인프런 커뮤니티 질문&답변
작성한 질문수

결정계수 함수 관련 질문 드립니다.
작성
·
2.2K
0
안녕하세요! 강사님! 교재로 공부하다가 인강도 있다고 들어서 요번에 수강하게 된 학생입니다!
다름이 아니라 공부하면서 랜덤포레스트 회귀 모델을 한번 설계해보고 있는데요.
모델을 학습하고 예측한 후에 평가하는 과정에서 R2(결정계수)가 너무 큰 음수가 나와서 이게 무엇을
의미하는지 또 어떠한 점들이 잘못됐는지 궁금하여 이렇게 질문을 남깁니다.
RMSE와 R2 결과 사진:


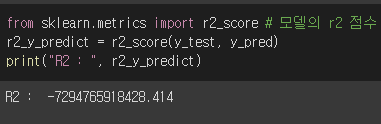
궁금한 점으로는
1. 회귀 모델에서 R2가 매우 큰 음수로 나온다는 것은 무슨 의미인가요?
2. 사이킷런에서 랜덤포레스트회귀 관련 함수중에 score함수도 R2를 계산해주는 함수인거 같던데 metrics의 r2_score 함수와 같은 기능을 하는건가요? 같다는 전제하에 두 함수를 사용해봤는데 위 사진처럼 값이 너무 다르게 나와서 무엇이 잘 못 됐는지 궁금합니다.. ㅠㅠ
3. 마지막으로 랜덤포레스트 회귀 score 함수를 잘 못 사용한거라면 혹시 입력한 매개 변수를 잘못 입력한건지 궁금합니다.. 다음 사진과 같이 X_test, y_test로 설정한것이 맞게 한건가요..?
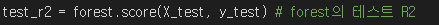
항상 좋은 강의 들려주셔서 감사합니다..! 답변 부탁 드립니다 ㅠㅠ!!
답변 1
0
안녕하십니까,
1. 일반적으로 R2 score는 0 ~ 1 사이값이 나옵니다. 1에 가까울수록 좋은 성능입니다.
사이킷런에서 R2 Score는 - 로 나오는 경우는 흔하지 않게 bug에 가까운것 같습니다. 아마 테스트 데이터 세트가 아주 작은 경우에 이러한 현상이 나오곤 하는 것 같습니다. 테스트 데이터 세트의 크기를 더 증가시켜보시고 다시한번 R2 Score를 확인해 보시기 바랍니다.
2. 사이킷런의 초기 버전에서 개별 model 클래스(즉 Estimator)의 score()메소드가 있었습니다. score()메소드가 반환하는 것은 개별 model 클래스별로 달라지는데 Classification model의 경우에는 정확도를, Regression model의 경우에는 r2 score를 반환합니다. 사이킷런은 더 이상 개별 model 클래스의 score()메소드 사용을 권장하지 않으며(Deprecated 된 걸로 알고 있습니다), 다양한 metric 기반의 score 함수 사용을 권장합니다.
r2_score()와 score()메소드가 다른 이유는, 음,,, 저도 잘 모르겠습니다만, r2_score()가 현재 테스트 데이터 세트에서 버그성 오류가 있는 것 같습니다.
3. 네, 적어주신 방식대로 적용하시면 됩니다.
감사합니다.