각의 ItemReader, ItemWriter, ItemProcessor에서 @StepScope가 정상적으로 동작하는지 확인하기 위해 작성한 코드이고, 이 코드를 돌릴 때 문제가 발생하는 것을 확인했습니다.
package io.springbatch.springbatchlecture.retry.partitioning;
import io.springbatch.springbatchlecture.dbitemreader.Customer;
import io.springbatch.springbatchlecture.dbwriter.Customer2;
import lombok.RequiredArgsConstructor;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.core.partition.support.Partitioner;
import org.springframework.batch.core.partition.support.SimplePartitioner;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.database.JdbcPagingItemReader;
import org.springframework.batch.item.database.Order;
import org.springframework.batch.item.database.builder.JdbcBatchItemWriterBuilder;
import org.springframework.batch.item.database.builder.JdbcPagingItemReaderBuilder;
import org.springframework.batch.item.database.builder.JpaPagingItemReaderBuilder;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.task.SimpleAsyncTaskExecutor;
import javax.persistence.EntityManagerFactory;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.concurrent.atomic.AtomicLong;
@Configuration
@RequiredArgsConstructor
public class SimpleTestConfig {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final EntityManagerFactory emf;
private final DataSource dataSource;
private AtomicLong myId = new AtomicLong();
@Bean
public Job batchJob200() {
return jobBuilderFactory.get("partitioningJob")
.incrementer(new RunIdIncrementer())
.start(slaveStep())
.build();
}
@Bean
public Step slaveStep() {
return stepBuilderFactory.get("slaveStepMaster")
.<Customer, Customer2>chunk(1000)
// .reader(pagingItemReader())
.reader(batchReader())
.writer(batchWriter())
.processor(batchProcessor())
.build();
}
@Bean
@StepScope
public ItemProcessor<? super Customer, ? extends Customer2> batchProcessor() {
System.out.println("itemProcessor Here");
return (ItemProcessor<Customer, Customer2>) item -> Customer2.builder()
.id(myId.incrementAndGet())
.birthDate(item.getBirthDate())
.firstName(item.getFirstName())
.lastName(item.getLastName())
.build();
}
@Bean
@StepScope
public ItemWriter<? super Customer2> batchWriter() {
return new JdbcBatchItemWriterBuilder<Customer2>()
.sql("INSERT INTO Customer2(customer2_id, birth_date, first_name, last_name) values (:id, :birthDate, :firstName, :lastName)")
.dataSource(dataSource)
.beanMapped()
.build();
}
@Bean
@StepScope
public ItemReader<? extends Customer> batchReader() {
return new JpaPagingItemReaderBuilder<Customer>()
.name("partitionStepJpaReader")
.currentItemCount(0)
.entityManagerFactory(emf)
.maxItemCount(1000)
.queryString("select c from Customer c")
.build();
}
@Bean
@StepScope // 앞쪽 강의 봐야함.
public JdbcPagingItemReader<Customer> pagingItemReader() {
System.out.println("Target Created");
HashMap<String, Order> sortKeys = new HashMap<>();
sortKeys.put("customer_id", Order.ASCENDING);
return new JdbcPagingItemReaderBuilder<Customer>()
.name("pagingBuilder")
.dataSource(dataSource)
.fetchSize(1000)
.beanRowMapper(Customer.class)
.selectClause("customer_id, first_name, last_name, birth_date")
.fromClause("from customer")
// .whereClause("where customer_id >= " + minValue + " and customer_id <= " + maxValue)
.sortKeys(sortKeys)
.build();
}
@Bean
public Partitioner partitioner() {
SimplePartitioner simplePartitioner = new SimplePartitioner();
simplePartitioner.partition(4);
return simplePartitioner;
}
}
답변 1
2
정수원
지식공유자
네
원인은 잘 파악하신게 맞습니다.
말씀하신 것 처럼 open() 메서드는 ItemStream 에서 정의한 메서드입니다.
그런데 JpaPagingItemReader 를 생성하는 구문에서 리턴 타입이 ItemReader 로 되어 있습니다.
@Bean
@StepScope
public ItemReader<? extends Customer> batchReader() {
return new JpaPagingItemReaderBuilder<Customer>()
.name("partitionStepJpaReader")
.currentItemCount(0)
.entityManagerFactory(emf)
.maxItemCount(1000)
.queryString("select c from Customer c")
.build();
}
즉 ItemStream 타입은 빠져 있습니다.
그렇기 때문에 @StepScope 에 의해서 Proxy 로 생성된 객체가 실행 시점에 실제 타겟빈을 찾아 호출하게 되면 타겟빈이 ItemStream 타입으로 구현되어 있는지 체크하고 open() 메소드를 실행하게 되는데 타겟빈이 ItemReader 타입의 객체로만 생성되었기 때문에 아래 구문이 실행되지 못해서 결론적으로 EntityManager 가 생성되지 못한 것입니다.
@Override
protected void doOpen() throws Exception {
super.doOpen();
entityManager = entityManagerFactory.createEntityManager(jpaPropertyMap);
if (entityManager == null) {
throw new DataAccessResourceFailureException("Unable to obtain an EntityManager");
}
// set entityManager to queryProvider, so it participates
// in JpaPagingItemReader's managed transaction
if (queryProvider != null) {
queryProvider.setEntityManager(entityManager);
}
}
그래서 JpaPagingItemReader 를 생성하는 메서드의 리턴타입을 ItemReader 와 ItemStream 을 동시에 구현한 타입으로 리턴하시면 됩니다.
@Bean
@StepScope
public ItemStreamReader<? extends Customer> batchReader() {
return new JpaPagingItemReaderBuilder<Customer>()
.name("partitionStepJpaReader")
.currentItemCount(0)
.entityManagerFactory(emf)
.maxItemCount(1000)
.queryString("select c from Customer c")
.build();
}
그리고 스프링 배치에서 다형성 관점에서 객체를 생성할 필요가 크지 않다면 리턴타입은 구현 클래스 타입으로 해도 나쁘지 않을 것 같습니다.
@Bean
@StepScope
public JpaPagingItemReader<? extends Customer> batchReader() {
return new JpaPagingItemReaderBuilder<Customer>()
.....
.build();
}
저도 같은 문제에 봉착했었는데 이런 원리였군요!!!