인프런 커뮤니티 질문&답변
작성한 질문수

인기검색종목 상승-하락 데이터 값이 안나옵니다.
21.02.04 22:32 작성
·
348
0
안녕하세요 선생님,
대학에서 자바 수업만 듣다가, 파이썬에 관심이 생겨서 넘어온 학생입니다. 파이썬을 너무 알기 쉽게 설명해주셔서 덕분에 초반부터 여기까지 빠르게 달려올 수 있었습니다.
현재 오류는 인기검색종목 상승-하락이 나오지 않는 것인데요. 다른 분께서 같은 질문을 올려주셨고, 똑같이 실행해봤지만, 오류가 나왔습니다.
<네이버 개발자 모드 - 인기검색종목의 1등 종목의 코드입니다.>

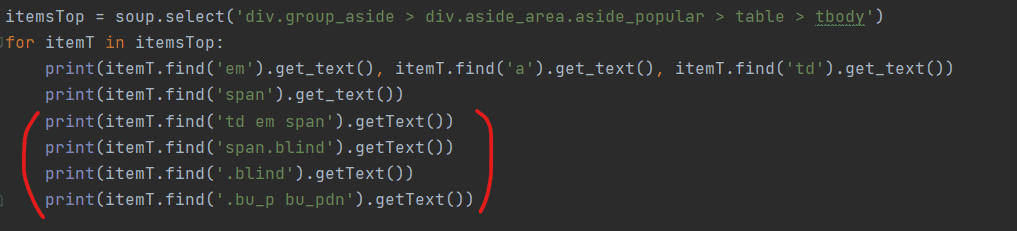
<제 코드입니다. 아래 네가지 전부 다 오류나왔습니다.>
오류를 살펴보니, getText()가 실행이 되지않는다는 이유였는데요. 제가 시도해본 아래의 네 코드 전부 값을 포함하지 않고 있었습니다. (당연히 한 줄 씩 테스트 해보았고, 한 눈에 볼 수있게 하려고 네 줄을 한번에 캡쳐하였습니다.) getText() 함수를 제외하고 실행하였을 때, 'none' 값만 나옵니다.
해외 증시 부분을 크롤링 할 때는 '상승' '하락'이 잘 나오던데, 왜 인기 검색 종목은 안나올까요?
로드맵에 있는 선생님 후속 강의를 전부 결제해둔 상태인데,
혹시 이후에 제가 강의를 더 듣다보면 알 수 있는 방법이 나올까요? 혹은, 제 코드에 오류가 있는 것일까요?
아니면 사이트가 개편되면서, 뭔가 안되는 것일까요? 😞
감사합니다.
답변 2
0
2021. 02. 05. 16:15
아.. 제가 사이트 입력을 잘못했었네요.. 정말 기초적인 실수를ㅠㅠ https://finance.naver.com/로 입력을 해서 다르게 나왔던 것 같아요. 사이트가 개선되어서 안된 건 줄 알았는데.. 해결하였습니다. 감사합니다 ^^
0
2021. 02. 05. 11:06
안녕하세요. 제 수업에서 도움을 받으셨다니 정말 좋네요.
영상에서, 설명드린 코드는 다음과 같은 것으로 이해가 됩니다. 동일한 코드로도 인기 검색 종목이 현재도 잘 나오고 있습니다. 기존 한분께서 문의주신것도, 아예 사이트가 다른 부분을 말씀해주셔서, 동일하게 답변드렸습니다.
---------------
import requests
from bs4 import BeautifulSoup
res = requests.get('https://finance.naver.com/sise/')
soup = BeautifulSoup(res.content, 'html.parser')
# a 태그이면서 href 속성 값이 특정한 값을 갖는 경우 탐색
data = soup.select("#popularItemList > li > a")
for item in data:
print (item.get_text())
-------------
해외 지수 코드도 영상에서 나온대로, 다음과 같이 작성하시면 될 것 같습니다.
---------
import requests
from bs4 import BeautifulSoup
res = requests.get('https://finance.naver.com/sise/')
soup = BeautifulSoup(res.content, 'html.parser')
data = soup.select("div.rgt > ul.lst_major > li")
for item in data:
print ("지수이름:", item.find('a').get_text(), "현재지수:", item.find('span').get_text(), item.find('em').get_text())
---------
이외에 아예 관련 코드를 주피터 노트북 형태로 관련 강의에 업로드해보았습니다.