인프런 커뮤니티 질문&답변
작성한 질문수

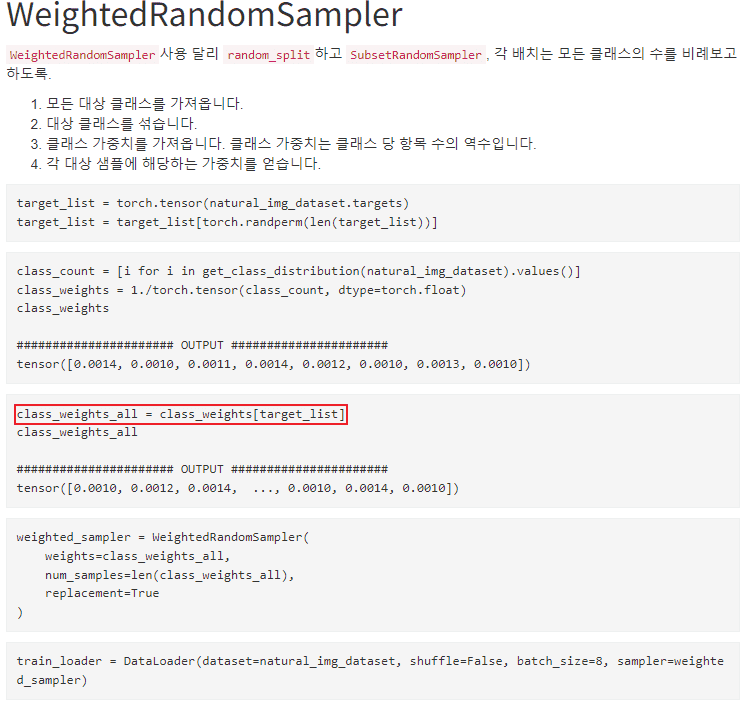
patchdata.py에서 make_weights 함수 질문이 있습니다
작성
·
210
0
안녕하세요
구현 부분 보고 있는데, 궁금한 점이 있습니다
1. make_weights 함수를 구할 때 클래스 갯수만큼 반복문을 통해서 단순하게 1/카운팅 갯수로 하는데,
저는 데이터셋 전체 갯수를 고려해서 넣어줘야 되지 않나도 생각이 들어서요. (둘 모두 클래스 많고 적음은 표현이 될 것 같긴 합니다. 다만 후자가 좀 더 정확하지 않을까 해서요)
2. 또 드는 생각이 Pytorch API에서 저렇게 계산해서 넣어줘야만 되는건지 궁금합니다
3. 그리고 직접 구하는 것이 아닌 Pytorch에서 충분히 내부적으로 처리해줄 수 있을 것 같은데, 그건 또 아니네요
감사합니다
답변 2
1
안녕하세요. 유영재님!
현재 가지고 오신 외부 코드의 메카니즘은 우리 코드와 동일합니다.
우리 코드에서 make_weights에 해당하는 부분이 외부코드의 class_count 와 class_weights 이구요.
이 부분도 작성자가 for문을 이용한 것이구요. 가중치를 구하는 부분은 저자마다 다를 수 있는데 데이터셋 전체 개수도 고려해서 계산할 수도 있지만 클래스당 데이터 개수로만 계산이 가능하기도 합니다. 여기서는 후자를 택한 것이구요.
make_weights를 보시면 각 클래스의 가중 확률의 합이 항상 1입니다. 즉, 모든 클래스의 가중 확률의 합이 1이 되고 이는 클래스를 하나의 변수로 봤을 때 뽑을 확률이 같음을 의미합니다. 사실 모든 클래스의 가중 확률의 합의 합이 1이 되는 것이 수학적으로 이상적일 수 있으나 전체 확률이 1에 되지 않더라도 샘플링에는 문제가 없습니다. 그리고 말씀 하신대로 라벨 순서를 유지 시켜줘야 합니다. 이 부분은 오류가 있네요. 수정할께요!
질문 감사드립니다!
0
또 궁금한 점이
아래는 구글 어느 한 블로그를 퍼온건데, 제 생각과 동일한 부분이 있기는 합니다
클래스에 따른 가중치를 구한 다음에 이를 전체 Label에 적용할 때 Label에 대한 순서를 유지해줘야 되지 않나요?
현재 코드는 해당 리스트만큼 구해서 바로 extend 시키는 코드인 것 같아서요