인프런 커뮤니티 질문&답변
작성한 질문수

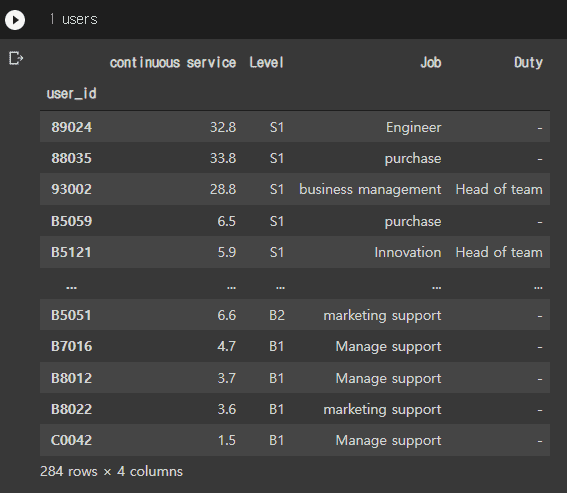
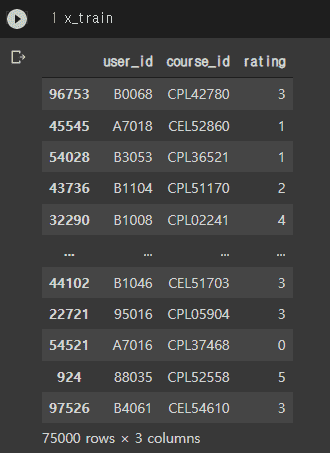
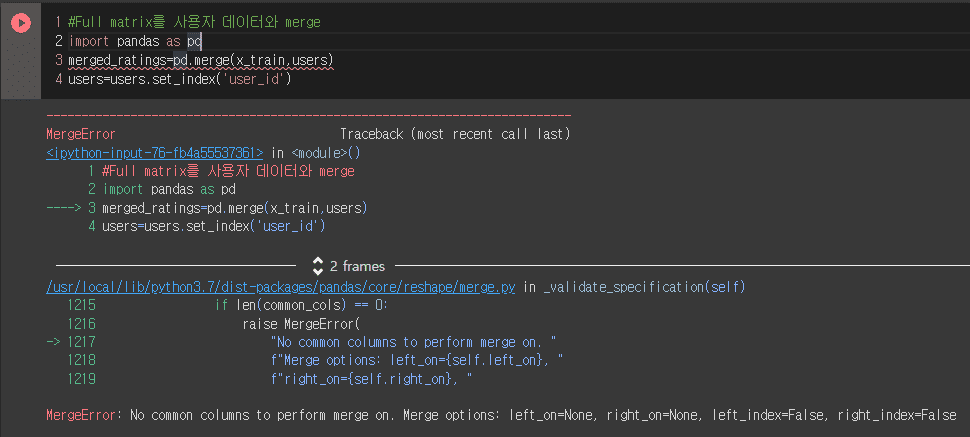
Full matrix를 사용자 데이터와 merge 하는 것과 gender기준 추천 모델에서 실제 추천을 받는 방법 질문 입니다.
해결된 질문
작성
·
320
답변 3
1
안녕하세요. 학습자님 !
열심히 강의를 시청하시면서 학습해주시는 모습 감동입니다 :)
첫 번째 질문의 경우)
user 데이터와 x_train 데이터를 user_id기준으로 merge 시키려고 하신 것 같습니다.
하지만 x_train의 경우 user_id가 컬럼이 아닌 인덱스로 지정되어 있네요.
그래서 x_train = x_train.reset_index()를 통해서 인덱스 값을 컬럼으로 이동시키는 작업 후에
pd.merge(user,x_train,on='user_id') 이렇게 진행하시면 되겠습니다.
두 번째 질문의 경우)
def cf_gender(user_id,movie_id):
# x_train으로 만든 pivot 테이블에 movie_id가 있으면 진행, 없으면 기본값 3.0 예측치로 간주
if movie_id in rating_matrix.columns:
# 예측 대상자의 성별을 users에서 구해온다.
gender = users.loc[user_id]['sex']
# 예측 대상 영화가 해당 성별의 평균을 가지고 있는지 확인
# 간혹 사용자가 적은 영화의 경우 남성 혹은 여성 사용자 중에서 영화 평가한 사람이 없으면 없는 영화라 간주할 수 있음
if gender in g_mean[movie_id].index:
gender_rating = g_mean[movie_id][gender]
else:
gender_rating = 3.0
else:
gender_rating = 3.0
return gender_rating
score(cf_gender)위 score는 단순 모델의 성능을 검증하기 위함 이었습니다.
그래서 실제로 모델을 활용하실 때는 상황에 따라 다르겠지만,
전체 유저에게 모든 영화에 대한 예측 평점값을 계산한다고 가정했을 때
user 한명당 위 모듈을 활용하셔서 모든 영화에 대한 평점을 계산하시고
그 평점 값중 가장 높은 것을 선택해서 리턴해주는 방식을 취할 수 있습니다.
모델 활용에 대해서는 어느정도 각자 도메인의 상황이나 아이디어에 따라 달라질 수 있기 때문에,
이번 강의에서는 단순 예측 평점, 즉 개인에 대한 각 영화에 대한 선호도만 실습한 것입니다 :)
혹시나 더 궁금하신 점 있으시다면 편하게 댓글 남겨주세요!
학습자님의 성공적인 학습을 기원합니다.
감사합니다.
-거친코딩 드림-
안녕하세요!
데이터 머지는 성공적으로 잘 하셨네요!
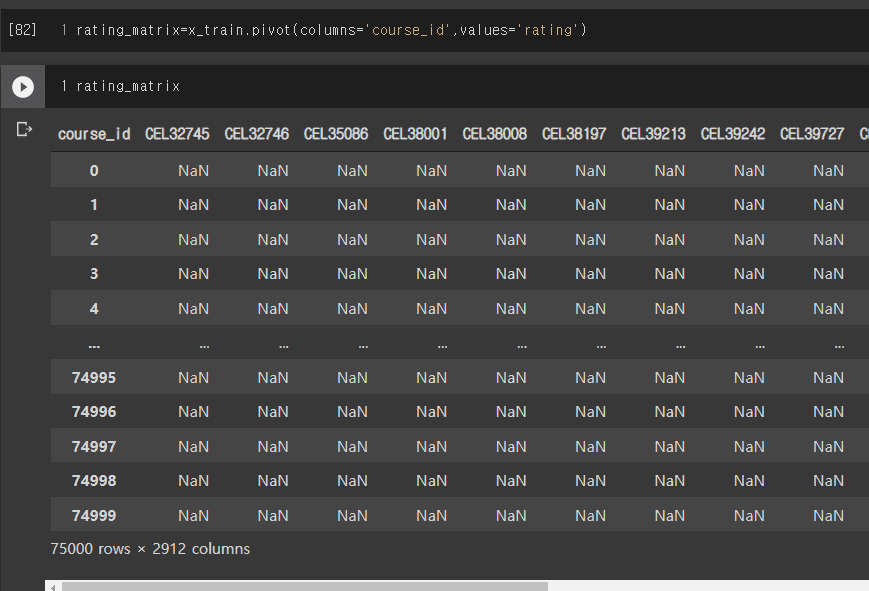
Pivot을 보니까 이미 x_train에다가 user_id로 인덱스를 지정한 상황에서 pivot index를 user_id로 지정을 또 하셔서 그런 것 같습니다.
제가 봤을 때 x_train은 set_index 처리 안하셔도 될것같습니다.
한번 해보시구 댓글 부탁드려요😊
0
와 정말 대단하십니다..!
Raw data를 정제했더니 바로 되었습니다!
감사합니다!!
추가적으로 위에 여쭤본 질 문 중 성별 기준으로 추천하는 모델의 성능을 검증하기 위한 코드가 있었습니다.
이 부분에서 성별에 따른 추천 혹은 성별 & 직업에 따른 추천등을 적용해 보고 싶은데
구체적으로 어떠한 방법이 있을지 여쭤봐도 될까요?
<이전 질문의 답변>
위 score는 단순 모델의 성능을 검증하기 위함 이었습니다.
그래서 실제로 모델을 활용하실 때는 상황에 따라 다르겠지만,
전체 유저에게 모든 영화에 대한 예측 평점값을 계산한다고 가정했을 때
user 한명당 위 모듈을 활용하셔서 모든 영화에 대한 평점을 계산하시고
그 평점 값중 가장 높은 것을 선택해서 리턴해주는 방식을 취할 수 있습니다.
모델 활용에 대해서는 어느정도 각자 도메인의 상황이나 아이디어에 따라 달라질 수 있기 때문에,
이번 강의에서는 단순 예측 평점, 즉 개인에 대한 각 영화에 대한 선호도만 실습한 것입니다 :)
혹시나 더 궁금하신 점 있으시다면 편하게 댓글 남겨주세요!
학습자님의 성공적인 학습을 기원합니다.
감사합니다.
-거친코딩 드림-
안녕하세요.
해결되셨다니 다행입니다.!
말씀해주신대로 성별 그리고 성별 & 직업 이런식으로 추천을 한다고 했을 경우에는
제가 구체적으로 코드를 짜드릴 수는 없지만 이전 질문 답변을 드린대로 코드 로직을 짜시면 되는데,
한 가지 주의할 점은 많은 조건을 동시에 (and)조건으로 걸다보면 샘플에 대한 파이가 작아질 수 있기 때문에 성능 저하를 불러일으킬 수 있습니다.
그래서 각 도메인 지식 혹은 비즈니스적으로 중요하다고 고려되는 변수 세그멘트로만 나누셔서 진행하면 좋을 것 같네요~!
만약 모수가 크다면 상관이 없습니다:)
감사합니다.
-거친코딩 드림-
0
학습자님 안녕하세요.!
Pivot은 x_train = x_train.pivot(index='user_id', columns='course_id',values='rating')
그대로 하시구
위에 x_train = x_train.set_index('user_id')를 제거해주시면 되겠습니다!
해보시구 리뷰 부탁드리겠습니다:)
감사합니다.
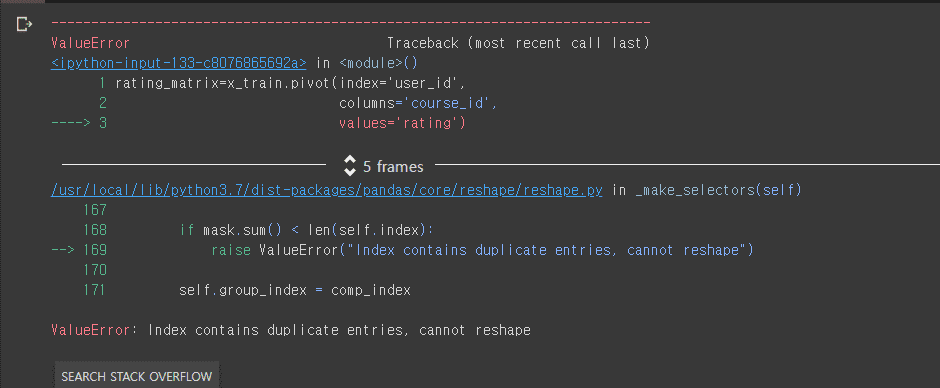
강사님 지속적인 질문에도 친절하게 답변해 주셔서 감사드립니다.
말씀해 주신 내용으로 수정하여 merge를 완료 하였으나
x_train을 피벗하는 과정에 오류가 발생하였습니다...
여러 방법으로 애러사항을 조치하였지만 역부족이라 부득이하게 여쭤봅니다..