인프런 커뮤니티 질문&답변
작성한 질문수

경사하강법 질문드립니다
작성
·
570
3
강사님 안녕하세요 ㅎㅎ 경사하강법 강의를 듣다가 잘 이해가 가지 않아 질문드립니다. 강의 5.4의 get_weight_updates 함수에서 y_pred 에서 X의 개수가 여러개고 W1이 1개인데 왜 w1.T인지 설명해주실수 있을가요?? 어차피 w1은 하나인데 전치가 필요한 이유를 잘 모르겠습니다. 안해도 괜찮나요? 그리고 w1_update와 w0_update에서는 x와 factors에서 전치행렬을 사용했기에 두가지 경우에서 전치행렬을 다르게 쓰인점이 궁금합니다!!!
답변 3
6
두번째 답변입니다.
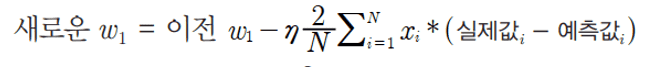
2-1. W1_update 시에는 위와 같은 식을 구하려면 X집합과 실제값 - 예측값 집합을 내적하면 구할 수 있습니다. (개별 X 데이터 원소들을 하나씩 더하고 곱하는 식을 반복할 필요 없이 한번에 내적으로 구하는 방식입니다. )
X 데이터 셋의 Shape가 (100, 1) 즉 100개의 행을 가지는 1개의 feature로 되어 있으며 실제값 -예측값 집합 역시 각 개별 X 데이터 별로 타겟값과의 차이를 나타내는 diff 변수로서 Shape가 (100, 1)입니다. 이때 X.T (즉 (1, 100)으로 Shape 변환)한 결과와 diff 를 dot 연산하면 쉽게 결과를 얻을 수 있습니다.
2-2. W0_update는 약간 복잡한데, 먼저 구하려는 식이 아래와 같이 개별 데이터들에 대한 실제값과 예측값들의 차이의 합만 계산하면 됩니다.
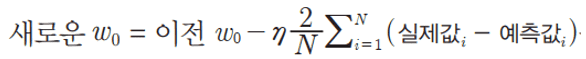
그런데 이게 오히려 선형 대수의 dot 같은 연산으로 바로 구하기가 어려워서 일부로 전체가 1의 값을 가지는 w0_factors = np.ones((100, 1)) 즉 100개의 행을 가지는 1개의 feature되어 있는 행렬을 만들고 이를 이용하여 dot 연산으로 유도하였습니다. 1에 각각 자기 원소를 곱하면 원래 자기 원소임을 이용한 것입니다.
w0_factors = np.ones((100,1))
w0_update = -(2/100)*learning_rate*(np.dot(w0_factors.T, diff))
감사합니다.
5
안녕하십니까, 그림이 들어가 있어 보시는데 불편하실수 있을거 같아 답변을 2개로 이어서 만들었습니다.
먼저 첫번째 답변입니다.
1. 예제는 1개의 Feature를 가지는 X 데이터의 건수가 100개 입니다. 따라서 X feature의 갯수가 단 한개이기에 W1도 단 한개이므로 말씀하신대로 전치행렬을 사용할 필요가 없습니다.그러나 일반적으로는 다중 선형회귀를 사용하므로 X Feature의 갯수가 여러개가 보통입니다. 만일 Feature가 m개 있다고 하면 이 경우에는 가중치는 [W1, W2, W3,,,Wm] 과 같은 벡터 형태로 표현 될 수 있는데, 이 경우에는 X feature 행렬과 가중치 벡터가 내적하여 올바른 회귀식을 도출하려면 가중치 벡터의 전치 행렬을 사용해야 합니다.이를 일반화 하기 위해서 W1.T를 적용하였습니다.
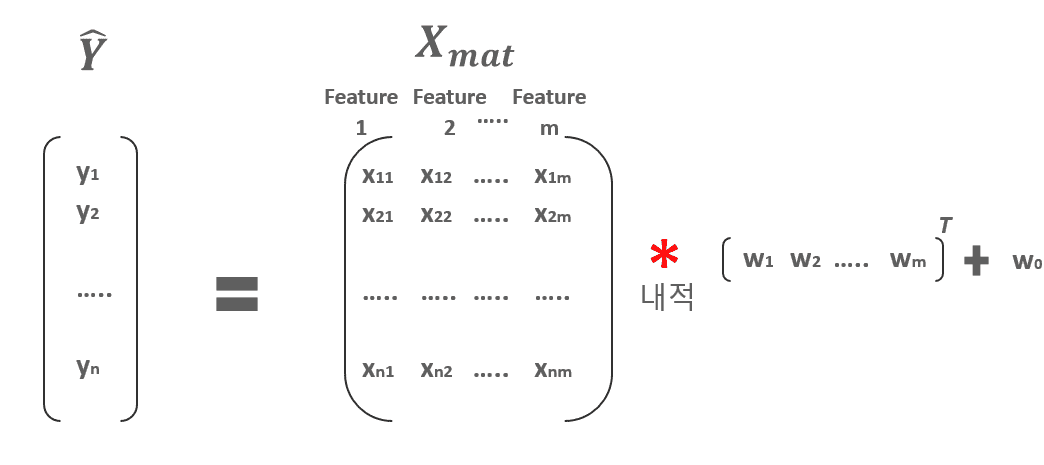
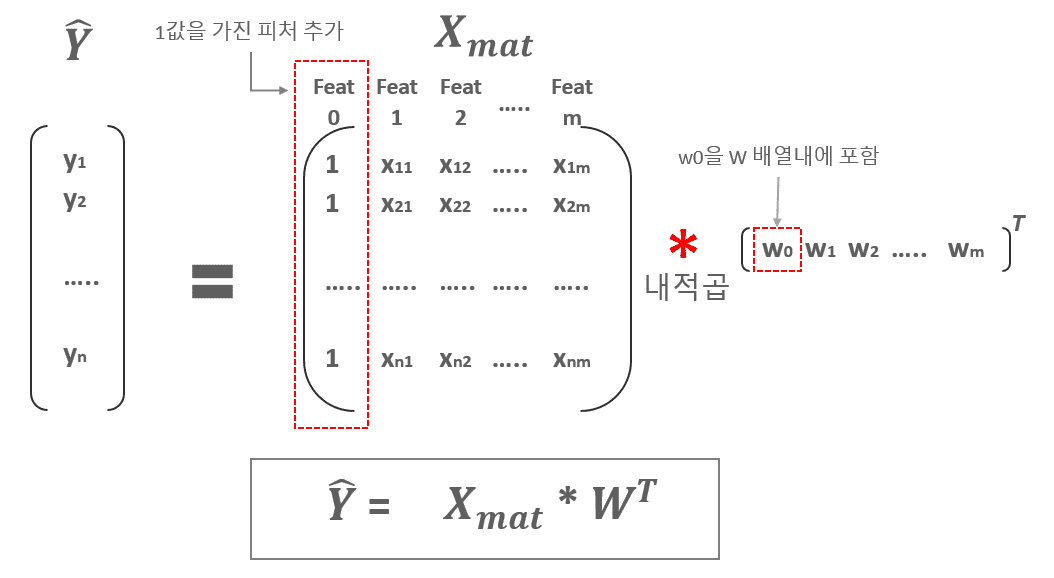
0
강사님 안녕하세요! 강의 잘 듣고있습니다.
추가로 이 답변에 대해서 질문이 있는데요.
w1의 shape이 (1,1)임에도 불구하고 전치행렬로 넣어서 y_pred를 구성하는 것은 feature가 여러개일 경우엔 w1의 shape이 달라지는 걸 고려해서 저렇게 코드를 구성하신것은 이해가 됐습니다.
그런데 w0_factors의 경우 단지 diff의 합을 구하기 위한 보조 장치(?)로서 1의 값을 가진 shape이 (N, 1)로 고정이 되어있는데
그렇다면
dot 연산을 할 때 전치행렬을 굳이 사용하지않고 애초에 w0_factors를 선언할 때 np.ones((1, N))으로 해도 되는 부분인지, 아니면 통상 코드를 구현할 때 선언을 저런식으로 하고 전치행렬로 바꿔 dot 연산을 하는 것인지 궁금합니다!