인프런 커뮤니티 질문&답변
작성한 질문수

Anchor box
작성
·
495
0
좋은 강의 항상 감사합니다!!
1. 먼저 8x8으로 그리신 feature 맵에 앵커박스를 그리신 부분은 편의상 그리실 걸로 알고 있습니다. 원래대로라면, 원본이미지에 해당 feature map의 특정 포인트에 해당하는 부분을 중심으로 하고, 그걸 기준으로 anchor box 를 그리고 원본이미지에서의 object 과 IOU 를 비교하는 것이지요?
2. 그리고 bounding box regression 할 때, 학습시에는 ground truth box를 알고 있음에도 굳이 positive anchor box 와의 차이를 통해 학습을 진행하는지 궁금합니다.
앞서 드린 질문에서 저렇게 얻은 positive anchor box를 regression 을 통해 ground truth box 와 비슷하게 만드는 줄 알았는데 아니었군요 ㅠㅠ
답변 3
0
1.
RPN 네트워크 내부적으로 작동하는 것이 아니라, 학습을 위해 anchor box라는 개념을 도입해서 labelling 하고, 위치정보를 제공함으로서 RPN이 학습되게 하는 것 맞지요?!
=> 네 , 맞습니다.
2. 이 RPN loss 함수에서 t_i 는 positive anchor box의 위치정보라고 이해하면 될까요?
=> 해당 loss는 전체 anchor에 대한 것입니다. 특정 positive anchor에 대한 것은 아닙니다. 그러니까, positive anchor를 positive anchor로 잘 학습하고, negative anchor는 negative anchor로 잘 학습하게 되면 loss가 줄어드는 식으로 구성이 되어 있습니다.
0
제가 뭔가 착각하고 있었던 것 같네요....
anchor box의 효용은 RPN의 학습목표를 제시하는 것에 있었던 것 같습니다!
RPN 네트워크 내부적으로 작동하는 것이 아니라, 학습을 위해 anchor box라는 개념을 도입해서 labelling 하고, 위치정보를 제공함으로서 RPN이 학습되게 하는 것 맞지요?!
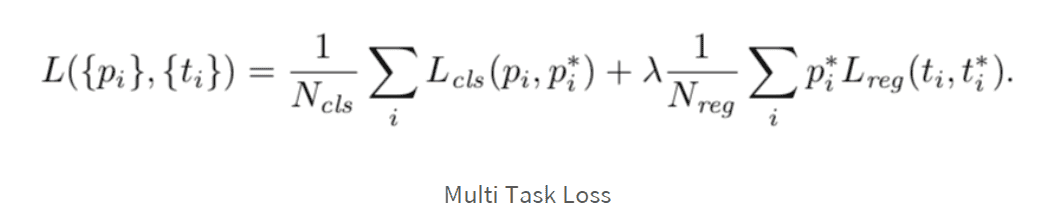
이 RPN loss 함수에서 t_i 는 positive anchor box의 위치정보라고 이해하면 될까요?
0
안녕하십니까,
1. 먼저 8x8으로 그리신 feature 맵에 앵커박스를 그리신 부분은 편의상 그리실 걸로 알고 있습니다. 원래대로라면, 원본이미지에 해당 feature map의 특정 포인트에 해당하는 부분을 중심으로 하고, 그걸 기준으로 anchor box 를 그리고 원본이미지에서의 object 과 IOU 를 비교하는 것이지요?
=> 네 맞습니다. 원본 이미지의 feature map의 positive anchor box를 이후에 원본 이미지 영역으로 매핑해서 Object와 IOU를 비교합니다.
2. 그리고 bounding box regression 할 때, 학습시에는 ground truth box를 알고 있음에도 굳이 positive anchor box 와의 차이를 통해 학습을 진행하는지 궁금합니다.
=> 앞서도 비슷한 답변을 드린것 같습니다만, anchor box가 없이 ground truth만으로 object detection은 정확한 예측을 할 수가 없습니다(deep learning 이 그렇게 까지 똑똑하지는 않습니다. ^^).
때문에 anchor box를 일정하게 설정하여서 해당 posivitive anchor box를 찾을 수 있도록 계속 학습을 합니다. RPN에서 일정부분 학습 된 anchor box 정보를 다시 메인 faster rcnn network으로 넘기면서 ground truth와 anchor box를 차이를 좁일 수 있도록 학습하는 것입니다.
object 자체의 Detection보다 더 중점적인것 가장 좋은 positive anchor를 어떻게 찾을 것일지를 학습하는 것입니다.