인프런 커뮤니티 질문&답변
작성한 질문수

CNN Cifar10 VGG16으로 전이학습 시 val_accuracy가 0.1로 고정되어 나옵니다
21.05.10 16:04 작성
·
905
0
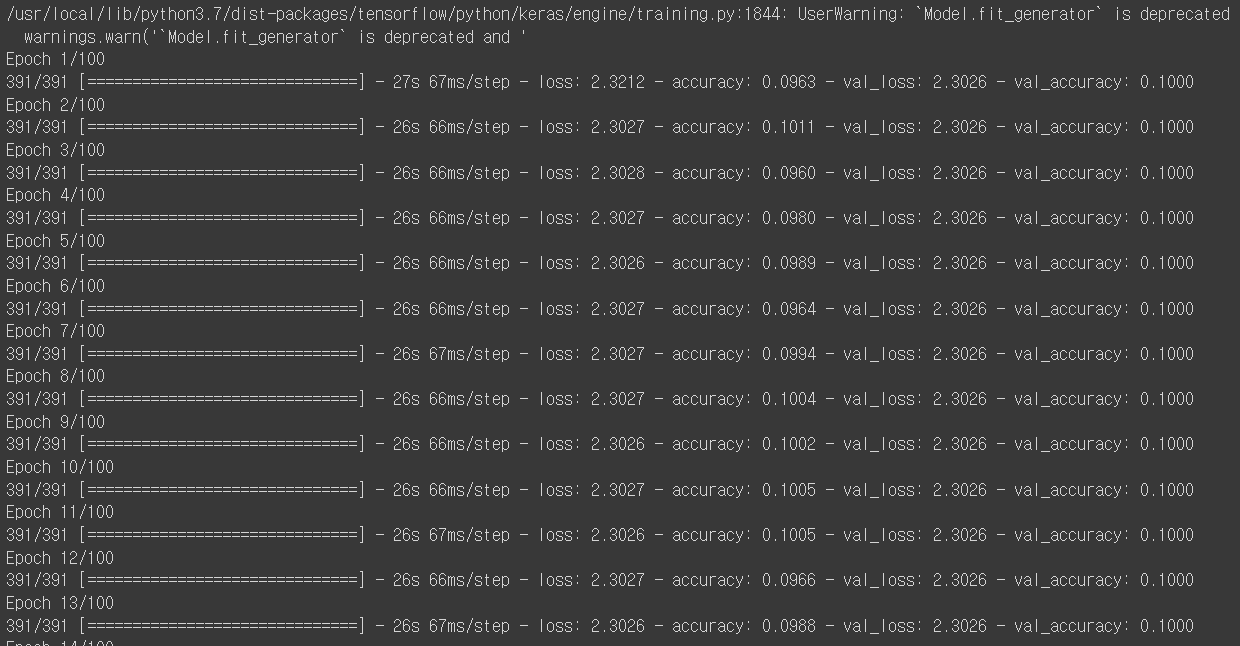
안녕하세요. CIFAR10 데이터를 가지고, VGG16으로 전이학습을 해보려고 했습니다. 데이터가 충분하다고 생각해서 뒤에서 2개의 block을 trainable=True로 바꾸고, top 부분은 globalaveragePool 이후에 Dense로 Softmax를 적용했는데, 훈련이 아주 이상하게 동작하는데, 이유를 알 수 있을까요?
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, BatchNormalization, Dropout
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.utils import to_categorical, normalize
import numpy as np
import os
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
print(x_train.max(), x_train.min())
x_train = normalize(x_train)
x_test = normalize(x_test)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
print(x_train.shape, x_test.shape, y_train.shape, y_test.shape)
print(x_train.max(), x_train.min(), x_test.max(), x_test.min())
train_datagen = ImageDataGenerator(
rotation_range = 45,
width_shift_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True
)
train_datagen.fit(x_train)
train_generator = train_datagen.flow(
x_train,
y_train,
batch_size = 128)
model_vgg = VGG16(weights='imagenet', include_top=False)
for layer in model_vgg.layers:
layer.trainable = False
for layer in model_vgg.layers[-8:]:
layer.trainable = True
inputs = model_vgg.output
x = tf.keras.layers.GlobalAveragePooling2D()(inputs)
x = Dense(256, activation='relu')(x)
x = Dropout(0.3)(x)
x = Dense(128, activation='relu')(x)
x = Dropout(0.3)(x)
x = Dense(10, activation='softmax')(x)
new_model = tf.keras.models.Model(model_vgg.input, x)
new_model.summary()
from tensorflow.keras.callbacks import ReduceLROnPlateau, EarlyStopping
rlr_cb = ReduceLROnPlateau(monitor='val_loss', factor=0.3, patience=3, mode='min', verbose=1)
ely_cb = EarlyStopping(monitor='val_loss', patience=5, mode='min', verbose=1)
new_model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
history = new_model.fit_generator(train_generator,
steps_per_epoch = 391,
epochs = 100,
validation_data = (x_test, y_test),
#callbacks=[rlr_cb, ely_cb]
)답변 6
1
2021. 05. 10. 19:40
뒤에 다시 설명드릴 텐데, 일단 VGG를 적용하면 32X32 이미지크기가 최종 Feature map이 너무 작아집니다. 이미지 크기를 좀 더 키우거나 다른 pretrained 모델, augmentation을 적용하면 90%를 넘길 수 있습니다.
1
2021. 05. 10. 19:15
답을 스스로 찾으셔서 다행이군요.
to_categorical은 uint8이든, float이든 상관은 없지만, Keras model에 입력될때는 나나중에 tf.float32로 변환이 됩니다. 미리 바꿔 주셔도 되고, 자동으로 변환되도 상관없습니다.
감사합니다.
0
0
2021. 05. 10. 17:42
쫌 코드를 찾아보니, x_train의 shape가 (50000, 32, 32, 3)인데 normalize API가 기본 axis가 -1로 되어 있는데, 예제를 보니 axis=1로 맞춰야 정상적으로 정규화가 되는 것 같습니다. 그런데 255로 단순히 나누는 코드보다는 성능 차이가 있는지, val_loss가 0.1정도 차이가 나면서 시작이 됩니다
x_train = normalize(x_train, axis=1)
x_test = normalize(x_test, axis=1)
y_train = to_categorical(y_train).astype('uint8')
y_test = to_categorical(y_test).astype('uint8')to_categorical은 uint8이든, float이든 상관이 없나요?
0
2021. 05. 10. 17:39
아, 정규화를 `normalize` API를 안쓰고, 직접해봤고 런타임도 초기화해서 하니까 정상적으로 나오는 것 같습니다
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
y_train = to_categorical(y_train).astype('uint8')
y_test = to_categorical(y_test).astype('uint8')기존의 코드도 잘 돌기는 하는데, val_acc가 위 코드랑 비교했을 때 0.2정도나 차이가 납니다. colab에서 수행하느라 데이터가 꼬였는지, 무슨 이유인지는 정확히 모르겠는데 에러가 발생했네요
2021. 05. 12. 20:11
오류 유형을 딱 정해서 말씀드릴 수는 없을 것 같습니다. 전처리에서 코드를 수정해 보시고 판단하시면 될 것 같습니다. val_accuracy가 고정되어서 나오면 뭔가 코드가 잘못된것이지 모델이 문제는 아닙니다. 그 뭔가가 데이터 전처리인지 아님 다른 코드인지는 확인해 봐야 합니다.