인프런 커뮤니티 질문&답변
작성한 질문수

df.hist 와 df.plot.hist의 차이
작성
·
997
1
안녕하세요 해당 강의를 수강하던 중 질문이 생겨 글 남깁니다.
data = pd.Series(np.random.randn(1000))로 데이터를 만들고
data.hist(by=np.random.randint(0, 4, 1000), figsize=(6,4)) 로 히스토그램을 작성하였을 때는 강의자료와 같이 히스토그램이 작성되는데
data.plot.hist(by=np.random.randint(0, 4, 1000), figsize=(6,4)) 로 작성하였을 때는 히스토그램이 4개가 아닌 1개로 나옵니다.
어떠한 이유로 그러한 것인지, df.hist와 df.plot.hist는 어떻게 다른 것인지 알고싶습니다.
답변 1
1
박조은
지식공유자
안녕하세요.
좋은 질문을 주셨네요.
판다스에서는 df.hist() 혹은 df.plot.hist()를 통해서 그래프를 시각화 할 수 있는데요.
같은 데이터를 가져와서 시각화를 하더라도 아래와 같은 차이가 있습니다.
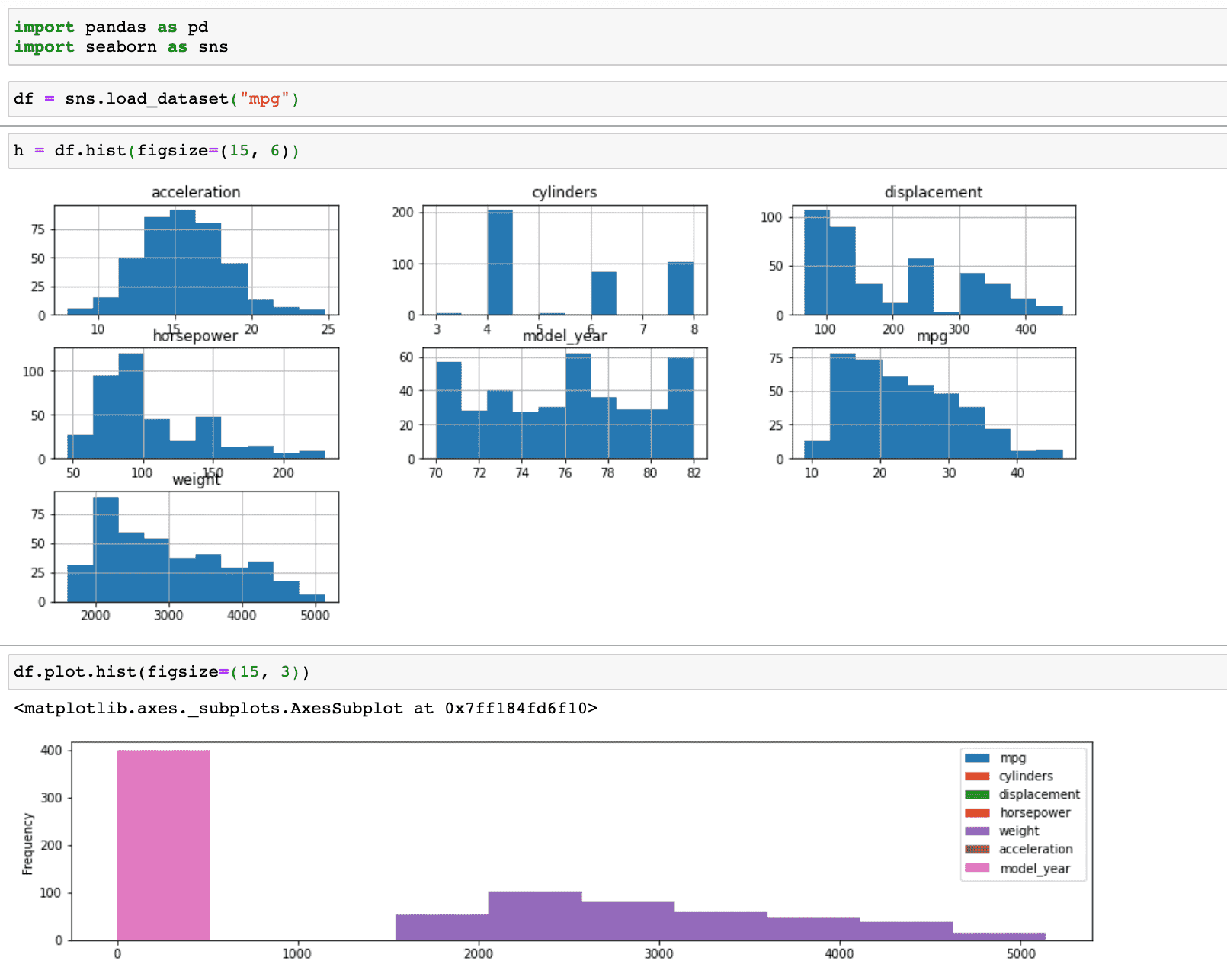
데이터프레임.hist() => 전체 수치 변수에 대한 히스토그램을 서브플롯을 그립니다.
데이터프레임.plot.hist() => 전체 수치 변수에 대한 히스토그램을 하나의 그래프에 겹쳐서 그립니다.
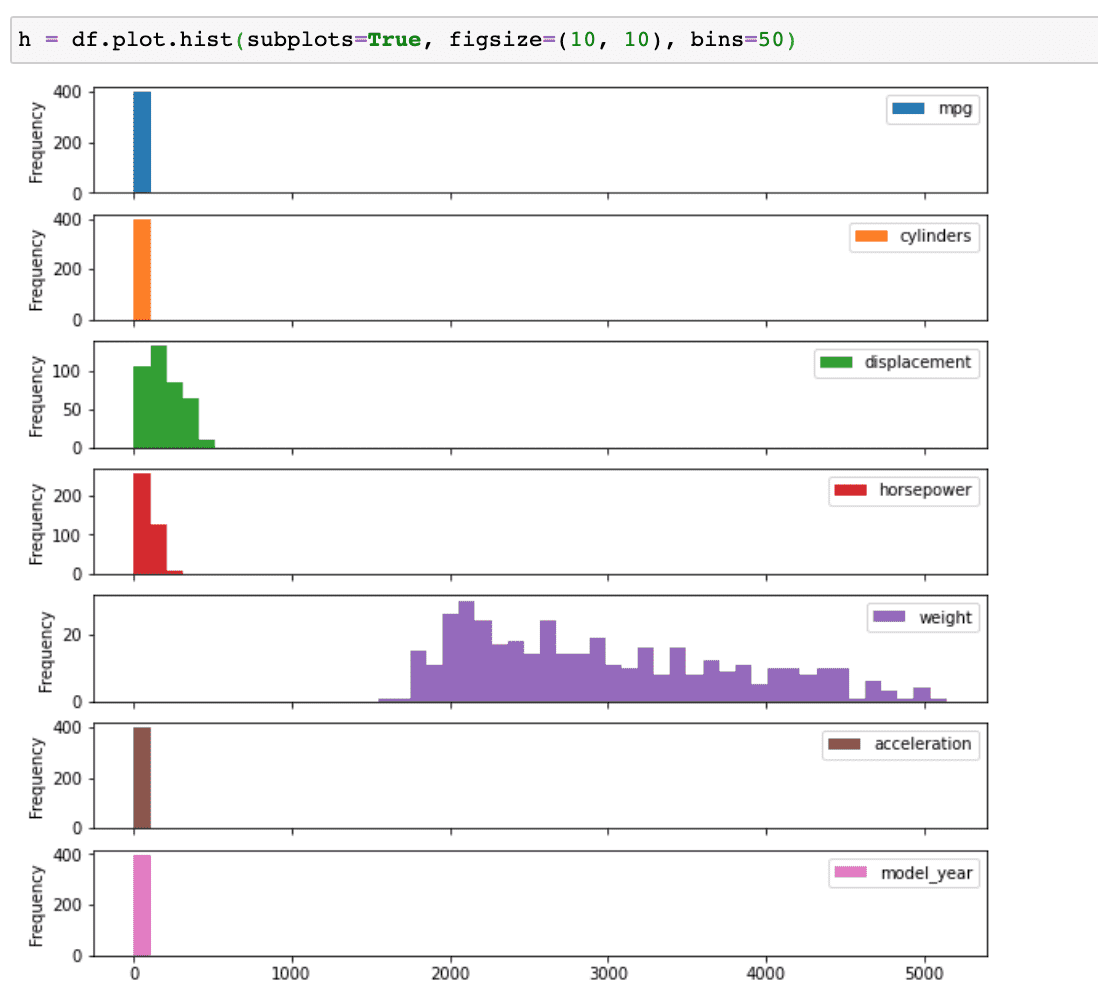
plot.hist 에서 서브플롯을 그리면 아래와 같이 그려지는데요.
이때는 x축 값이 공유되기 때문에 수치에 따라 그래프의 모양이 해석하기 어렵게 그려지기도 합니다.
그래서 데이터프레임에 대한 히스토그램은 df.hist() 사용을 권장하며,
시리즈 데이터를 바로 히스토그램으로 그리고자 할 때는 df.plot.hist()를 사용해 보세요.
물론 두 가지 모두에 df.컬럼명.hist() 이렇게 사용하셔도 됩니다.
개인적으로는 히스토그램을 겹쳐서 그리고자 할때가 아니라면 df.hist() 사용이 데이터를 읽기에 좋습니다.