인프런 커뮤니티 질문&답변
작성한 질문수

네이버 지도 크롤링 관련 질문
해결된 질문
작성
·
1.4K
1
안녕하세요 선생님
만들어주신 크롤링 강의 신청해서 잘 수강하고 있는 한 학생입니다
다름이 아니라, 업무에서 '생생정보통 맛집'에 대한 네이버지도 크롤링이 필요하여
셀레니움으로 메뉴까지 크롤링하는 방법에 도전하던 중
커뮤니티에 json으로 크롤링하는 방법을 올려주신 분이 있어서 활용해보았습니다
다만, json의 경우 '생생정보통맛집 서울'이라는 쿼리로는 제대로 값이 생성이 안되더라구요
아무래도 이게 키워드라기보단 필터라서 그런 것 같긴한데 api 주소로 요청해서 받아오는데 필터를 아무리 검색해도
찾아볼 수가 없더라구요.. 유튜브때처럼 api에 해당하는 필터 값을 알려주는 사이트가 있으면 좋으련만...
고민해봤는데, 위도경도가 현재 컴퓨터 위치를 자동으로 보내서 탐색하기 때문이라고 생각합니다
이런건 혹시 어떤 값으로 바꿔줄 수 있을지.. 아니면 제대로 크롤링 될 수 있도록 해보고싶은데
힌트나.. 방법을 얻을 수 있을까요? 감사합니다
import requests
import urllib, openpyxl, time
wb = openpyxl.Workbook()
ws = wb.active
ws.append(['상호명', '주소', '연락처', '메뉴'])
with open('C:/program_list.txt', 'r', encoding='utf-8') as tf:
keywords = tf.readlines()
for keyword in keywords:
keyword = keyword.strip().replace('\t', '')
print(keyword, '에 나온 맛집입니다.\n\n')
url_keyword = urllib.parse.quote(keyword)
try:
for i in range(1, 20):
print('\n', i,'페이지입니다.\n')
response = requests.get(f'https://map.naver.com/v5/api/search?caller=pcweb&query={url_keyword}&type=all&page={i}&displayCount=40&lang=ko', headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'}).json()
numbers = response['result']['place']['list']
for i in range(0,len(numbers)):
name = response['result']['place']['list'][i]['name']
address = response['result']['place']['list'][i]['roadAddress']
tel = response['result']['place']['list'][i]['telDisplay']
menuinfo = response['result']['place']['list'][i]['menuInfo']
print(name, address, tel, menuinfo)
ws.append([name, address, tel, menuinfo])
time.sleep(1)
except:
print('끝났습니다.')
wb.save(f'{target_word}결과.xlsx')
tf.close()답변 1
1
스타트코딩
지식공유자
안녕하세요~!
코딩을 누구보다 쉽게 알려주는 스타트코딩입니다.
제가 해당 코드를 돌려봤을 때는, request 요청할 때 오류가 발생합니다.
응답 코드가 503에러로 데이터를 받아오지 못하고 있습니다.
postman 프로그램으로 테스트 해봤을 때는 제대로 데이터를 받아오네요.
request 헤더를 상세하게 써주면 가져올 것 같아서 시도해 봤고, 정상적으로 데이터를 가져오는 것을 확인했습니다.
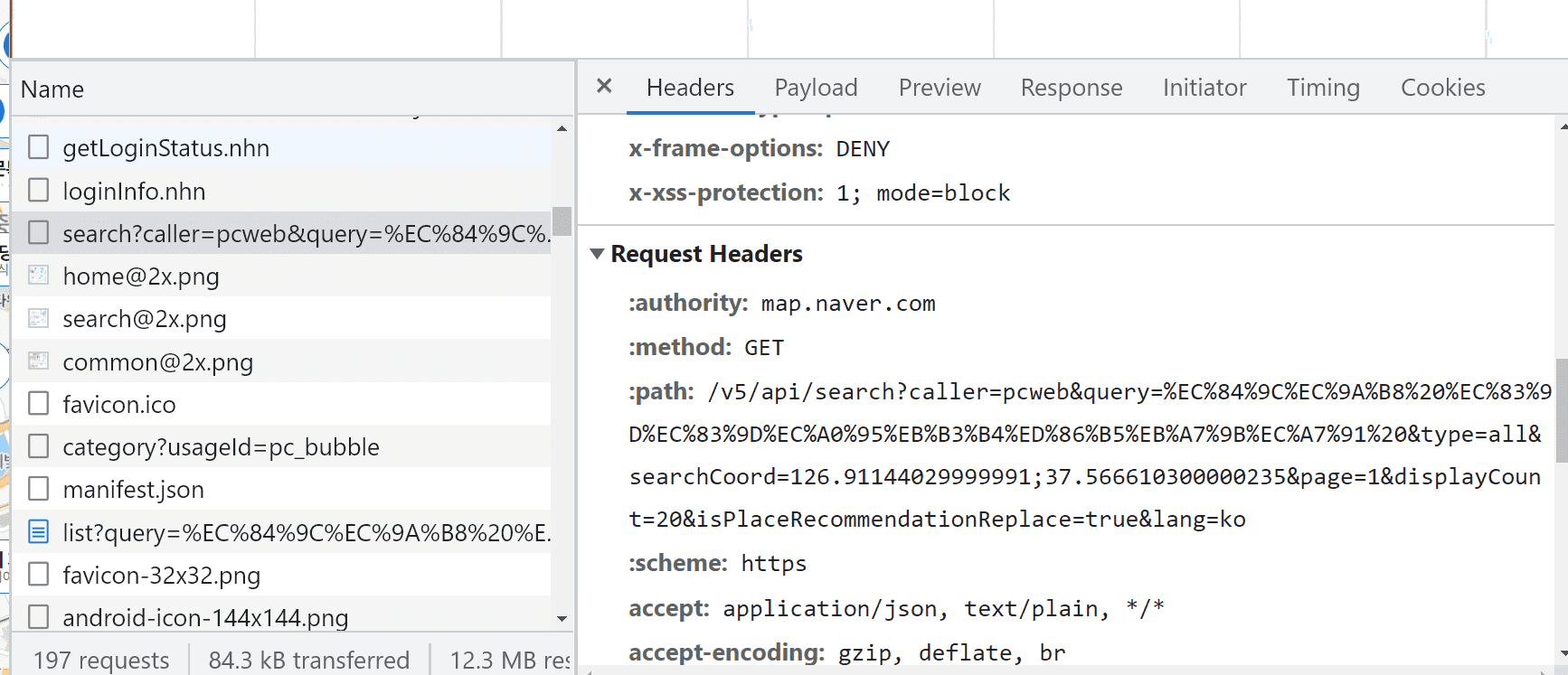
import requests
import json
header = {
'authority': 'map.naver.com',
'method': 'GET',
'scheme': 'https',
'accept': 'application/json, text/plain, */*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'ko-KR,ko;q=0.8,en-US;q=0.6,en;q=0.4',
'cache-control': 'no-cache',
'content-type': 'application/json',
'cookie': 'NNB=ZHREYBKYJGZWA; ASID=7c6f74d40000017a324f783a0000004f; NV_WETR_LOCATION_RGN_M="MDkxNDAxMDQ="; _ga=GA1.1.843260892.1631082249; _ga_8P4PY65YZ2=GS1.1.1631546146.1.0.1631546150.0; NV_WETR_LAST_ACCESS_RGN_M="MDkxNDAxMDQ="; MM_NEW=1; NFS=2; NaverSuggestUse=use%26unuse; _gcl_au=1.1.684846510.1636646068; nx_ssl=2; page_uid=4bf320b5-0774-4667-9eca-95099ebb77e8',
'expires': 'Sat, 01 Jan 2000 00:00:00 GMT',
'pragma': 'no-cache',
'referer': 'https://map.naver.com/',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="97", "Chromium";v="97"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': "Windows",
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36'
}
url = "https://map.naver.com/v5/api/search?caller=pcweb&query=%EC%84%9C%EC%9A%B8%20%EC%83%9D%EC%83%9D%EC%A0%95%EB%B3%B4%ED%86%B5%EB%A7%9B%EC%A7%91%20&type=all&page=1&displayCount=40&lang=ko"
response = requests.get(url, headers=header)
result = json.loads(response.content)
numbers = result['result']['place']['list']
for i in range(0,len(numbers)):
name = result['result']['place']['list'][i]['name']
address = result['result']['place']['list'][i]['roadAddress']
tel = result['result']['place']['list'][i]['telDisplay']
menuinfo = result['result']['place']['list'][i]['menuInfo']
print(name, address, tel, menuinfo)
바쁘실텐데 답변 너무 감사합니다 선생님~ 하나만 더 질문드리겠습니다!