인프런 커뮤니티 질문&답변
작성한 질문수

batchSize 원리에 대해서 알고 싶습니다
작성
·
1.9K
0
안녕하세요 영한님 @BatchSize를 이용하여 최적화를 하다가 문득 깊은 내용을 알고싶어서 질문을 드립니다.
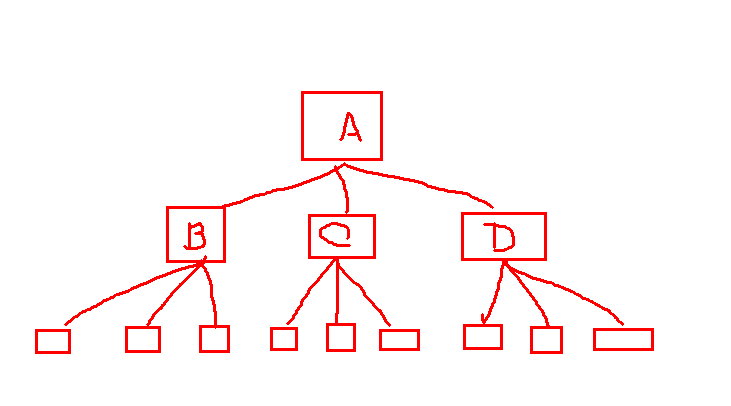
폴더 안의 폴더를 만드는 구조인데요 다음의 상하 관계를 가진 폴더가 총 13개 있습니다. 이 13개의 폴더 정보를 받아 위의 그림의 구조로 저장을 하고 싶었습니다 .
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
public class Folder {
@Id @GeneratedValue(strategy = GenerationType.SEQUENCE)
@Column(name = "FOLDER_ID")
private Long id;
private String name;
// 부모
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "PARENT_ID")
private Folder parent;
// 자식
@BatchSize(size = 900)
@OneToMany(mappedBy = "parent")
private List<Folder> children;
@Builder
private Folder(String name, Folder parent) {
this.name = name;
this.parent = parent;
}
}
그래서 Folder라는 엔티티를 self reference하도록 구성을 했구요
@BeforeEach
public void setUp() throws Exception {
Folder aFolder = Folder.builder()
.name("A")
.build();
Folder bFolder = Folder.builder()
.name("B")
.parent(aFolder)
.build();
Folder bChild1 = Folder.builder()
.name("BChild1")
.parent(bFolder)
.build();
Folder bChild2 = Folder.builder()
.name("BChild2")
.parent(bFolder)
.build();
Folder bChild3 = Folder.builder()
.name("BChild3")
.parent(bFolder)
.build();
Folder cFolder = Folder.builder()
.name("C")
.parent(aFolder)
.build();
Folder cChild1 = Folder.builder()
.name("CChild1")
.parent(cFolder)
.build();
Folder cChild2 = Folder.builder()
.name("CChild2")
.parent(cFolder)
.build();
Folder cChild3 = Folder.builder()
.name("CChild3")
.parent(cFolder)
.build();
Folder dFolder = Folder.builder()
.name("D")
.parent(aFolder)
.build();
Folder dChild1 = Folder.builder()
.name("DChild1")
.parent(dFolder)
.build();
Folder dChild2 = Folder.builder()
.name("DChild2")
.parent(dFolder)
.build();
Folder dChild3 = Folder.builder()
.name("DChild3")
.parent(dFolder)
.build();
folderRepository.saveAll(Arrays.asList(aFolder, bFolder, cFolder, dFolder, bChild1, bChild2,
bChild3, cChild1, cChild2, cChild3, dChild1, dChild2, dChild3));
em.flush();
em.clear();
}
이렇게 저장을 한 후
@Test
@DisplayName("bfs 알고리즘 적용 테스트")
@Transactional
@Commit
public void bfsTest() throws Exception {
// given
Queue<Folder> queue = new LinkedList<>();
Folder deleteFolder = folderRepository.findById(1L).get();
queue.offer(deleteFolder);
List<Folder> tempFolders = new ArrayList<>();
tempFolders.add(deleteFolder);
int i = 0;
// when
while(!queue.isEmpty()) {
System.out.println("i = " + i);
Folder pollFolder = queue.poll();
List<Folder> folders = pollFolder.getChildren();
for (Folder folder : folders) {
queue.offer(folder);
}
tempFolders.addAll(folders);
i++;
}
// then
Collections.reverse(tempFolders);
folderRepository.deleteAll(tempFolders);
em.flush();
}
위의 코드처럼 테스트 코드를 짯습니다
그러니 select 쿼리가 많이 줄어든것을 확인할 수 있었습니다.
2022-01-13 23:25:04.471 DEBUG 21588 --- [ main] org.hibernate.SQL :
select
folder0_.folder_id as folder_i1_1_0_,
folder0_.name as name2_1_0_,
folder0_.parent_id as parent_i3_1_0_
from
folder folder0_
where
folder0_.folder_id=?
2022-01-13 23:25:04.492 DEBUG 21588 --- [ main] org.hibernate.SQL :
select
children0_.parent_id as parent_i3_1_1_,
children0_.folder_id as folder_i1_1_1_,
children0_.folder_id as folder_i1_1_0_,
children0_.name as name2_1_0_,
children0_.parent_id as parent_i3_1_0_
from
folder children0_
where
children0_.parent_id=?
2022-01-13 23:25:04.498 DEBUG 21588 --- [ main] org.hibernate.SQL :
select
children0_.parent_id as parent_i3_1_1_,
children0_.folder_id as folder_i1_1_1_,
children0_.folder_id as folder_i1_1_0_,
children0_.name as name2_1_0_,
children0_.parent_id as parent_i3_1_0_
from
folder children0_
where
children0_.parent_id in (
?, ?, ?
)
2022-01-13 23:25:04.501 DEBUG 21588 --- [ main] org.hibernate.SQL :
select
children0_.parent_id as parent_i3_1_1_,
children0_.folder_id as folder_i1_1_1_,
children0_.folder_id as folder_i1_1_0_,
children0_.name as name2_1_0_,
children0_.parent_id as parent_i3_1_0_
from
folder children0_
where
children0_.parent_id in (
?, ?, ?, ?, ?, ?, ?, ?, ?
)
총 이렇게 4개의 쿼리가 나갔는데요
서론이 길었습니다 선생님 제가 질문할 것은 이겁니다
@BatchSize를 설정하면 하이버네이트는 어떤 알고리즘으로
저 in절의 아이디 값들을 넣는 것일까요>
자료를 찾아봐도 나오는데가 없었고
저스스로 고민을 했을 때는
<1번>
첫번째 select 쿼리가 나갔을 때 A폴더(id = 1)가 영속화 된다.
<2번>
2번째 select 쿼리가 나갔을 때
B,C,D 폴더 즉 id가 2,3,4인 폴더들이 영속화가 된다.
-> 따라서 3번째 select 쿼리에서 in절의 id들은 이 2,3,4가 되는 것이다.
(여기서의 의문점 그럼 앞서 영속화된 A폴더의 id = 1은 안 집어 넣는 알고리즘은 또 뭘까)
이렇게 생각했는데 과연 맞는지 궁금합니다
답변 1
0
안녕하세요. fecorp님
단순하게 부모 테이블, 자식 테이블라고 하겠습니다.
처음 데이터를 조회할 때 부모 테이블의 데이터가 10개 조회되면, 연관된 자식을 조회할 때 부모 id 10개를 알고 있으니 그 부모 id 10개를 분할해서 자식을 조회하는 방식입니다.
추가로 다음도 읽어보시면 도움이 되실거에요.
https://www.inflearn.com/questions/34469
https://www.inflearn.com/questions/247048
감사합니다.