인프런 커뮤니티 질문&답변
작성한 질문수

[실전] 크롤링과 데이터베이스 - 크롤링 코드 작성 시작 강의 6분 58초 내용입니다
작성
·
250
0
[실전] 크롤링과 데이터베이스 - 크롤링 코드 작성 시작
강의 6분 58초 내용입니다
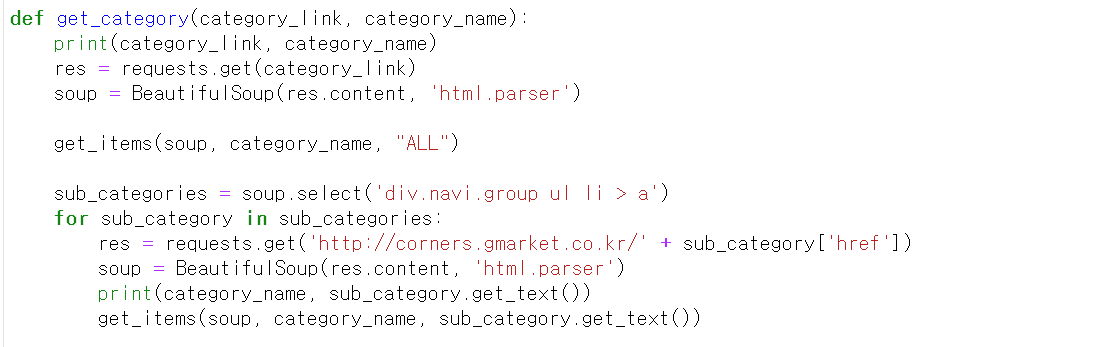
에서
실행을 할 때 오류없이 카테고리 ALL 내용은 카테고리만 출력을 하고, 그다음 카테고리들 부터는 카테고리와 서브카테고리를 잘 출력을 합니다.
다른 카테고리들(ex패션의류 신발/잡화 등)은 서브카테고리들(브랜드 여성의류 등)이 있어서
sub_categories = soup.select('div.navi.group ul li > a')
통해서 서브카테고리들을 가져올 수 있는데
ALL (메인)카테고리에서는 서브카테고리에 해당하는 내용이 없어서 크롤링을 할 때 빈값을 가져오고 그러면, 출력을 할 때(sub_category.get_text()을 사용할 때) 빈 값이니까 오류가 나야 하는거 아닌가요?
답변 3
0
[참고] 크롤링과 데이터베이스 - 크롤링 코드 작성 시작 (업데이트) 5분10초 내용입니다
G마켓 내용이 일부 변동되서인지 "sub_categories = soup.select('div.navi.group ul li a')" 부분이 작동되지 않습니다
 아직 제가 웹크롤링이 초보라서 해결할 수가 없습니다 ㅠ
아직 제가 웹크롤링이 초보라서 해결할 수가 없습니다 ㅠ
0
저도 이 질문보고, 한참 고민했네요
ALL 카테고리에는 Sub 카테고리가 없으니, 오류가 나는게
정상 아닌가 하는 질문자님과 같은 생각을했어요
그래서 코드를 실행해보니
---------------------------------------
ALL 카테고리에 대한 선택자값을 print
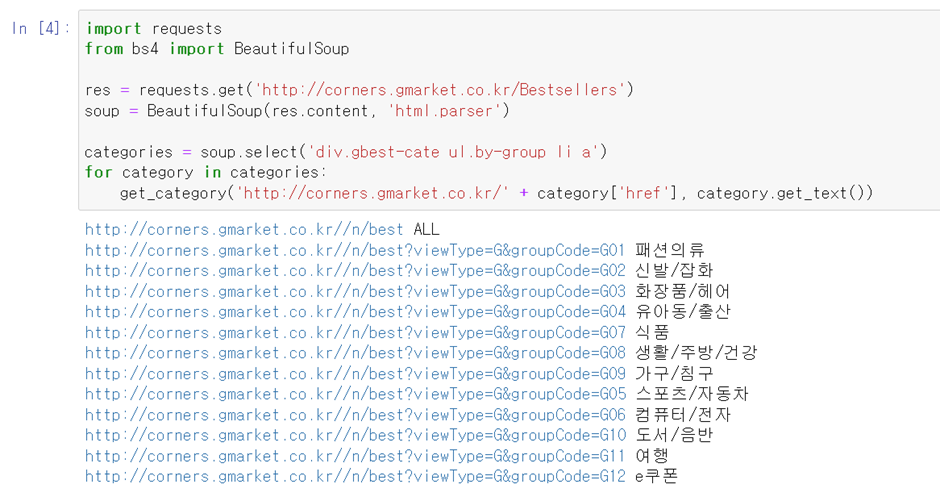
res = requests.get("http://corners.gmarket.co.kr/Bestsellers")
soup = BeautifulSoup(res.content, "html.parser")
sub_categories = soup.select("div.cate-l > div.navi.group >ul > li a ")
print(sub_categories)결과값이 "[]" 이와같이 빈리스트 더라구요
---------------------------------------
그냥 추측이건데, 빈리스트도 ,
반복문 (for)문이 가능하고
빈값에 무언가 실행히도 에러가 안나는거 같네요
print(category_link, category_name, sub_category.get_text(), "http://corners.gmarket.co.kr" + sub_category['href'])위코드가 에러가 나는게 맞지않나 싶었는데
에러가 안나네요
---------------------------------------
실험한 전체코드는 아래와같습니다
import requests
from bs4 import BeautifulSoup
# 카테고리 선택자 : div.gbest-cate > ul.by-group > li a
res = requests.get("http://corners.gmarket.co.kr/Bestsellers")
soup = BeautifulSoup(res.content, "html.parser")
sub_categories = soup.select("div.cate-l > div.navi.group >ul > li a ")
print(sub_categories)
for sub_category in sub_categories:
print(category_link, category_name, sub_category.get_text(), "http://corners.gmarket.co.kr" + sub_category['href'])
0
안녕하세요.
관련 코드는 get_category() 함수를 호출했을 때, 일어나는 작업이니까요.
get_category() 자체가 ALL 카테고리 이외의 각 메인 카테고리에 대해서만 호출을 하니, 내부에서 각 메인 카테고리에 대한 서브 카테고리 관련 정보를 가져오는데에서는 논리적으로 이슈가 없을 것 같습니다. 그래서 에러가 나지 않는 것으로 이해가 됩니다.
이해가 어려우시다면, 각 코드 사이사이에 print 구문을 넣어서 어떤 경우에 실행이 되는지를 보신다면 좀더 이해하기 쉬우실꺼예요.
vscode를 이용해서 한줄 씩 실행을 해보았는데
처음에 category_name 에 "ALL"이 할당이 되고
get_items(soup,category_name,"All")
문구를 실행한 다음에, 다음 줄인
sub_categories = soup.select('div.navi.group ul li > a')
를 실행하면 sub_categories=[] 이렇게 할당이 되어서 반복문을 실행하지 않고
get_category() 함수를 빠져나온 다음
다음 카테고리인(패션의류)로 넘어가는 것을 확인했습니다!
페이지 소스를 분석한 결과,
category_name 이 'ALL'인 경우에는 div.navi.group ul li > a 경로 자체가 존재하지 않아서
sub_categories=[] 으로 되는 것 같은데요. 그렇다면
이런 경우에는 sub_categories == None 인 것인가요?