인프런 커뮤니티 질문&답변
작성한 질문수

크롤링한 데이터에서 다시 크롤링할 때 발생하는 에러
해결된 질문
작성
·
467

답변 2
1
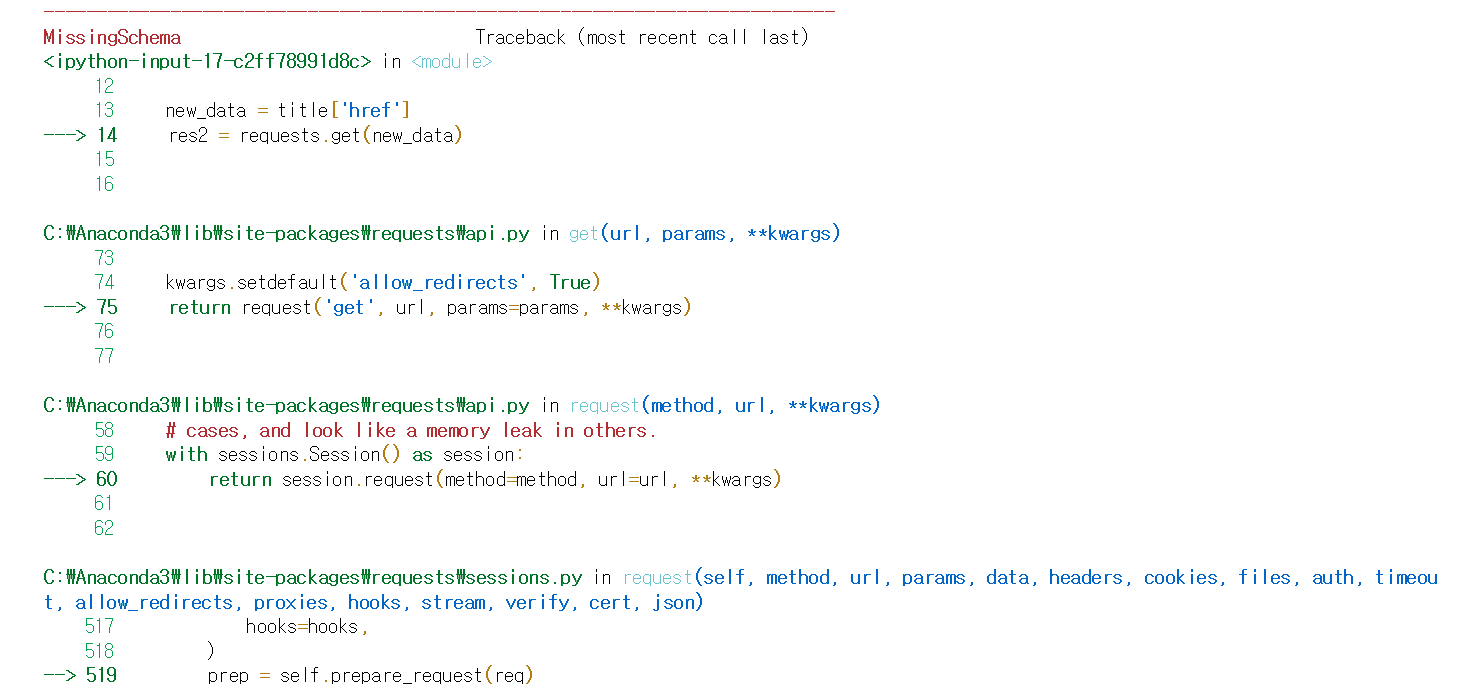
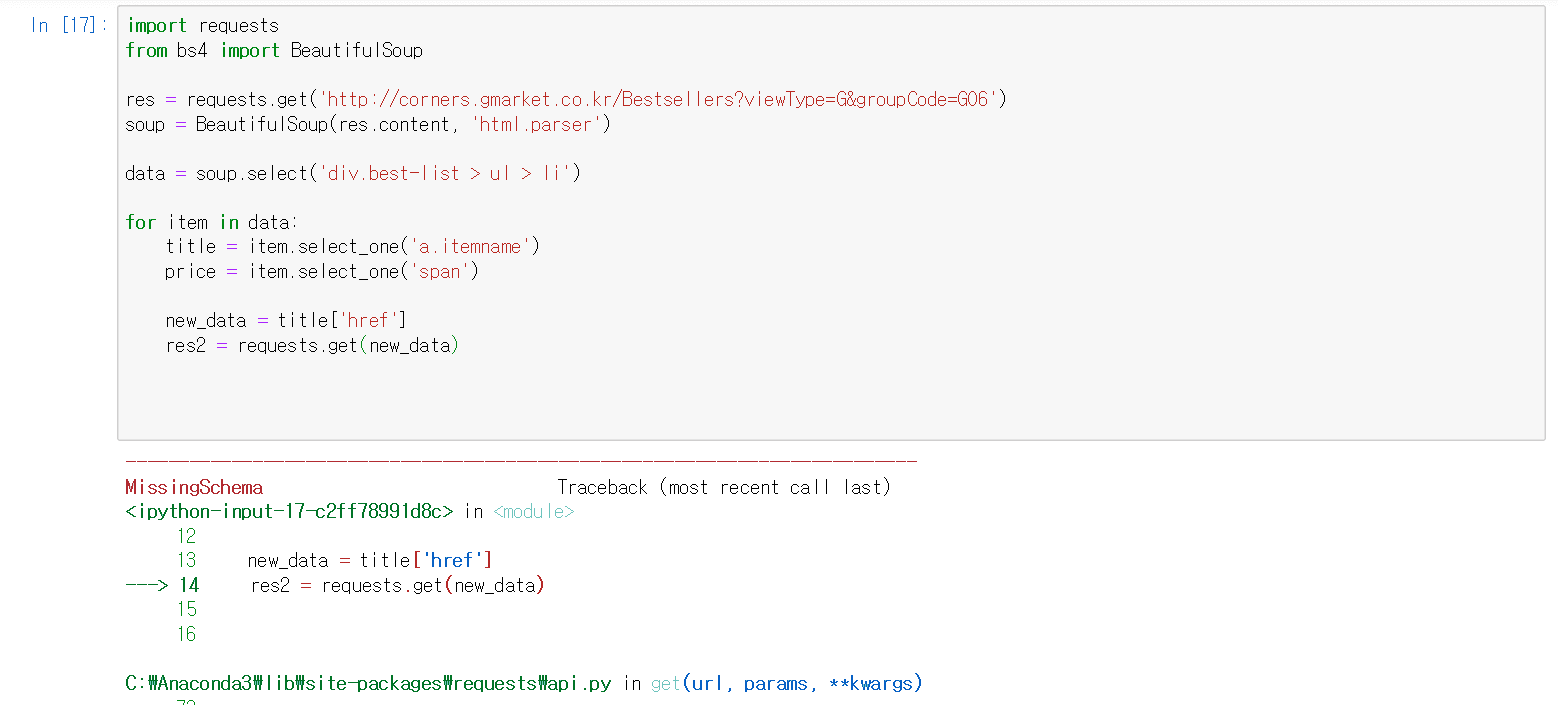
안녕하세요. 우선 일부 상품 정보 태그가 다르게 들어가면서, title['herf'] 가 없는 부분들이 있어서 그렇습니다. 큰 맥락에서는 아직까지는 괜찮고, 코드 연습으로는 좋은 것 같기는 합니다. 추후에 이 사이트도 접고 제가 직접 만든 사이트로 크롤링 코드를 작성해보는 것으로 해야할지도 모르겠네요. 결국 모든 크롤링을 제가 작성한 페이지로 해야하나 고민이 되네요.
우선 제가 접근해가는 방식을 설명드리면, 프로그래밍을 학습하시는데 조금더 도움이 되실 것 같아 다음과 같이 설명을 드립니다.
일단은 에러를 보시면요.
에러에 보시면 res2 = requests.get(new_data) 이 부분이 에러라고 나오고 있고, invalid URL 이라고 나오는 것으로 보여져요.
new_data 가 title['href'] 인데 title['href'] 가 잘못된 값으로 보여요.
그러면 print(title['href']) 로 출력을 해봤고요.
일부 링크값이 안들어가 있는 것을 확인했습니다.
그래서, 저희가 익힌 정규표현식을 써서, title['href'] 가 http:// 로 시작하는 경우만 찾아서, 해당 경우에서만 res2 = requests.get(title['href']) 를 해주었습니다. 다음 코드를 참고해보시면 좋을 것 같습니다. 좋은 참고가 되었으면 좋겠습니다. 감사합니다.
import requests
import re
from bs4 import BeautifulSoup
link_re = re.compile('^http://')
res = requests.get('http://corners.gmarket.co.kr/Bestsellers?viewType=G&groupCode=G07')
soup = BeautifulSoup(res.content, 'html.parser')
bestlist = soup.select('div.best-list > ul > li')
for index, product in enumerate(bestlist):
title = product.select_one('a.itemname')
price = product.select_one('div.o-price')
if link_re.match(title['href']):
res2 = requests.get(title['href'])
0